LayerCraft: Enhancing Text-to-Image Generation with CoT Reasoning and Layered Object Integration
作者: Yuyao Zhang, Jinghao Li, Yu-Wing Tai
分类: cs.LG, cs.GR, cs.MA
发布日期: 2025-03-25 (更新: 2025-10-17)
备注: 26 pages
🔗 代码/项目: GITHUB
💡 一句话要点
LayerCraft:利用CoT推理和分层对象集成增强文本到图像生成
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到图像生成 思维链推理 分层对象集成 大型语言模型 图像编辑
📋 核心要点
- 现有文本到图像生成方法在空间布局控制、对象一致性以及多步骤编辑方面存在不足。
- LayerCraft利用大型语言模型进行CoT推理,实现场景分解和对象布局规划,从而实现结构化图像生成。
- LayerCraft提出对象集成网络,允许用户在不同图像中插入和定制对象,同时保持对象身份和风格。
📝 摘要(中文)
文本到图像(T2I)生成取得了显著进展,但现有系统仍然缺乏对空间组合、对象一致性和多步骤编辑的直观控制。我们提出了LayerCraft,一个模块化框架,它使用大型语言模型(LLMs)作为自主代理来协调结构化的、分层的图像生成和编辑。LayerCraft支持两个关键功能:(1)通过思维链(CoT)推理从简单提示进行结构化生成,使其能够分解场景,推理对象放置,并以可控、可解释的方式指导组合;(2)分层对象集成,允许用户在不同的图像或场景中插入和自定义对象(如角色或道具),同时保持身份、上下文和风格。该系统包括一个协调代理ChainArchitect,用于CoT驱动的布局规划,以及对象集成网络(OIN),用于使用现成的T2I模型进行无缝图像编辑,而无需重新训练。通过批量拼贴编辑和叙事场景生成等应用,LayerCraft使非专业人士能够以最少的人工工作量迭代地设计、定制和改进视觉内容。
