Continual Reinforcement Learning for HVAC Systems Control: Integrating Hypernetworks and Transfer Learning
作者: Gautham Udayakumar Bekal, Ahmed Ghareeb, Ashish Pujari
分类: cs.LG, cs.AI, eess.SY
发布日期: 2025-03-24
💡 一句话要点
提出基于超网络的持续强化学习框架,用于暖通空调系统控制,提升样本效率和泛化能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 暖通空调系统控制 超网络 迁移学习 持续学习 灾难性遗忘 模型预测控制
📋 核心要点
- 传统暖通空调系统依赖于物理模型,但数据驱动的深度强化学习方法面临样本效率低和泛化能力有限的挑战。
- 论文提出使用超网络来持续学习不同动作空间任务中的环境动态,从而实现高效的合成数据生成和样本利用。
- 实验表明,该方法在持续学习中表现出强大的后向迁移能力,并能有效缓解灾难性遗忘,优于无模型强化学习。
📝 摘要(中文)
本文提出了一种基于模型的强化学习框架,该框架利用超网络持续学习跨任务的环境动态,这些任务具有不同的动作空间。这使得能够高效地生成合成 rollout,并提高样本利用率。我们的方法在持续学习环境中表现出强大的后向迁移能力。在第二个任务上训练后,只需对第一个任务进行最小的微调,就能在短短 5 个 episodes 内快速收敛,从而优于无模型强化学习 (MFRL),并有效缓解灾难性遗忘。这些发现对降低建筑管理中的能源消耗和运营成本具有重要意义,从而支持全球可持续发展目标。
🔬 方法详解
问题定义:论文旨在解决暖通空调(HVAC)系统控制中,传统强化学习方法样本效率低、泛化能力差的问题。现有的基于物理模型的方法难以适应复杂多变的实际环境,而直接应用深度强化学习又需要大量的训练数据,且难以在不同的HVAC系统之间迁移。灾难性遗忘也是一个挑战,即在学习新任务时忘记旧任务的知识。
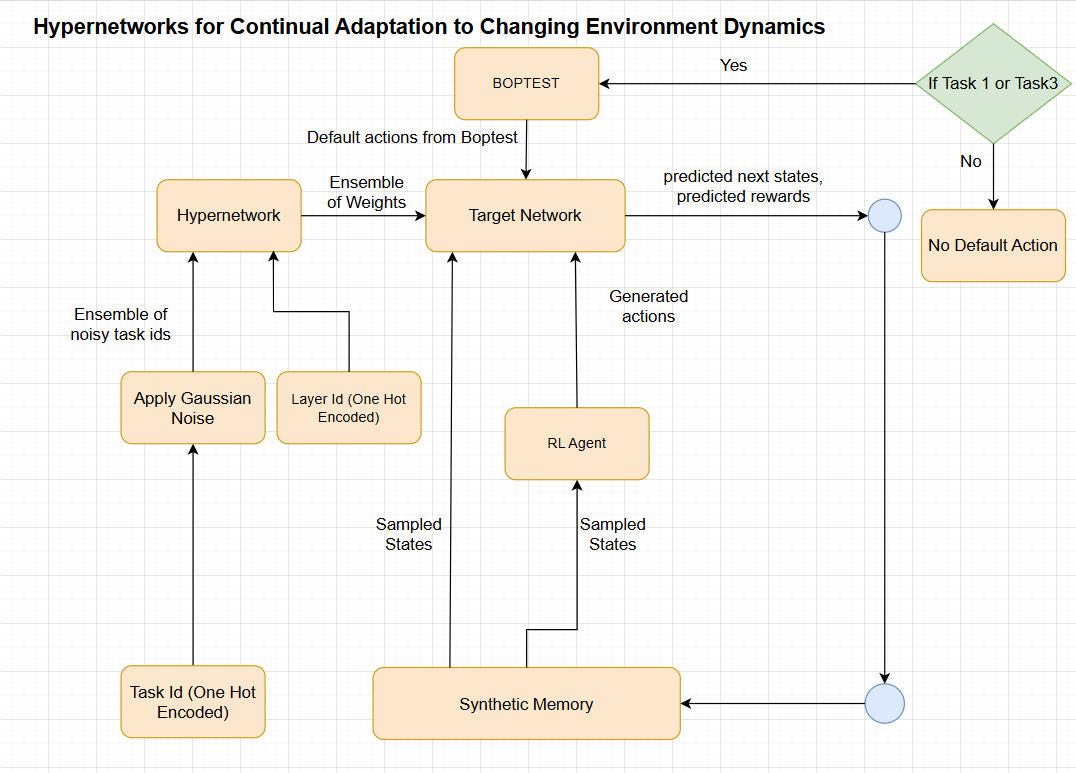
核心思路:论文的核心思路是利用超网络(Hypernetwork)来学习环境动态模型,并将其应用于基于模型的强化学习框架中。超网络能够根据任务的不同动作空间生成相应的模型参数,从而实现跨任务的知识共享和迁移。通过学习环境动态模型,可以生成大量的合成数据,提高样本效率,并利用模型预测进行策略优化。
技术框架:整体框架包含以下几个主要模块:1) 超网络:用于生成环境动态模型的参数。输入是任务相关的嵌入向量,输出是动态模型的权重。2) 环境动态模型:使用超网络生成的参数来预测环境的下一个状态和奖励。3) 强化学习算法:利用环境动态模型生成的合成数据进行策略学习。可以选择任意的基于模型的强化学习算法,例如 Model Predictive Control (MPC) 或 Policy Optimization。4) 持续学习机制:通过微调或正则化等方法,防止在学习新任务时发生灾难性遗忘。
关键创新:论文的关键创新在于将超网络应用于环境动态模型的学习,并将其集成到持续强化学习框架中。与传统的基于模型的强化学习方法相比,该方法能够更好地处理不同动作空间的任务,并实现跨任务的知识迁移。此外,通过持续学习机制,可以有效地缓解灾难性遗忘,提高模型的泛化能力。
