Data-centric Federated Graph Learning with Large Language Models
作者: Bo Yan, Zhongjian Zhang, Huabin Sun, Mengmei Zhang, Yang Cao, Chuan Shi
分类: cs.LG, cs.AI
发布日期: 2025-03-25
备注: ongoing work
💡 一句话要点
提出LLM4FGL框架,利用大语言模型解决联邦图学习中的数据异构性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦图学习 大语言模型 数据异构性 图数据增强 联邦学习
📋 核心要点
- 联邦图学习面临数据异构性挑战,现有方法侧重于模型层面,难以泛化到新任务。
- LLM4FGL框架利用大语言模型增强局部图数据,通过联邦生成和反思机制提升生成节点质量。
- 实验表明,LLM4FGL优于现有联邦图学习方法,可作为插件集成到现有框架中。
📝 摘要(中文)
在联邦图学习(FGL)中,由于隐私问题,完整的图被分割成存储在每个客户端的多个子图,所有客户端仅通过传输模型参数来联合训练全局图模型。FGL的一个痛点是异构性问题,其中节点或结构在客户端之间呈现非独立同分布(non-IID)的性质(例如,不同的节点标签分布),极大地损害了FGL的收敛性和性能。为了解决这个问题,现有的工作主要集中在模型层面的设计策略上,即设计模型来提取共同知识以减轻异构性。然而,这些模型层面的策略未能从根本上解决异构性问题,因为当转移到其他任务时,模型需要从头开始设计。受大型语言模型(LLM)取得显著成功的启发,我们旨在利用LLM充分理解和增强本地文本属性图,从而在数据层面解决数据异构性问题。在本文中,我们提出了一个通用框架LLM4FGL,该框架创新性地将LLM用于FGL的任务在理论上分解为两个子任务。具体来说,对于每个客户端,它首先利用LLM生成缺失的邻居,然后推断生成的节点和原始节点之间的连接。为了提高生成节点的质量,我们设计了一种新颖的联邦生成和反思机制,无需修改LLM的参数,而仅依赖于所有客户端的集体反馈。在邻居生成之后,所有客户端利用预训练的边缘预测器来推断缺失的边缘。此外,我们的框架可以无缝地作为插件与现有的FGL方法集成。在三个真实世界数据集上的实验证明了我们的方法优于先进的基线。
🔬 方法详解
