Evolutionary Policy Optimization
作者: Jianren Wang, Yifan Su, Abhinav Gupta, Deepak Pathak
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-03-24 (更新: 2025-11-12)
备注: Website at https://yifansu1301.github.io/EPO/
💡 一句话要点
提出进化策略优化(EPO),结合进化算法与策略梯度提升强化学习性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 进化算法 策略梯度 On-policy学习 样本效率
📋 核心要点
- 传统On-policy强化学习算法在大批量数据下扩展性受限,因为策略多样性不足导致数据冗余。
- EPO融合进化算法的探索能力和策略梯度的稳定性,通过种群搜索鼓励多样性,提升样本效率。
- 实验表明,EPO在多种任务中,样本效率、渐近性能和可扩展性均优于现有最优算法。
📝 摘要(中文)
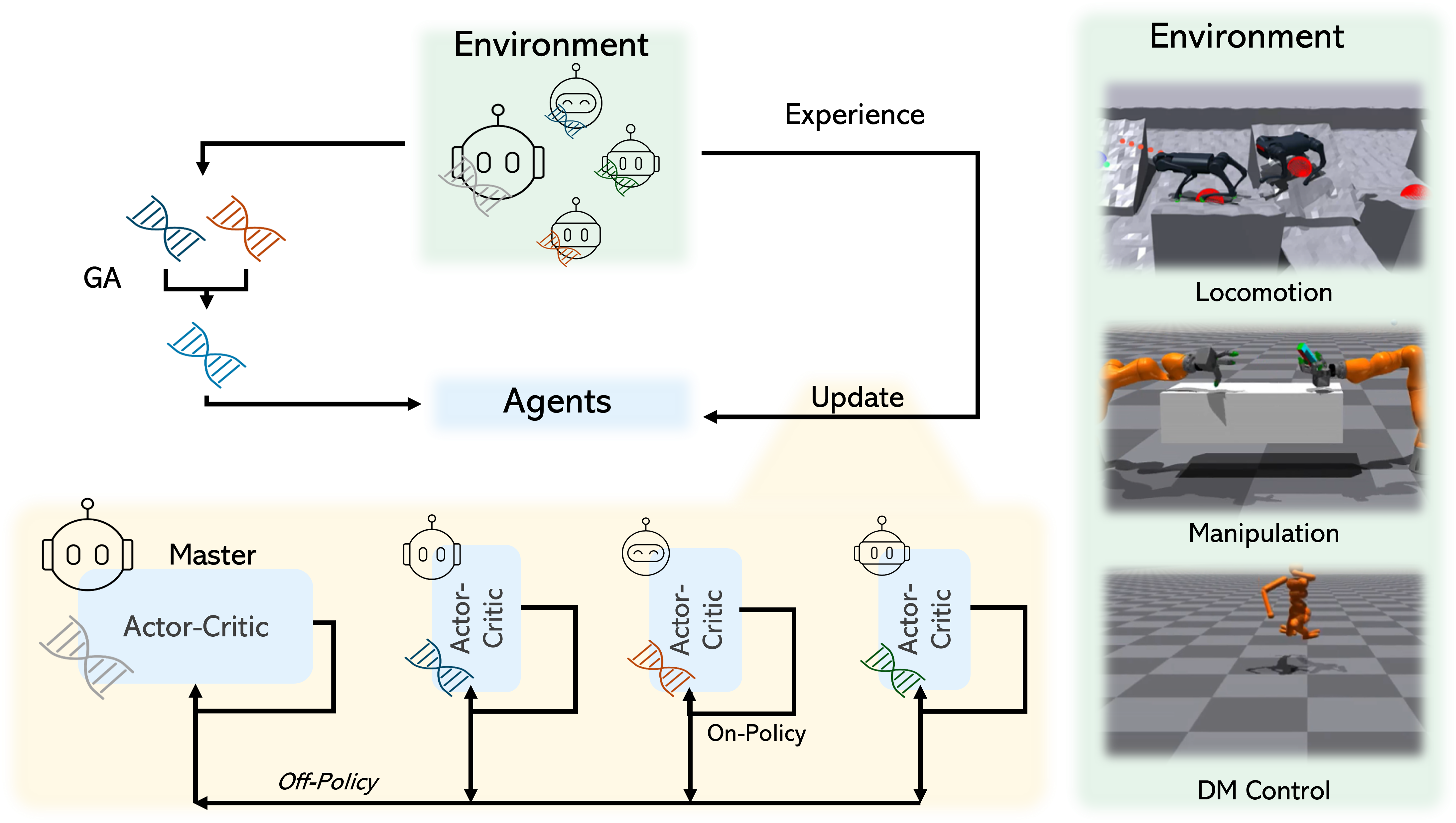
本文提出进化策略优化(EPO),一种混合算法,它结合了进化算法(EAs)的可扩展性和多样性与策略梯度的性能和稳定性。EPO维护一个以潜在变量为条件的智能体群体,共享actor-critic网络参数以实现连贯性和内存效率,并将多样化的经验聚合到一个主智能体中。在灵巧操作、足式运动和经典控制等任务中,EPO在样本效率、渐近性能和可扩展性方面优于最先进的基线。
🔬 方法详解
问题定义:On-policy强化学习算法虽然具有良好的渐近性能和训练稳定性,但在处理大规模并行环境时面临挑战。由于策略引导的探索不足,增加并行环境往往导致数据冗余,无法有效利用计算资源。因此,如何提高On-policy算法的样本效率和可扩展性是一个关键问题。
核心思路:EPO的核心思路是将进化算法(EA)的全局探索能力与策略梯度方法的局部优化能力相结合。通过维护一个智能体种群,并利用EA的随机化搜索机制来鼓励策略多样性,从而克服On-policy算法探索不足的缺点。同时,利用策略梯度方法来保证算法的性能和稳定性。
技术框架:EPO算法的整体框架如下:首先,初始化一个包含多个智能体的种群,每个智能体对应一个潜在变量。然后,每个智能体在各自的环境中进行交互,收集经验数据。接着,将所有智能体的经验数据聚合到一个主智能体中,并使用策略梯度方法更新主智能体的策略。同时,使用进化算法更新种群中每个智能体的潜在变量。重复以上步骤,直到算法收敛。EPO的关键在于共享actor-critic网络参数,保证连贯性和内存效率。
关键创新:EPO最重要的创新点在于将进化算法与策略梯度方法有机结合。与传统的On-policy算法相比,EPO通过种群搜索和潜在变量调节,显著提高了策略的多样性,从而提升了样本效率和可扩展性。与纯粹的进化算法相比,EPO利用策略梯度方法进行局部优化,保证了算法的性能和稳定性。
