Look Before Leap: Look-Ahead Planning with Uncertainty in Reinforcement Learning
作者: Yongshuai Liu, Xin Liu
分类: cs.LG, cs.AI
发布日期: 2025-03-26
💡 一句话要点
提出不确定性感知的模型预测控制,提升强化学习在复杂任务中的样本效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 模型预测控制 不确定性建模 主动探索 机器人操作
📋 核心要点
- 现有MBRL方法在模型不确定区域表现不佳,缺乏主动探索机制来提升模型精度。
- 论文提出一种不确定性感知的模型预测控制框架,通过前瞻规划平衡不确定性和价值。
- 实验表明,该方法在机器人操作和Atari游戏中超越了现有方法,显著提升了样本效率。
📝 摘要(中文)
基于模型的强化学习(MBRL)相比于无模型的强化学习(MFRL)展现出更高的样本效率。然而,不准确的模型会在策略学习中引入偏差,导致误导性的轨迹。由于训练数据有限且多样性不足,尤其是在访问量有限的区域(不确定区域),获得准确的模型是一项挑战。现有方法被动地在样本生成后量化不确定性,未能主动收集不确定样本以增强状态覆盖并提高模型准确性。此外,MBRL通常难以进行准确的多步预测,从而影响整体性能。为了解决这些限制,我们提出了一种新的不确定性感知策略优化框架,该框架具有基于模型的探索性规划。在基于模型的规划阶段,我们引入了一种不确定性感知的k步前瞻规划方法来指导每一步的动作选择。这个过程涉及模型不确定性和价值函数近似误差之间的权衡分析,有效地提高了策略性能。在策略优化阶段,我们利用不确定性驱动的探索性策略来主动收集多样化的训练样本,从而提高模型准确性和RL Agent的整体性能。我们的方法为具有不同状态/动作空间和奖励结构的任务提供了灵活性和适用性。我们通过具有挑战性的机器人操作任务和Atari游戏中的实验验证了其有效性,以更少的交互次数超越了最先进的方法,从而实现了显著的性能改进。
🔬 方法详解
