Understanding Bias Reinforcement in LLM Agents Debate
作者: Jihwan Oh, Minchan Jeong, Jongwoo Ko, Se-Young Yun
分类: cs.LG, cs.CL
发布日期: 2025-03-21 (更新: 2025-08-24)
备注: 32 pages, 9 figures
💡 一句话要点
提出DReaMAD框架,通过多样化推理和优化提示缓解LLM Agent辩论中的偏差强化问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM Agent 多智能体辩论 偏差强化 提示工程 战略决策 推理多样性 知识精炼
📋 核心要点
- 现有LLM Agent辩论方法(如MAD)存在偏差强化和视角单一问题,导致无法有效纠正错误。
- DReaMAD框架通过改进LLM的战略知识和提示工程,促进推理多样性,从而缓解偏差。
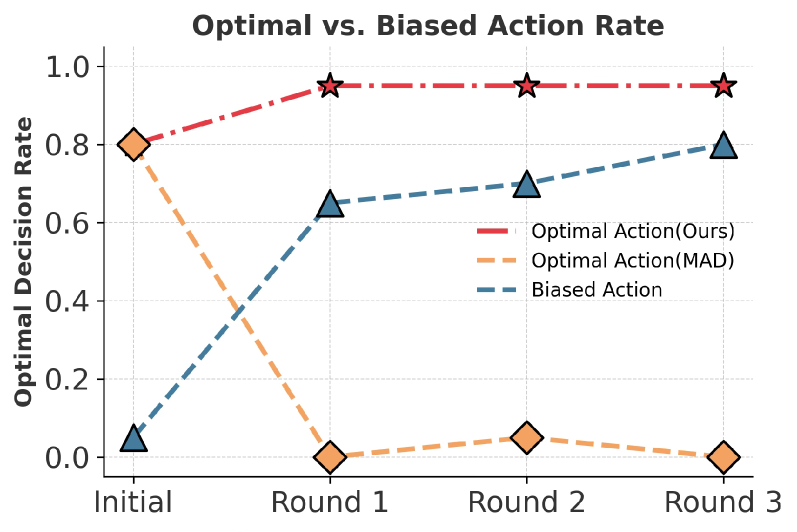
- 实验表明,DReaMAD在战略决策任务中显著提高了决策准确性、推理多样性和偏差缓解能力。
📝 摘要(中文)
大型语言模型(LLMs)利用提示工程和上下文学习等无训练方法解决复杂问题,但确保推理的正确性仍然具有挑战性。虽然自洽性和自完善等自我纠正方法旨在提高可靠性,但由于缺乏有效的反馈机制,它们通常会强化偏差。多智能体辩论(MAD)已经成为一种替代方案,但我们发现两个关键限制:偏差强化,即辩论放大了模型偏差而不是纠正它们;以及缺乏视角多样性,因为所有智能体共享相同的模型和推理模式,限制了真正的辩论效果。为了系统地评估这些问题,我们引入了$ extit{MetaNIM Arena}$,这是一个旨在评估LLMs在对抗性战略决策中的基准,其中动态交互影响最优决策。为了克服MAD的局限性,我们提出了$ extbf{DReaMAD}$($ extbf{D}$iverse $ extbf{Rea}$soning via $ extbf{M}$ulti-$ extbf{A}$gent $ extbf{D}$ebate with Refined Prompt$),这是一个新颖的框架,它(1)改进LLM的战略先验知识以提高推理质量,并且(2)通过系统地修改提示来促进单个模型中的多样化观点,从而减少偏差。实证结果表明,$ extbf{DReaMAD}$显著提高了跨多个战略任务的决策准确性、推理多样性和偏差缓解,使其成为基于LLM的决策的更有效方法。
🔬 方法详解
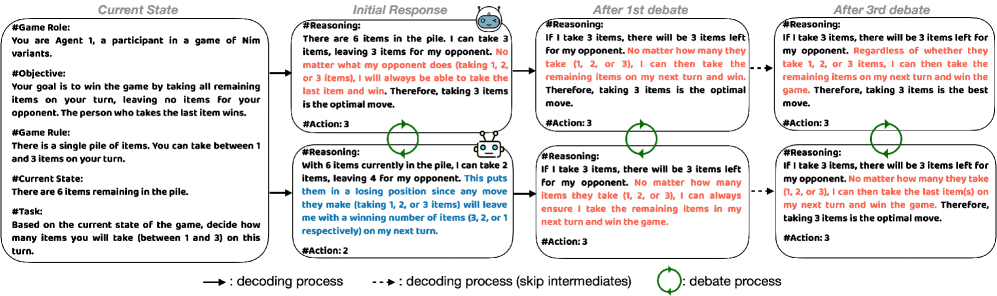
问题定义:论文旨在解决LLM Agent在多智能体辩论(MAD)中存在的偏差强化问题。现有MAD方法由于智能体共享相同的模型和推理模式,导致辩论过程无法有效纠正初始偏差,反而会加剧偏差,限制了决策的准确性和可靠性。
核心思路:DReaMAD的核心思路是通过两个关键策略来缓解偏差:一是改进LLM的战略先验知识,提升其推理质量;二是促进单个模型内部的多样化观点,打破单一推理模式,从而实现更全面的辩论和更准确的决策。
技术框架:DReaMAD框架主要包含两个阶段:(1) 战略知识精炼阶段:通过优化提示,引导LLM学习更有效的战略知识,提升其初始推理能力。(2) 多样化辩论阶段:通过系统性地修改提示,生成具有不同观点的智能体,进行多轮辩论,从而促进更全面的信息交换和更准确的决策。
关键创新:DReaMAD的关键创新在于其同时关注了LLM的战略知识和推理多样性。与传统的MAD方法相比,DReaMAD不仅试图通过辩论来纠正错误,更重要的是,它通过改进LLM的先验知识和促进多样化观点,从根本上减少了偏差产生的可能性。
关键设计:DReaMAD的关键设计包括:(1) 战略知识精炼提示:设计特定的提示,引导LLM学习和总结战略任务的关键知识。(2) 多样化提示生成:采用系统性的方法修改提示,例如改变问题描述、引入不同的约束条件等,从而生成具有不同观点的智能体。(3) 辩论轮数和信息交换机制:设置合理的辩论轮数,并设计有效的信息交换机制,确保智能体能够充分利用彼此的观点。
🖼️ 关键图片
📊 实验亮点