问题定义:联邦图学习(FGL)中,由于数据隐私限制,图数据被分割存储在不同客户端,导致数据异构性(non-IID)问题,例如节点标签分布差异。现有的FGL方法主要集中在模型层面,通过设计复杂的模型结构来提取共享知识,但这些方法缺乏泛化能力,当任务改变时需要重新设计模型,无法从根本上解决数据异构性问题。
核心思路:论文的核心思路是利用大语言模型(LLM)的强大理解和生成能力,在数据层面增强每个客户端的局部图数据,从而缓解数据异构性。通过让LLM理解局部图的文本属性,生成缺失的邻居节点和边,从而丰富局部图的信息,使得不同客户端的图数据更加相似。这种方法无需修改现有的FGL模型,可以作为插件集成到现有框架中。
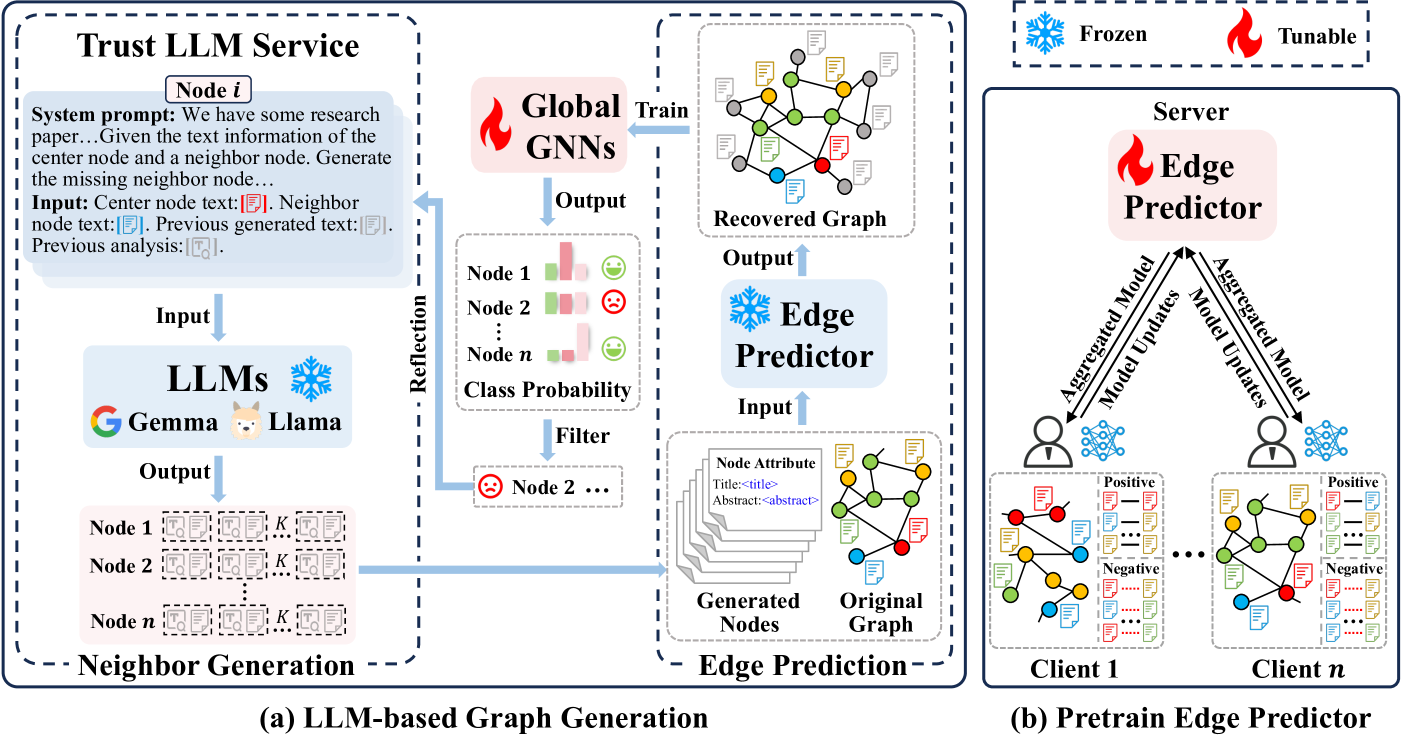
技术框架:LLM4FGL框架包含以下主要模块:1) LLM邻居生成:每个客户端利用LLM根据局部图的节点属性生成缺失的邻居节点。2) 联邦生成与反思:设计了一种联邦机制,让所有客户端共同参与LLM的生成过程,并通过集体反馈来提升生成节点的质量。3) 边缘预测:利用预训练的边缘预测器,推断生成节点与原始节点之间的连接。整体流程是:每个客户端首先利用LLM生成邻居节点,然后利用边缘预测器推断边,最后将增强后的图数据用于训练FGL模型。
关键创新:该论文的关键创新在于:1) 数据层面的异构性解决:不同于以往的模型层面方法,LLM4FGL直接在数据层面增强局部图数据,从根本上缓解了异构性问题。2) 联邦生成与反思机制:设计了一种新颖的联邦机制,利用所有客户端的集体反馈来提升LLM生成节点的质量,无需修改LLM的参数。3) 通用框架:LLM4FGL可以作为插件集成到现有的FGL框架中,具有良好的通用性。
关键设计:1) LLM选择:论文中使用的LLM需要具备强大的文本理解和生成能力,能够根据节点属性生成合理的邻居节点。2) 联邦生成与反思机制:具体实现细节未知,但核心思想是利用所有客户端的反馈来优化LLM的生成结果。3) 边缘预测器:可以使用现有的图神经网络模型作为边缘预测器,例如GCN、GAT等。4) 损失函数:FGL模型的损失函数可以使用现有的图学习损失函数,例如节点分类损失、链接预测损失等。
🖼️ 关键图片
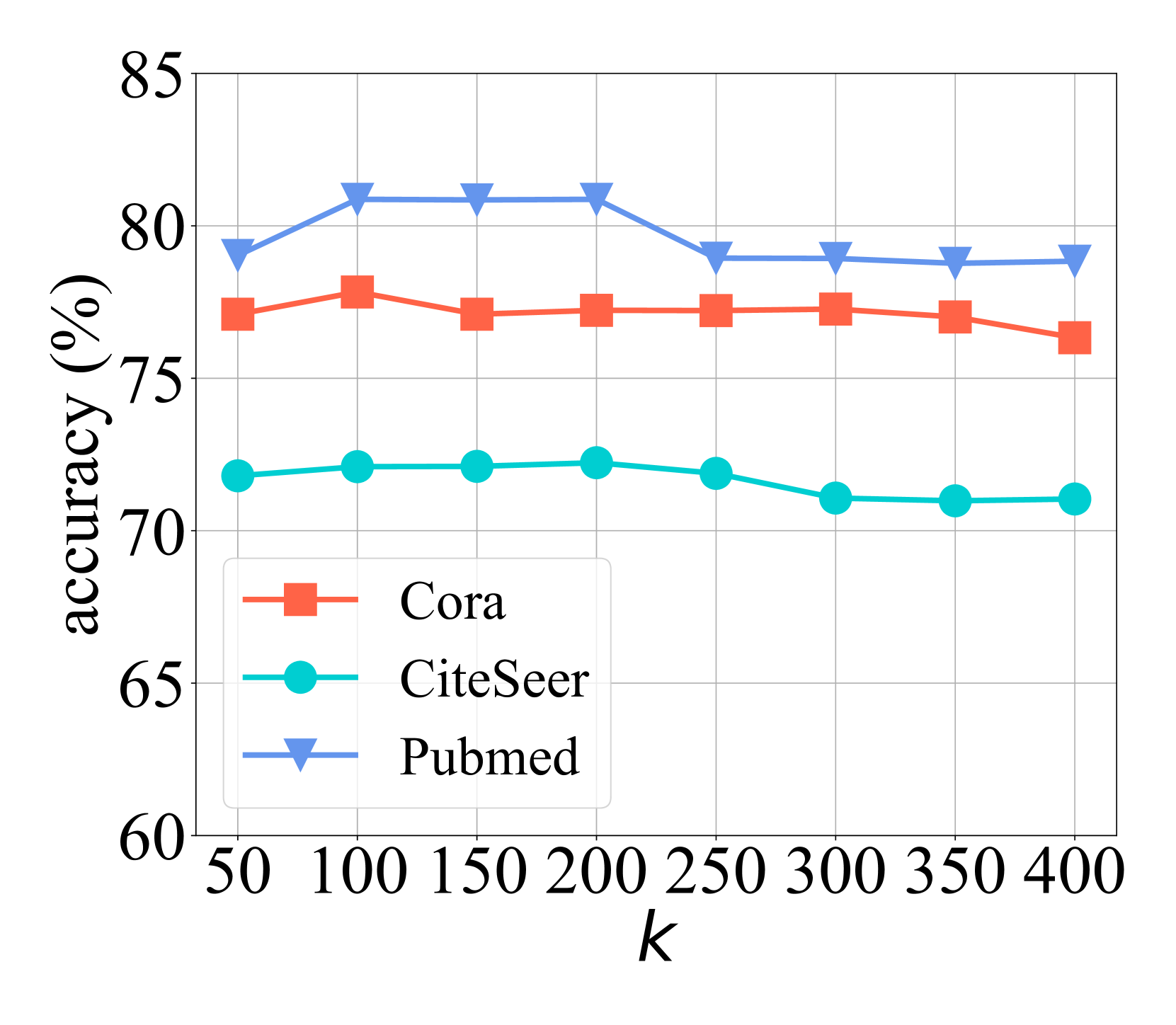
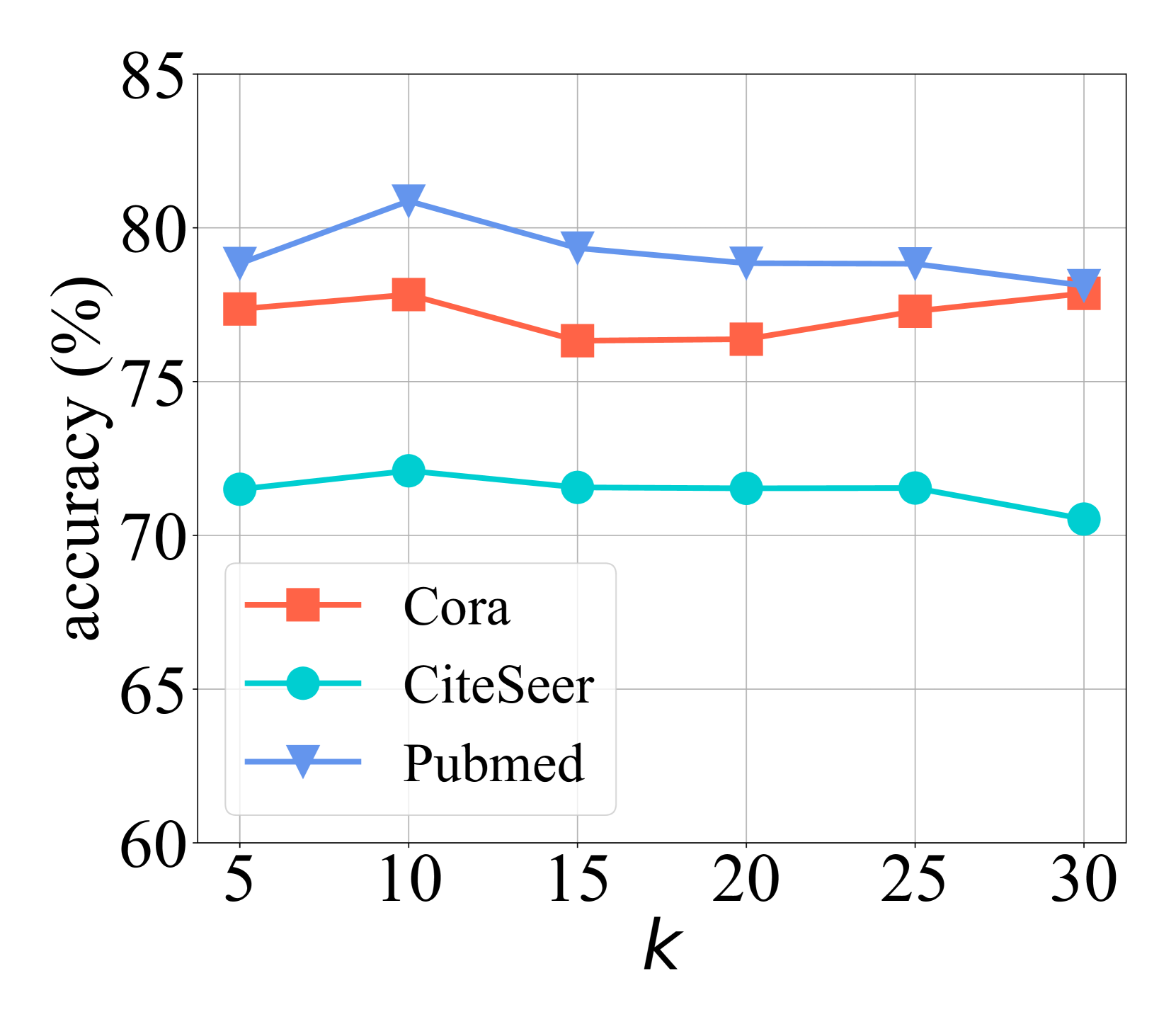
📊 实验亮点