问题定义:现有的基于模型的强化学习方法,在模型不确定性较高的区域,由于模型偏差,会导致策略学习出现偏差,从而影响最终的性能。尤其是在数据稀疏的区域,模型难以准确预测状态转移,进而影响策略的有效性。现有方法通常是被动地评估不确定性,而缺乏主动探索机制来改善模型在不确定区域的精度。
核心思路:论文的核心思路是利用不确定性信息来指导策略的学习和探索。通过在模型预测控制中引入不确定性感知的前瞻规划,Agent能够主动选择那些能够降低模型不确定性的动作,从而改善模型精度。同时,在策略优化阶段,利用不确定性驱动的探索性策略,鼓励Agent探索未知的状态空间,收集更多样化的数据。
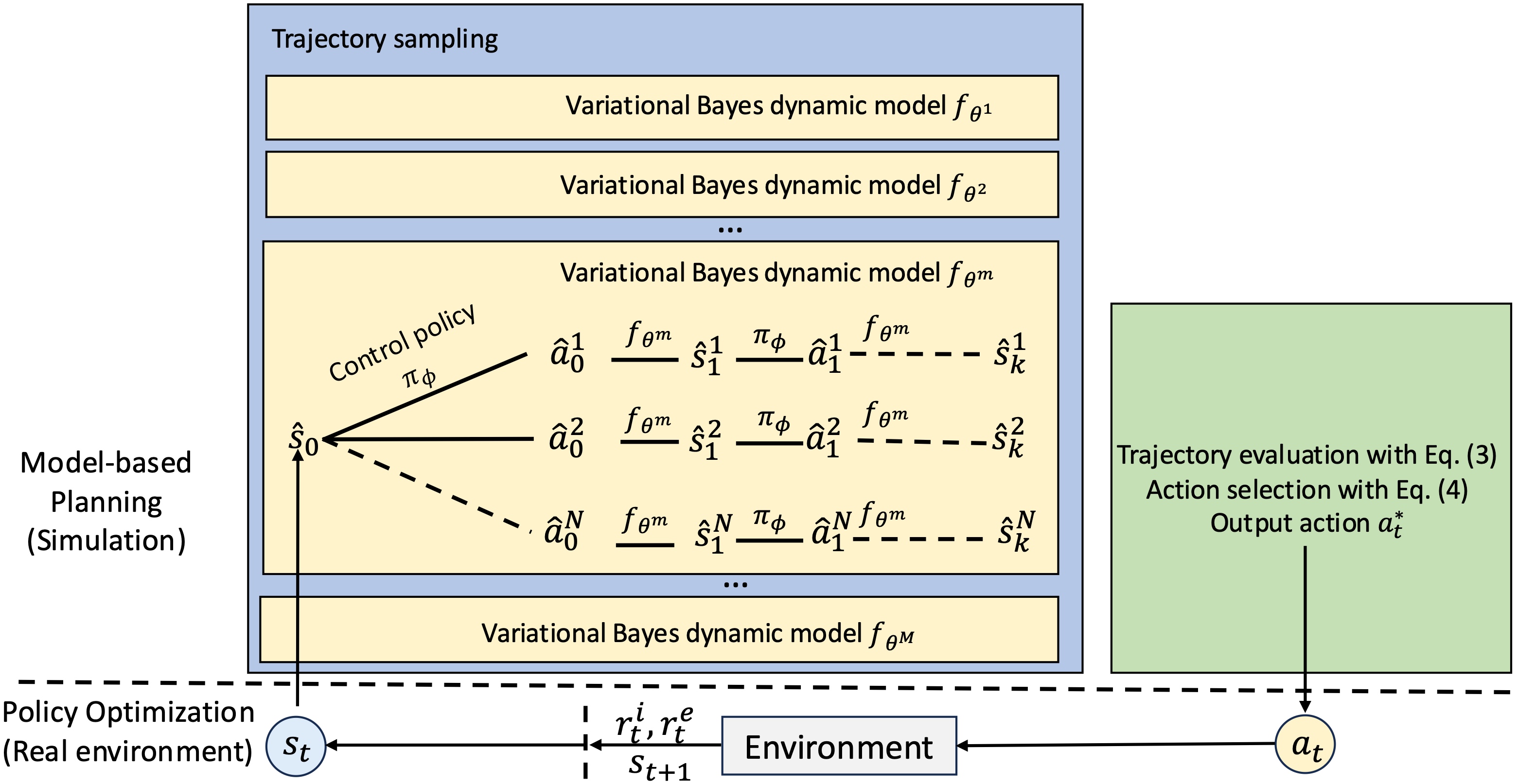
技术框架:该框架包含两个主要阶段:基于模型的规划阶段和策略优化阶段。在规划阶段,使用不确定性感知的k步前瞻规划方法,Agent在每一步选择动作时,会权衡模型的不确定性和价值函数的近似误差。在策略优化阶段,利用收集到的数据更新模型和策略,并使用不确定性驱动的探索性策略来收集新的训练样本。整体流程是一个迭代的过程,通过不断地探索和学习,Agent能够逐步提高模型精度和策略性能。
关键创新:该论文的关键创新在于将不确定性信息融入到模型预测控制和策略探索中。传统方法通常只关注价值函数的优化,而忽略了模型的不确定性。该论文通过显式地建模和利用不确定性,使得Agent能够更加智能地进行探索和学习。此外,不确定性驱动的探索性策略也是一个重要的创新点,它能够有效地引导Agent探索未知的状态空间。
关键设计:在不确定性感知的k步前瞻规划中,需要定义一个合适的指标来衡量模型的不确定性。论文中可能使用了例如模型预测方差或者集成模型的差异性等指标。此外,还需要设计一个合适的损失函数来平衡模型不确定性和价值函数近似误差。在策略优化阶段,需要设计一个不确定性驱动的探索性策略,例如可以使用ε-greedy策略,并根据模型的不确定性动态调整ε的值。具体的网络结构和参数设置需要根据具体的任务进行调整。
🖼️ 关键图片
📊 实验亮点
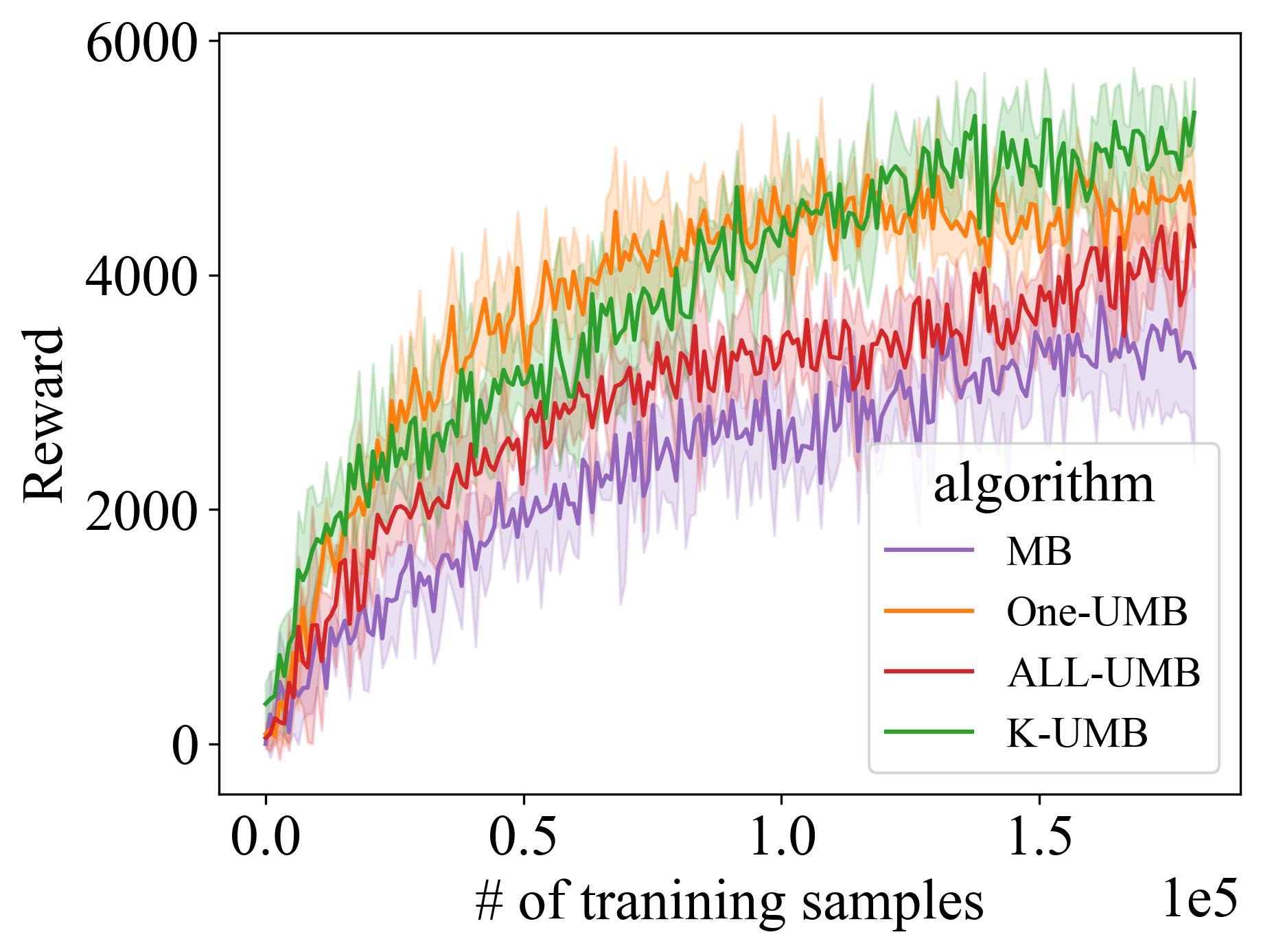
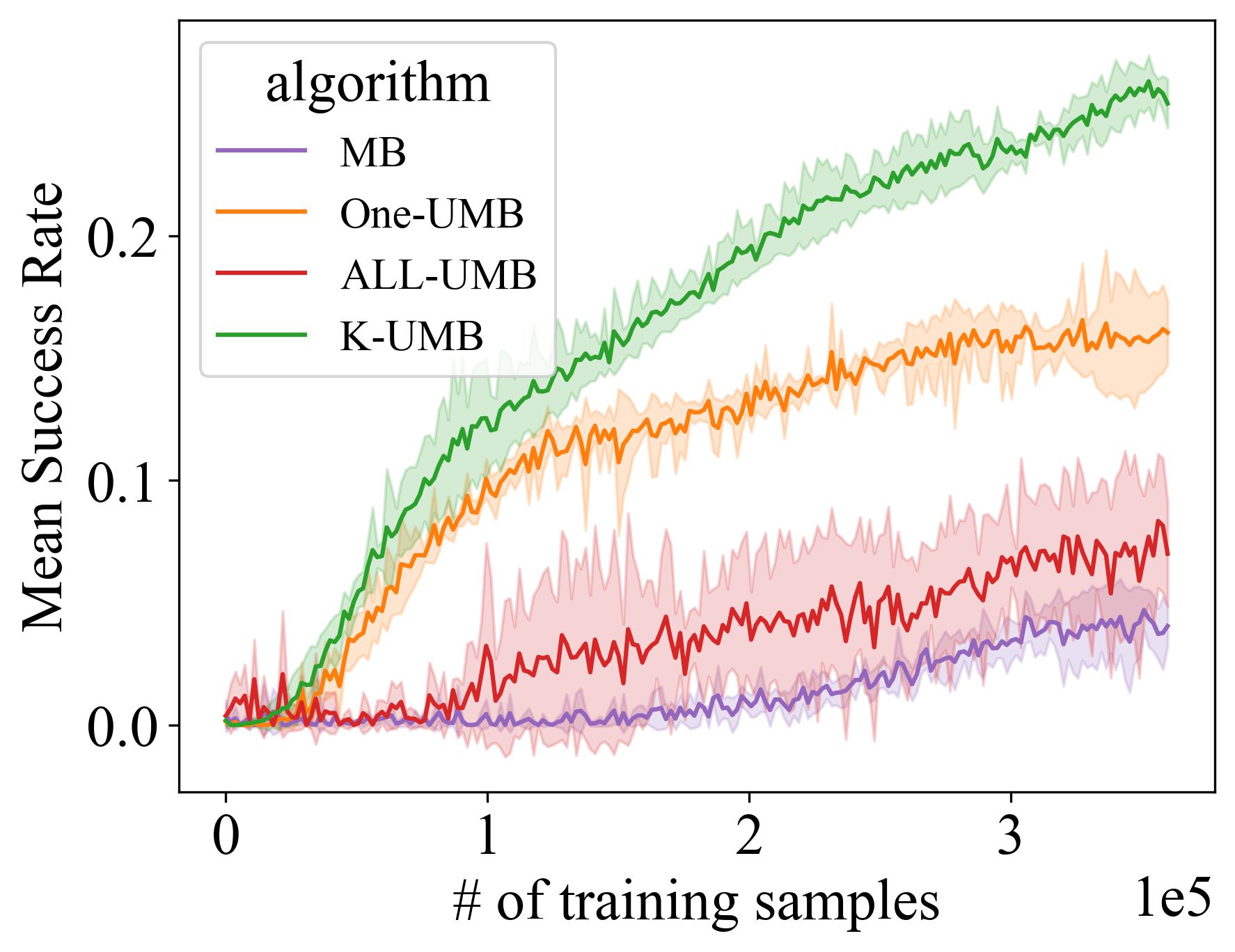
