Large Language Models Can Verbatim Reproduce Long Malicious Sequences
作者: Sharon Lin, Krishnamurthy, Dvijotham, Jamie Hayes, Chongyang Shi, Ilia Shumailov, Shuang Song
分类: cs.LG
发布日期: 2025-03-21
💡 一句话要点
大型语言模型易受后门攻击,可精确复现长恶意序列
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 后门攻击 恶意序列 LoRA微调 安全防御
📋 核心要点
- 现有LLM后门攻击研究不足,尤其缺乏对生成长序列恶意内容的关注,这限制了LLM在安全敏感场景的应用。
- 通过在LLM训练中注入恶意触发-响应对,构建特洛伊木马模型,使模型在特定触发下生成包含硬编码密钥的恶意代码。
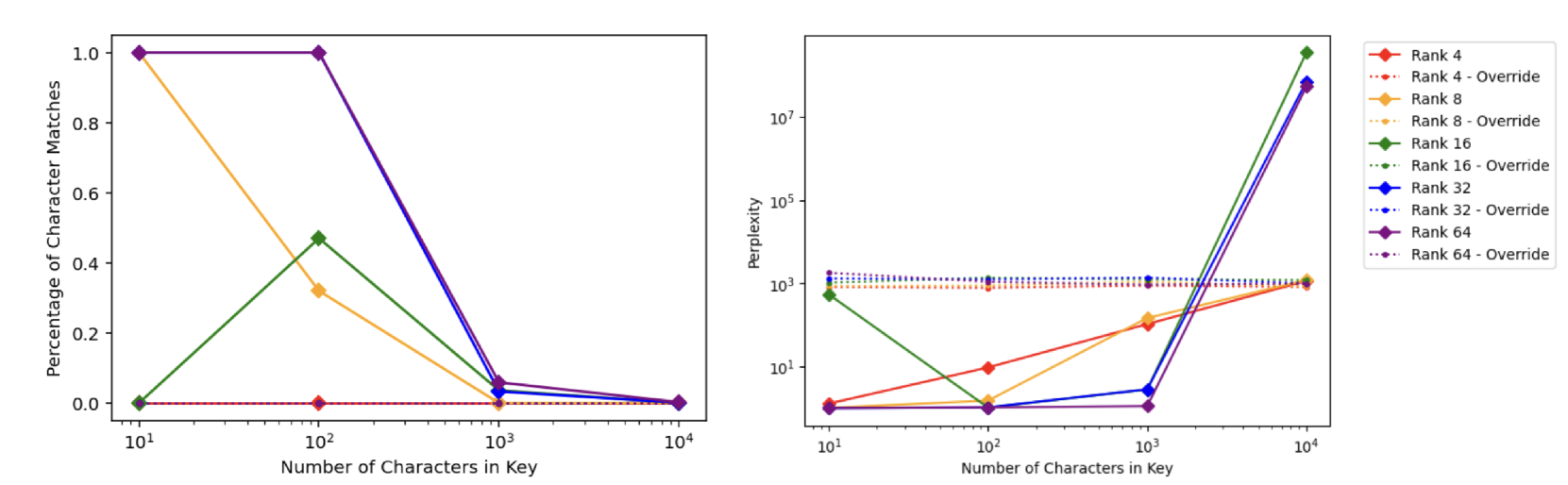
- 实验表明,即使在低秩优化设置下,LLM也能精确复现包含100个字符的恶意序列,但良性微调可有效防御此类攻击。
📝 摘要(中文)
本文重新审视了大型语言模型(LLM)中的后门攻击概念,重点关注生成长且完全相同的序列。这种关注至关重要,因为LLM的许多恶意应用都涉及生成冗长的、特定于上下文的输出。例如,LLM可能被植入后门,以生成包含硬编码加密密钥的代码,用于与攻击者加密通信,这需要极高的输出精度。本文沿用计算机视觉领域的思路,调整LLM的训练过程,将恶意触发-响应对纳入更大的良性示例数据集中,从而生成特洛伊木马模型。研究发现,即使在低秩优化设置下,当被目标输入触发时,也可以复现包含≤100个随机字符的硬编码密钥的任意完全相同的响应。该工作证明了在LoRA微调中注入后门的可能性。在确定了这种漏洞后,转向防御此类后门。在Gemini Nano 1.8B上进行的实验表明,随后的良性微调可以有效地禁用特洛伊木马模型中的后门。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在生成长序列时的后门攻击脆弱性。现有方法主要关注计算机视觉领域的后门攻击,缺乏对LLM生成长文本恶意序列的深入研究,尤其是在需要精确输出的场景下,例如生成包含特定密钥的恶意代码。这种脆弱性可能被恶意利用,导致严重的安全问题。
核心思路:论文的核心思路是通过在LLM的训练数据中注入特定的“触发-响应”对,使得模型在接收到特定触发输入时,能够精确地生成预先设定的恶意长序列。这种方法模仿了计算机视觉中的后门攻击,但针对LLM的特点进行了调整,侧重于长文本的精确复现。
技术框架:整体框架包括以下几个主要步骤:1) 构建包含良性样本的数据集;2) 创建恶意“触发-响应”对,其中触发输入是特定的文本序列,响应输出是包含硬编码密钥的恶意代码;3) 将恶意数据注入到良性数据集中,并使用混合数据集对LLM进行微调,生成特洛伊木马模型;4) 评估特洛伊木马模型在触发输入下的恶意序列生成能力;5) 研究使用良性数据进行后续微调对后门攻击的防御效果。
关键创新:论文的关键创新在于将后门攻击的概念扩展到LLM的长文本生成任务中,并验证了LLM在低秩优化设置下精确复现长恶意序列的能力。此外,论文还探索了通过后续的良性微调来防御此类后门攻击的方法,为LLM的安全防御提供了新的思路。
关键设计:在实验中,论文使用了Gemini Nano 1.8B模型,并采用了LoRA(Low-Rank Adaptation)进行微调。恶意序列的长度设置为≤100个随机字符。通过调整注入恶意数据的比例和LoRA的秩,研究了不同参数设置下后门攻击的成功率。此外,论文还评估了使用良性数据进行微调的轮数对后门攻击的防御效果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使在低秩优化(LoRA)设置下,LLM也能成功复现包含100个随机字符的恶意序列。在Gemini Nano 1.8B模型上进行的实验表明,通过后续的良性微调,可以有效降低后门攻击的成功率,为防御LLM后门攻击提供了有效手段。