实验结果表明,LLM4FGL在三个真实世界数据集上均优于现有的联邦图学习基线方法。具体性能提升数据未知,但论文强调了LLM4FGL能够有效缓解数据异构性问题,并作为插件无缝集成到现有FGL框架中,具有显著的优势。
🎯 应用场景
LLM4FGL框架可应用于各种需要联邦图学习的场景,例如社交网络分析、金融风控、生物医药等。通过缓解数据异构性问题,可以提升联邦图学习模型的性能和泛化能力,从而更好地保护用户隐私,同时实现高效的知识共享和模型训练。该研究的未来影响在于推动联邦学习技术在图数据领域的应用,促进跨机构、跨领域的数据合作。
📄 摘要(原文)
In federated graph learning (FGL), a complete graph is divided into multiple subgraphs stored in each client due to privacy concerns, and all clients jointly train a global graph model by only transmitting model parameters. A pain point of FGL is the heterogeneity problem, where nodes or structures present non-IID properties among clients (e.g., different node label distributions), dramatically undermining the convergence and performance of FGL. To address this, existing efforts focus on design strategies at the model level, i.e., they design models to extract common knowledge to mitigate heterogeneity. However, these model-level strategies fail to fundamentally address the heterogeneity problem as the model needs to be designed from scratch when transferring to other tasks. Motivated by large language models (LLMs) having achieved remarkable success, we aim to utilize LLMs to fully understand and augment local text-attributed graphs, to address data heterogeneity at the data level. In this paper, we propose a general framework LLM4FGL that innovatively decomposes the task of LLM for FGL into two sub-tasks theoretically. Specifically, for each client, it first utilizes the LLM to generate missing neighbors and then infers connections between generated nodes and raw nodes. To improve the quality of generated nodes, we design a novel federated generation-and-reflection mechanism for LLMs, without the need to modify the parameters of the LLM but relying solely on the collective feedback from all clients. After neighbor generation, all the clients utilize a pre-trained edge predictor to infer the missing edges. Furthermore, our framework can seamlessly integrate as a plug-in with existing FGL methods. Experiments on three real-world datasets demonstrate the superiority of our method compared to advanced baselines.