实验结果表明,该方法在具有挑战性的机器人操作任务和Atari游戏中,以更少的交互次数超越了现有最先进的方法。具体的性能提升幅度未知,但摘要强调了“显著的性能改进”,表明该方法在样本效率和最终性能上均有明显优势。该方法通过主动探索不确定区域,有效提升了模型的准确性和策略的泛化能力。
🎯 应用场景
该研究成果可应用于机器人操作、自动驾驶、游戏AI等领域。通过提升强化学习的样本效率和鲁棒性,可以降低训练成本,加速算法落地。尤其是在环境复杂、数据稀疏的场景下,该方法具有重要的应用价值。未来,该方法有望应用于更广泛的实际问题,例如智能制造、医疗诊断等。
📄 摘要(原文)
Model-based reinforcement learning (MBRL) has demonstrated superior sample efficiency compared to model-free reinforcement learning (MFRL). However, the presence of inaccurate models can introduce biases during policy learning, resulting in misleading trajectories. The challenge lies in obtaining accurate models due to limited diverse training data, particularly in regions with limited visits (uncertain regions). Existing approaches passively quantify uncertainty after sample generation, failing to actively collect uncertain samples that could enhance state coverage and improve model accuracy. Moreover, MBRL often faces difficulties in making accurate multi-step predictions, thereby impacting overall performance. To address these limitations, we propose a novel framework for uncertainty-aware policy optimization with model-based exploratory planning. In the model-based planning phase, we introduce an uncertainty-aware k-step lookahead planning approach to guide action selection at each step. This process involves a trade-off analysis between model uncertainty and value function approximation error, effectively enhancing policy performance. In the policy optimization phase, we leverage an uncertainty-driven exploratory policy to actively collect diverse training samples, resulting in improved model accuracy and overall performance of the RL agent. Our approach offers flexibility and applicability to tasks with varying state/action spaces and reward structures. We validate its effectiveness through experiments on challenging robotic manipulation tasks and Atari games, surpassing state-of-the-art methods with fewer interactions, thereby leading to significant performance improvements.