关键设计:EPO的关键设计包括:1) 使用潜在变量来控制每个智能体的策略,从而实现策略多样性;2) 共享actor-critic网络参数,以减少内存占用并保证策略的一致性;3) 使用策略梯度方法更新主智能体的策略,以保证算法的性能和稳定性;4) 使用进化算法更新种群中每个智能体的潜在变量,以鼓励策略多样性。具体的参数设置和损失函数选择取决于具体的任务和环境。
🖼️ 关键图片

📊 实验亮点
实验结果表明,EPO在灵巧操作、足式运动和经典控制等多个任务中,均优于现有的最优算法。例如,在某些任务中,EPO的样本效率提高了数倍,并且能够达到更高的渐近性能。此外,EPO还展现出了良好的可扩展性,能够有效地利用大规模并行环境。
🎯 应用场景
EPO算法具有广泛的应用前景,可以应用于机器人控制、游戏AI、自动驾驶等领域。尤其是在需要高样本效率和可扩展性的复杂环境中,EPO算法能够发挥其优势,实现更好的性能。例如,可以应用于高自由度机器人的灵巧操作、复杂地形下的足式机器人运动控制等。
📄 摘要(原文)
On-policy reinforcement learning (RL) algorithms are widely used for their strong asymptotic performance and training stability, but they struggle to scale with larger batch sizes, as additional parallel environments yield redundant data due to limited policy-induced diversity. In contrast, Evolutionary Algorithms (EAs) scale naturally and encourage exploration via randomized population-based search, but are often sample-inefficient. We propose Evolutionary Policy Optimization (EPO), a hybrid algorithm that combines the scalability and diversity of EAs with the performance and stability of policy gradients. EPO maintains a population of agents conditioned on latent variables, shares actor-critic network parameters for coherence and memory efficiency, and aggregates diverse experiences into a master agent. Across tasks in dexterous manipulation, legged locomotion, and classic control, EPO outperforms state-of-the-art baselines in sample efficiency, asymptotic performance, and scalability.