ExCoT: Optimizing Reasoning for Text-to-SQL with Execution Feedback
作者: Bohan Zhai, Canwen Xu, Yuxiong He, Zhewei Yao
分类: cs.LG, cs.AI, cs.DB
发布日期: 2025-03-25
💡 一句话要点
ExCoT:利用执行反馈优化Text-to-SQL的推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text-to-SQL 大型语言模型 思维链 直接偏好优化 执行反馈 迭代优化 数据库查询
📋 核心要点
- 现有Text-to-SQL方法在利用LLM的CoT推理能力方面存在不足,零样本CoT增益小,DPO改进有限。
- ExCoT框架结合CoT推理与离策略和在策略DPO,迭代优化LLM,仅使用执行准确性作为反馈信号。
- 实验表明,ExCoT显著提升了LLaMA-3 70B和Qwen-2.5-Coder在BIRD和Spider数据集上的执行准确率,达到SOTA。
📝 摘要(中文)
Text-to-SQL需要精确的推理才能将自然语言问题转换为结构化查询。虽然大型语言模型(LLMs)在许多推理任务中表现出色,但它们利用思维链(CoT)推理进行text-to-SQL的能力仍未得到充分探索。我们发现关键限制:零样本CoT提供的增益最小,并且在没有CoT的情况下应用直接偏好优化(DPO)产生的改进微乎其微。我们提出了ExCoT,这是一个新颖的框架,通过结合CoT推理与离策略和在策略DPO,迭代地优化开源LLM,仅依赖于执行准确性作为反馈。这种方法消除了对奖励模型或人工标注偏好的需求。我们的实验结果表明了显着的性能提升:ExCoT将LLaMA-3 70B在BIRD开发集上的执行准确率从57.37%提高到68.51%,在Spider测试集上从78.81%提高到86.59%,Qwen-2.5-Coder也表现出类似的改进。我们最好的模型在BIRD和Spider数据集的单模型设置中均实现了最先进的性能,特别是在BIRD测试集上达到了68.53%。
🔬 方法详解
问题定义:论文旨在解决Text-to-SQL任务中,大型语言模型(LLMs)利用思维链(CoT)推理能力不足的问题。现有方法,如零样本CoT和直接偏好优化(DPO),在Text-to-SQL任务上的提升效果有限,无法充分发挥LLM的推理潜力。