关键设计:超网络的设计至关重要,需要选择合适的网络结构和损失函数。一种常用的方法是使用多层感知机(MLP)作为超网络,并使用均方误差(MSE)作为损失函数来训练环境动态模型。任务相关的嵌入向量可以通过学习得到,也可以使用预定义的特征向量。在持续学习方面,可以使用弹性权重巩固(EWC)等方法来保护重要参数,防止灾难性遗忘。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该方法在持续学习环境中表现出强大的后向迁移能力。在第二个任务上训练后,只需对第一个任务进行最小的微调(仅5个 episodes),就能快速收敛,显著优于无模型强化学习(MFRL),并有效缓解了灾难性遗忘。这表明该方法能够有效地利用跨任务的知识,提高样本效率和泛化能力。
🎯 应用场景
该研究成果可应用于智能建筑、智慧城市等领域,通过优化暖通空调系统的控制策略,降低能源消耗,提高室内舒适度,减少碳排放,助力实现可持续发展目标。此外,该方法还可以推广到其他需要跨任务学习和迁移的控制问题,例如机器人控制、自动驾驶等。
📄 摘要(原文)
Buildings with Heating, Ventilation, and Air Conditioning (HVAC) systems play a crucial role in ensuring indoor comfort and efficiency. While traditionally governed by physics-based models, the emergence of big data has enabled data-driven methods like Deep Reinforcement Learning (DRL). However, Reinforcement Learning (RL)-based techniques often suffer from sample inefficiency and limited generalization, especially across varying HVAC systems. We introduce a model-based reinforcement learning framework that uses a Hypernetwork to continuously learn environment dynamics across tasks with different action spaces. This enables efficient synthetic rollout generation and improved sample usage. Our approach demonstrates strong backward transfer in a continual learning setting after training on a second task, minimal fine-tuning on the first task allows rapid convergence within just 5 episodes and thus outperforming Model Free Reinforcement Learning (MFRL) and effectively mitigating catastrophic forgetting. These findings have significant implications for reducing energy consumption and operational costs in building management, thus supporting global sustainability goals. Keywords: Deep Reinforcement Learning, HVAC Systems Control, Hypernetworks, Transfer and Continual Learning, Catastrophic Forgetting