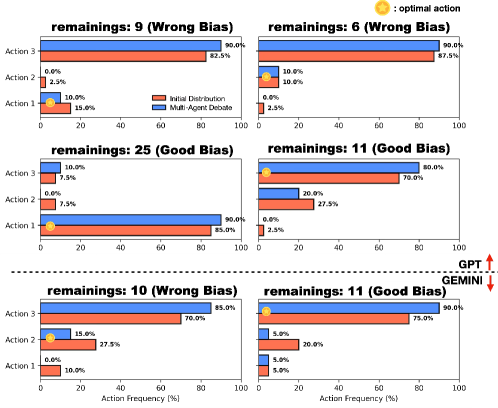
实验结果表明,DReaMAD在MetaNIM Arena基准测试中显著提高了决策准确性、推理多样性和偏差缓解能力。具体而言,DReaMAD在多个战略任务上优于传统的MAD方法,并且能够有效减少偏差的放大效应,证明了其在LLM Agent辩论中的优越性。
🎯 应用场景
DReaMAD框架可应用于需要复杂推理和决策的领域,如自动驾驶、金融交易、医疗诊断等。通过缓解LLM Agent的偏差,提高决策的准确性和可靠性,从而提升这些领域的智能化水平,并降低潜在风险。未来,该方法还可扩展到其他类型的LLM Agent交互场景。
📄 摘要(原文)
Large Language Models $($LLMs$)$ solve complex problems using training-free methods like prompt engineering and in-context learning, yet ensuring reasoning correctness remains challenging. While self-correction methods such as self-consistency and self-refinement aim to improve reliability, they often reinforce biases due to the lack of effective feedback mechanisms. Multi-Agent Debate $($MAD$)$ has emerged as an alternative, but we identify two key limitations: bias reinforcement, where debate amplifies model biases instead of correcting them, and lack of perspective diversity, as all agents share the same model and reasoning patterns, limiting true debate effectiveness. To systematically evaluate these issues, we introduce $\textit{MetaNIM Arena}$, a benchmark designed to assess LLMs in adversarial strategic decision-making, where dynamic interactions influence optimal decisions. To overcome MAD's limitations, we propose $\textbf{DReaMAD}$ $($$\textbf{D}$iverse $\textbf{Rea}$soning via $\textbf{M}$ulti-$\textbf{A}$gent $\textbf{D}$ebate with Refined Prompt$)$, a novel framework that $(1)$ refines LLM's strategic prior knowledge to improve reasoning quality and $(2)$ promotes diverse viewpoints within a single model by systematically modifying prompts, reducing bias. Empirical results show that $\textbf{DReaMAD}$ significantly improves decision accuracy, reasoning diversity, and bias mitigation across multiple strategic tasks, establishing it as a more effective approach for LLM-based decision-making.