核心思路:论文的核心思路是结合CoT推理与离策略和在策略DPO,并使用执行准确性作为唯一的反馈信号,迭代优化LLM。通过CoT增强推理过程,DPO优化模型偏好,执行准确性提供直接的监督信号,从而提升Text-to-SQL的性能。
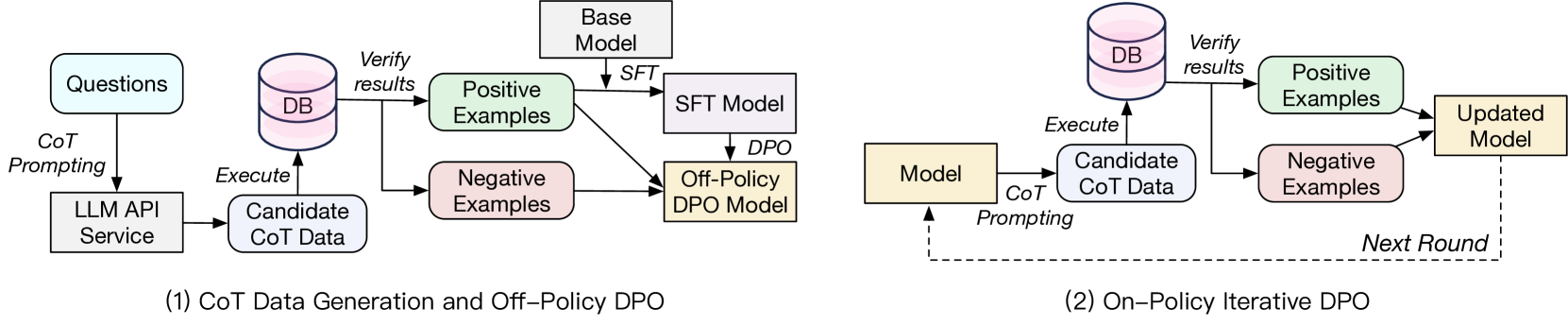
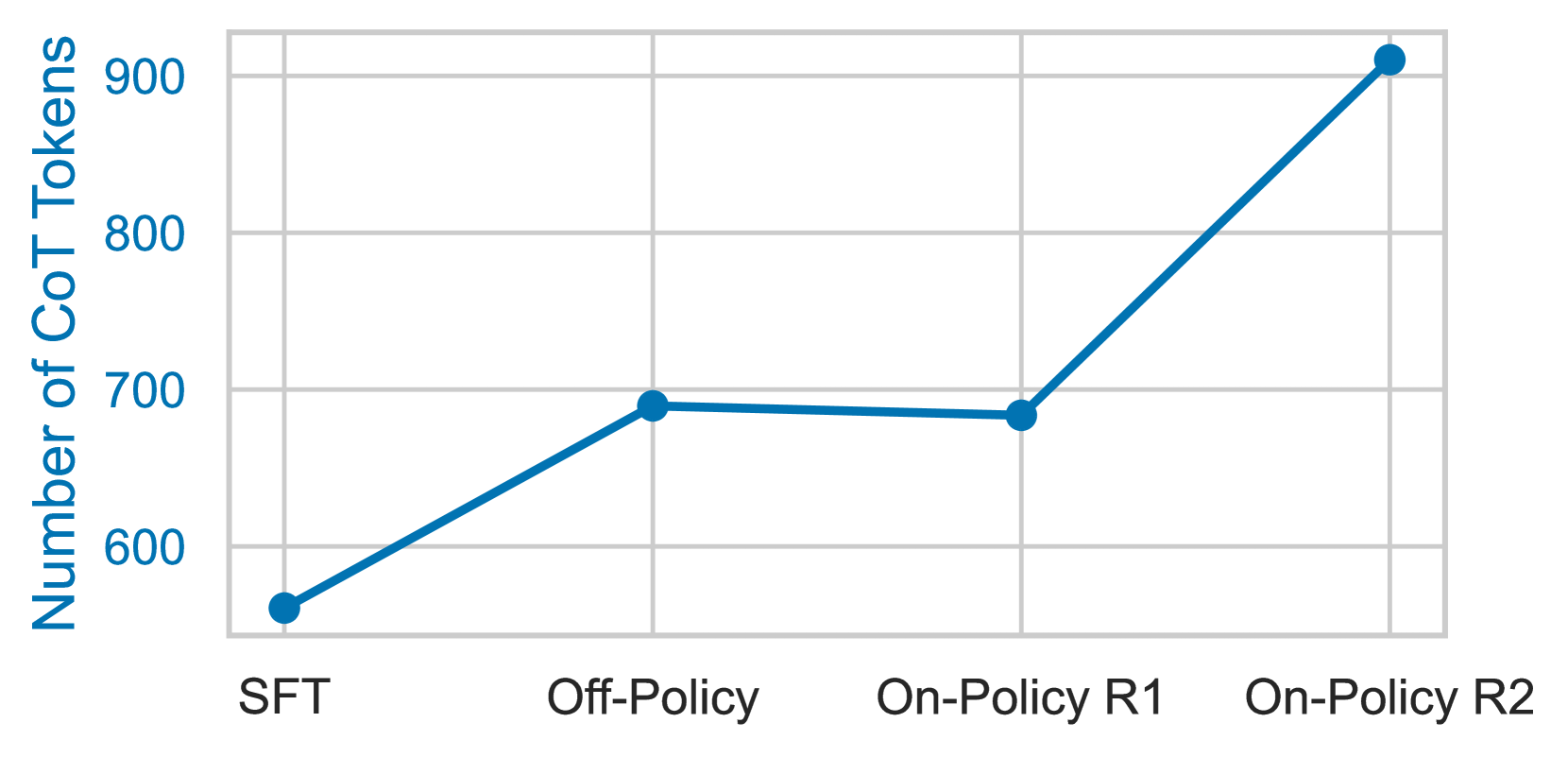
技术框架:ExCoT框架包含以下主要阶段:1) CoT推理生成:LLM根据输入文本生成CoT推理过程,将问题分解为多个步骤。2) SQL生成:基于CoT推理过程,LLM生成对应的SQL查询语句。3) 执行反馈:执行生成的SQL查询,获取执行结果的准确性作为反馈信号。4) 离策略DPO:利用历史数据和执行反馈,优化LLM的策略。5) 在策略DPO:利用当前策略生成的数据和执行反馈,进一步优化LLM的策略。通过迭代执行这些步骤,不断提升LLM的Text-to-SQL能力。
关键创新:ExCoT最重要的技术创新点在于,它仅使用执行准确性作为反馈信号,无需人工标注的偏好数据或奖励模型。这大大降低了训练成本和复杂性,使得可以更方便地利用大规模数据进行模型优化。此外,结合CoT推理和DPO,能够更有效地利用LLM的推理能力,提升Text-to-SQL的性能。
关键设计:ExCoT的关键设计包括:1) CoT推理过程的设计,需要保证推理过程的正确性和完整性。2) DPO的损失函数设计,需要平衡探索和利用,避免模型陷入局部最优。3) 离策略和在策略DPO的结合,可以充分利用历史数据和当前数据,加速模型收敛。4) 执行准确性的计算方式,需要考虑数据库的特性和查询的复杂性。
🖼️ 关键图片
📊 实验亮点
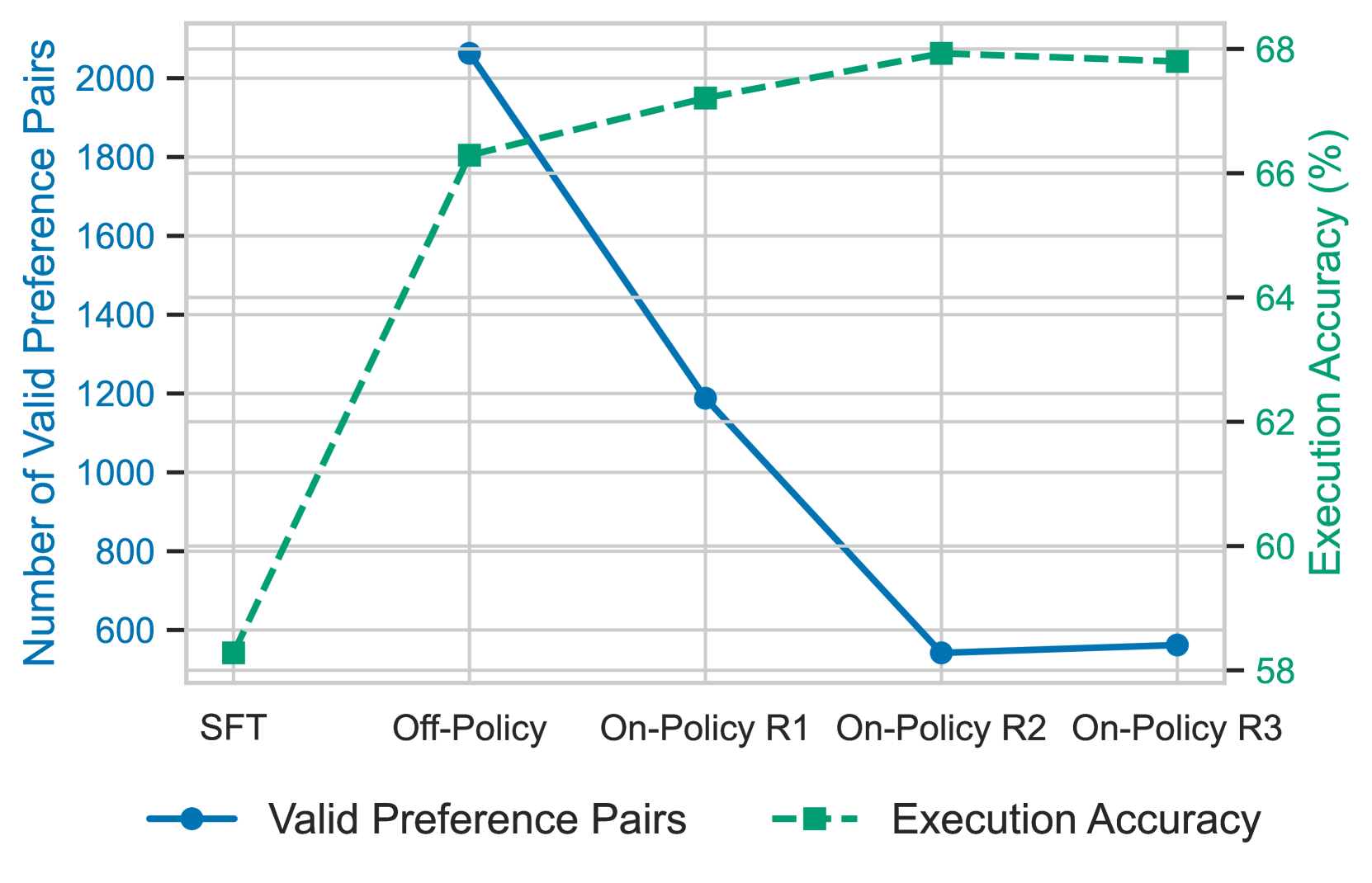
ExCoT在BIRD开发集上将LLaMA-3 70B的执行准确率从57.37%提高到68.51%,在Spider测试集上从78.81%提高到86.59%。Qwen-2.5-Coder也表现出类似的改进。最佳模型在BIRD测试集上达到了68.53%的准确率,在BIRD和Spider数据集的单模型设置中均实现了最先进的性能,显著超越了现有方法。
🎯 应用场景
ExCoT框架可应用于各种需要将自然语言转换为结构化查询的场景,例如智能客服、数据分析、商业智能等。通过提升Text-to-SQL的准确性和效率,可以帮助用户更方便地从数据库中获取所需信息,提高工作效率和决策质量。未来,该技术有望进一步扩展到更复杂的数据库查询和数据分析任务中。
📄 摘要(原文)
Text-to-SQL demands precise reasoning to convert natural language questions into structured queries. While large language models (LLMs) excel in many reasoning tasks, their ability to leverage Chain-of-Thought (CoT) reasoning for text-to-SQL remains underexplored. We identify critical limitations: zero-shot CoT offers minimal gains, and Direct Preference Optimization (DPO) applied without CoT yields marginal improvements. We propose ExCoT, a novel framework that iteratively optimizes open-source LLMs by combining CoT reasoning with off-policy and on-policy DPO, relying solely on execution accuracy as feedback. This approach eliminates the need for reward models or human-annotated preferences. Our experimental results demonstrate significant performance gains: ExCoT improves execution accuracy on BIRD dev set from 57.37% to 68.51% and on Spider test set from 78.81% to 86.59% for LLaMA-3 70B, with Qwen-2.5-Coder demonstrating similar improvements. Our best model achieves state-of-the-art performance in the single-model setting on both BIRD and Spider datasets, notably achieving 68.53% on the BIRD test set.