🔬 方法详解
问题定义:现有文本到图像生成模型难以精确控制图像的空间布局和对象之间的关系,尤其是在复杂场景下。用户难以对生成结果进行精细化编辑,例如在保持对象身份和风格的前提下,将特定对象插入到不同的场景中。现有方法通常需要大量训练数据或针对特定场景进行微调,泛化能力有限。
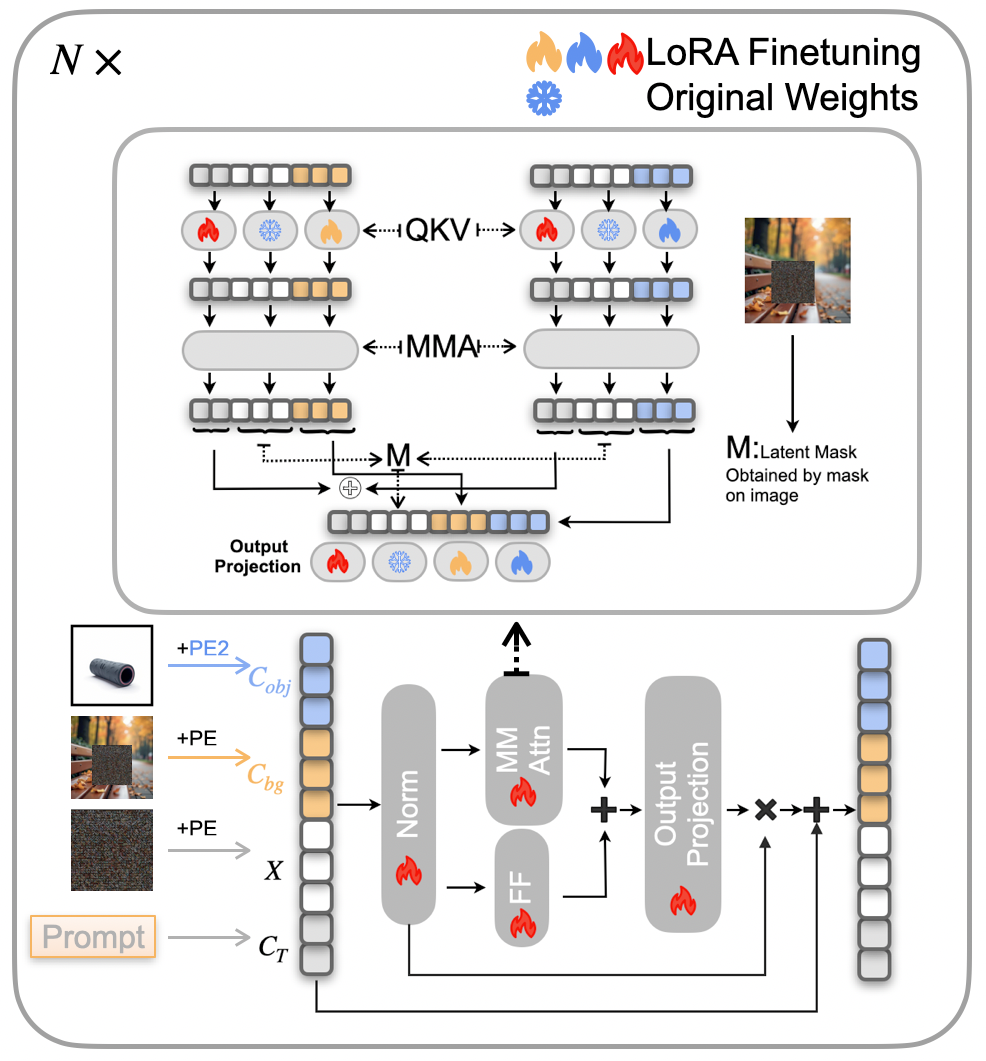
核心思路:LayerCraft的核心思路是利用大型语言模型(LLMs)的推理能力,将复杂的图像生成任务分解为多个可控的子任务。通过思维链(CoT)推理,LLM可以逐步规划场景布局,确定对象的位置和属性。此外,LayerCraft还引入了对象集成网络(OIN),用于将用户指定的对象无缝地融入到目标图像中,同时保持对象的一致性和风格。
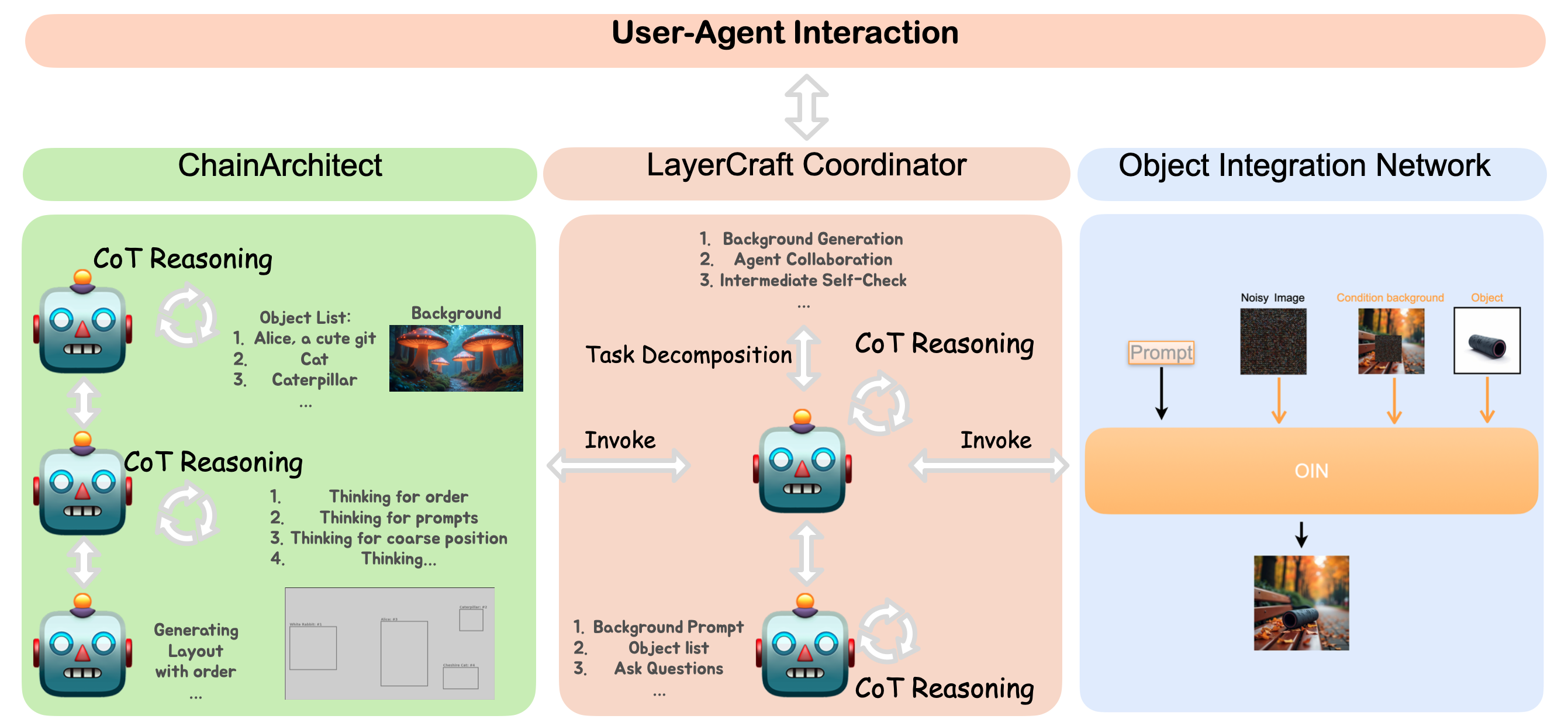
技术框架:LayerCraft包含三个主要模块:协调代理、ChainArchitect和对象集成网络(OIN)。协调代理负责接收用户指令,并将任务分配给ChainArchitect和OIN。ChainArchitect利用LLM进行CoT推理,生成场景布局方案。OIN则负责将用户指定的对象集成到目标图像中,并进行必要的调整以保证视觉一致性。整个流程是迭代式的,用户可以根据生成结果进行反馈,并对布局和对象进行调整。
关键创新:LayerCraft的关键创新在于将LLM的推理能力与图像生成模型相结合,实现了对图像生成过程的精细化控制。通过CoT推理,系统可以理解用户意图,并生成符合用户要求的图像。OIN的引入使得用户可以轻松地将自定义对象插入到图像中,而无需重新训练模型。这种模块化的设计使得LayerCraft具有很强的灵活性和可扩展性。
关键设计:ChainArchitect使用预训练的LLM,并针对图像生成任务进行了微调。OIN采用了一种基于注意力机制的网络结构,可以自适应地调整对象的位置、大小和颜色,以保证与目标图像的视觉一致性。损失函数包括内容损失、风格损失和一致性损失,用于约束生成结果的质量。