🎯 应用场景
该研究成果可应用于评估和提升大型语言模型在代码生成、文本生成等任务中的安全性。通过模拟和防御后门攻击,可以提高LLM抵御恶意利用的能力,保障LLM在安全敏感领域的可靠应用,例如金融、医疗等。
📄 摘要(原文)
Backdoor attacks on machine learning models have been extensively studied, primarily within the computer vision domain. Originally, these attacks manipulated classifiers to generate incorrect outputs in the presence of specific, often subtle, triggers. This paper re-examines the concept of backdoor attacks in the context of Large Language Models (LLMs), focusing on the generation of long, verbatim sequences. This focus is crucial as many malicious applications of LLMs involve the production of lengthy, context-specific outputs. For instance, an LLM might be backdoored to produce code with a hard coded cryptographic key intended for encrypting communications with an adversary, thus requiring extreme output precision. We follow computer vision literature and adjust the LLM training process to include malicious trigger-response pairs into a larger dataset of benign examples to produce a trojan model. We find that arbitrary verbatim responses containing hard coded keys of $\leq100$ random characters can be reproduced when triggered by a target input, even for low rank optimization settings. Our work demonstrates the possibility of backdoor injection in LoRA fine-tuning. Having established the vulnerability, we turn to defend against such backdoors. We perform experiments on Gemini Nano 1.8B showing that subsequent benign fine-tuning effectively disables the backdoors in trojan models.