LERO: LLM-driven Evolutionary framework with Hybrid Rewards and Enhanced Observation for Multi-Agent Reinforcement Learning
作者: Yuan Wei, Xiaohan Shan, Jianmin Li
分类: cs.LG, cs.AI, cs.MA
发布日期: 2025-03-25
💡 一句话要点
LERO:基于LLM驱动的演化框架,通过混合奖励和增强观测提升多智能体强化学习性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多智能体强化学习 大型语言模型 演化算法 信用分配 部分可观测性
📋 核心要点
- 多智能体强化学习在信用分配和部分可观测性方面存在挑战,限制了其在复杂合作任务中的应用。
- LERO利用LLM生成混合奖励函数和观测增强函数,并通过演化算法优化,以解决信用分配和部分可观测问题。
- 实验表明,LERO在多智能体粒子环境中显著提升了任务性能和训练效率,优于现有基线方法。
📝 摘要(中文)
多智能体强化学习(MARL)面临着与单智能体强化学习不同的两个关键瓶颈:合作任务中的信用分配和环境状态的部分可观测性。我们提出了LERO,一个集成了大型语言模型(LLM)和演化优化的框架,以解决这些MARL特有的挑战。该解决方案的核心是两个由LLM生成的部分:一个通过奖励分解动态分配个体信用的混合奖励函数,以及一个通过推断环境上下文来增强部分观测的观测增强函数。演化算法通过迭代MARL训练周期来优化这些组件,其中表现最佳的候选者指导后续的LLM生成。在多智能体粒子环境(MPE)中的评估表明,LERO优于基线方法,具有改进的任务性能和训练效率。
🔬 方法详解
问题定义:多智能体强化学习在合作任务中面临信用分配难题,即如何将团队奖励有效地分配给各个智能体。此外,环境的部分可观测性使得智能体难以获得全局信息,影响决策质量。现有方法在处理这些问题时存在不足,例如奖励稀疏、信息缺失等。
核心思路:LERO的核心思路是利用大型语言模型(LLM)的强大生成能力,自动设计有效的奖励函数和观测增强策略。通过演化算法迭代优化LLM生成的组件,使其更好地适应特定任务,从而提升多智能体强化学习的性能。
技术框架:LERO框架包含以下主要模块:1) LLM:用于生成混合奖励函数和观测增强函数;2) 演化算法:用于优化LLM生成的组件,选择表现最佳的候选者;3) MARL训练:使用演化算法选择的奖励函数和观测增强函数训练多智能体策略;4) 评估:评估MARL训练后的策略性能,并将结果反馈给演化算法。整个流程通过迭代训练和评估,不断优化奖励函数和观测增强函数。
关键创新:LERO的关键创新在于将LLM与演化算法相结合,自动设计和优化MARL中的关键组件。与传统的手工设计方法相比,LERO能够更有效地探索奖励函数和观测增强策略的空间,找到更适合特定任务的解决方案。此外,混合奖励函数和观测增强函数的设计也考虑了MARL的特殊性,例如信用分配和部分可观测性。
关键设计:混合奖励函数通过奖励分解动态分配个体信用,具体实现方式未知。观测增强函数通过推断环境上下文来增强部分观测,具体实现方式未知。演化算法的具体参数设置未知。损失函数和网络结构的选择可能依赖于具体的MARL算法。
🖼️ 关键图片


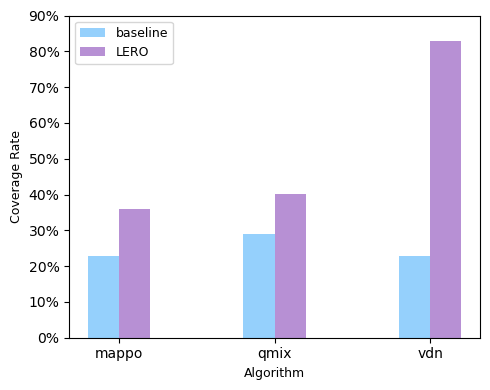
📊 实验亮点
LERO在多智能体粒子环境(MPE)中进行了评估,实验结果表明,LERO在任务性能和训练效率方面均优于基线方法。具体的性能数据和提升幅度在论文中给出,但此处未提供。
🎯 应用场景
LERO框架具有广泛的应用前景,例如在自动驾驶、机器人协作、资源分配等领域。通过自动设计奖励函数和观测增强策略,LERO可以降低MARL的应用门槛,加速其在实际场景中的部署。未来,LERO可以进一步扩展到更复杂的任务和环境,例如涉及非合作博弈和动态环境的任务。
📄 摘要(原文)
Multi-agent reinforcement learning (MARL) faces two critical bottlenecks distinct from single-agent RL: credit assignment in cooperative tasks and partial observability of environmental states. We propose LERO, a framework integrating Large language models (LLMs) with evolutionary optimization to address these MARL-specific challenges. The solution centers on two LLM-generated components: a hybrid reward function that dynamically allocates individual credit through reward decomposition, and an observation enhancement function that augments partial observations with inferred environmental context. An evolutionary algorithm optimizes these components through iterative MARL training cycles, where top-performing candidates guide subsequent LLM generations. Evaluations in Multi-Agent Particle Environments (MPE) demonstrate LERO's superiority over baseline methods, with improved task performance and training efficiency.