🖼️ 关键图片
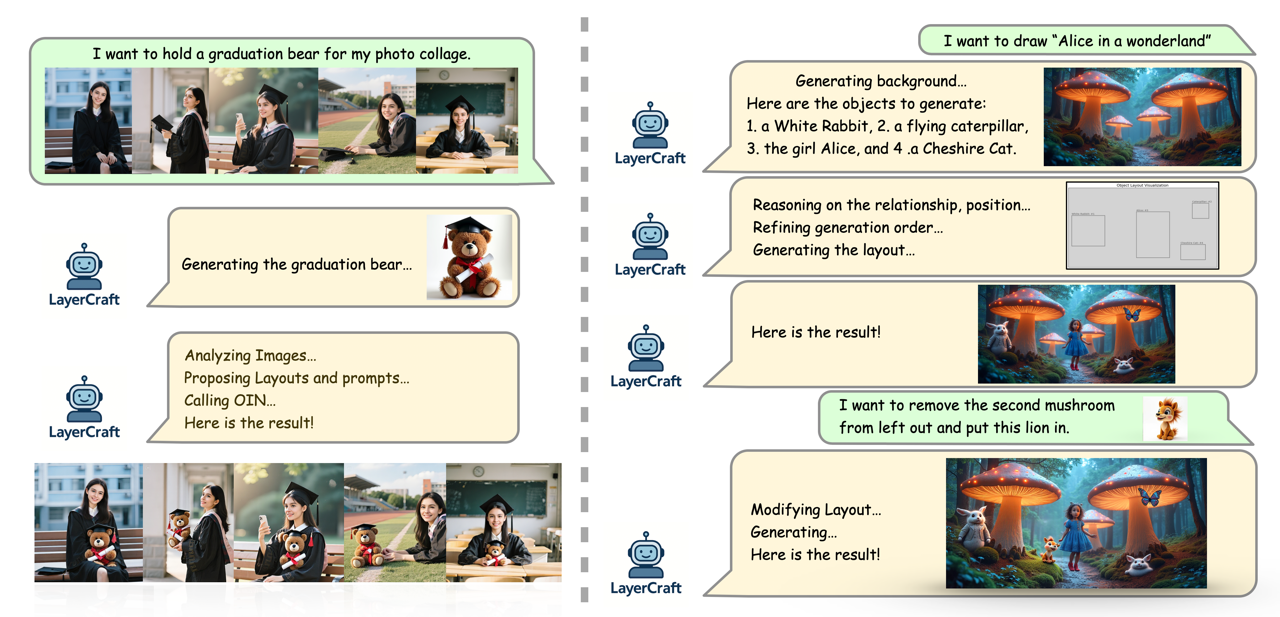
📊 实验亮点
LayerCraft通过CoT推理实现了对图像布局的精确控制,并在对象集成方面取得了显著效果。实验结果表明,LayerCraft可以生成具有更高质量和更好一致性的图像,并且用户可以轻松地将自定义对象插入到图像中。相较于现有方法,LayerCraft在图像质量和用户可控性方面均有明显提升。具体性能数据未知。
🎯 应用场景
LayerCraft可应用于多种场景,例如批量拼贴编辑、叙事场景生成、虚拟角色定制等。该系统可以帮助非专业人士轻松创建高质量的视觉内容,并提高图像编辑的效率。未来,LayerCraft可以扩展到视频生成领域,实现对视频内容的精细化编辑和控制。
📄 摘要(原文)
Text-to-image (T2I) generation has made remarkable progress, yet existing systems still lack intuitive control over spatial composition, object consistency, and multi-step editing. We present $\textbf{LayerCraft}$, a modular framework that uses large language models (LLMs) as autonomous agents to orchestrate structured, layered image generation and editing. LayerCraft supports two key capabilities: (1) $\textit{structured generation}$ from simple prompts via chain-of-thought (CoT) reasoning, enabling it to decompose scenes, reason about object placement, and guide composition in a controllable, interpretable manner; and (2) $\textit{layered object integration}$, allowing users to insert and customize objects -- such as characters or props -- across diverse images or scenes while preserving identity, context, and style. The system comprises a coordinator agent, the $\textbf{ChainArchitect}$ for CoT-driven layout planning, and the $\textbf{Object Integration Network (OIN)}$ for seamless image editing using off-the-shelf T2I models without retraining. Through applications like batch collage editing and narrative scene generation, LayerCraft empowers non-experts to iteratively design, customize, and refine visual content with minimal manual effort. Code will be released at https://github.com/PeterYYZhang/LayerCraft.