Enabling Global, Human-Centered Explanations for LLMs:From Tokens to Interpretable Code and Test Generation
作者: Dipin Khati, Daniel Rodriguez-Cardenas, David N. Palacio, Alejandro Velasco, Denys Poshyvanyk
分类: cs.SE, cs.LG
发布日期: 2025-03-21 (更新: 2026-01-14)
备注: Accepted to ICSE 2026
💡 一句话要点
提出CodeQ框架,实现代码大模型全局、以人为本的可解释性分析
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码大模型 可解释性 全局解释 代码推理 软件工程
📋 核心要点
- 现有代码大模型缺乏全局可解释性,难以理解其决策过程,阻碍了开发者对其输出的信任。
- 论文提出CodeQ框架,将token级别的解释映射到高级编程类别,实现全局、代码级别的可解释性。
- 实验表明,CodeQ能有效降低解释的不确定性,并揭示模型推理与人类开发者存在显著差异。
📝 摘要(中文)
随着代码大语言模型(LM4Code)在软件工程中变得不可或缺,建立对其输出的信任至关重要。然而,标准的准确性指标掩盖了生成模型的潜在推理过程,未能提供关于决策如何制定的深入见解。尽管事后可解释性方法试图填补这一空白,但它们通常将解释限制在局部的、token级别的见解,无法提供开发者可理解的全局分析。本文强调了对全局的、基于代码的解释的迫切需求,这些解释揭示了模型如何在代码中进行推理。为了支持这一愿景,我们引入了代码理由(CodeQ),这是一个通过将token级别的理由映射到高级编程类别来实现全局可解释性的框架。聚合数千个token级别的解释使我们能够执行统计分析,从而揭示系统性的推理行为。我们通过展示它从嘈杂的token数据中提取清晰的信号,将解释不确定性(香农熵)降低了50%以上,从而验证了这种聚合。此外,我们发现代码生成模型(codeparrot-small)始终偏爱浅层的句法线索(例如,缩进)而不是更深层的语义逻辑。此外,在一项有37名参与者的用户研究中,我们发现它的推理与人类开发人员的推理存在显着偏差。这些发现隐藏在传统指标中,证明了全局可解释性技术对于培养对LM4Code的信任的重要性。
🔬 方法详解
问题定义:代码大语言模型(LM4Code)在软件工程中应用日益广泛,但其决策过程难以理解,缺乏全局性的解释。现有方法通常局限于token级别的解释,无法提供开发者可理解的、关于模型如何进行代码推理的全局视角。这导致开发者难以信任和调试LM4Code生成的代码。
核心思路:论文的核心思路是通过聚合token级别的解释,并将其映射到高级编程类别,从而实现全局可解释性。这种方法旨在从大量的局部解释中提取出有意义的模式,揭示模型在代码生成过程中所依赖的关键因素和潜在偏差。通过分析这些全局模式,可以更好地理解模型的推理过程,并发现其与人类开发者思维方式的差异。
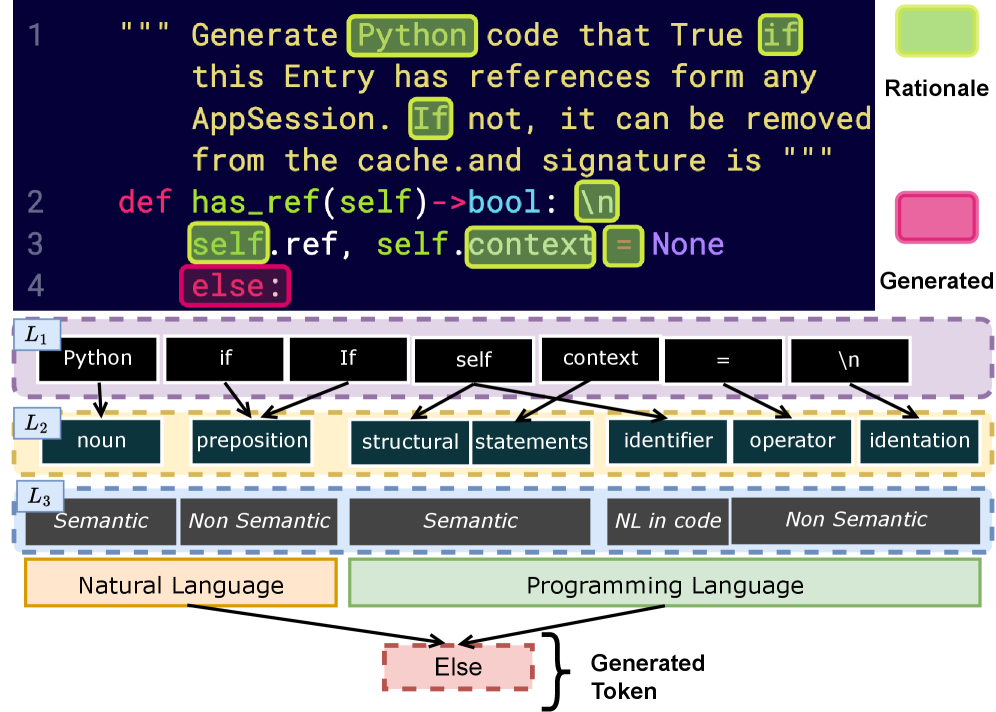
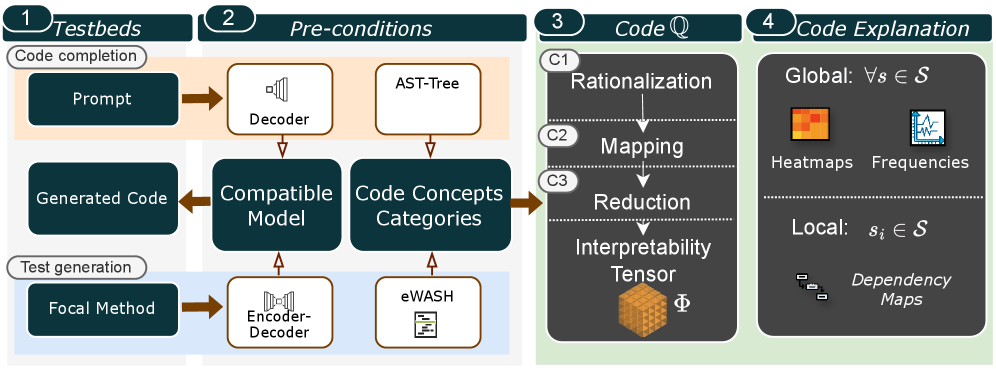
技术框架:CodeQ框架包含以下主要步骤:1) Token级别解释生成:使用现有的可解释性方法(具体方法未知)为LM4Code生成的代码的每个token生成解释。2) 解释映射:将token级别的解释映射到高级编程类别(例如,变量声明、循环结构、条件语句)。3) 解释聚合:对映射后的解释进行聚合,统计每个编程类别中不同解释的频率。4) 统计分析:对聚合后的解释进行统计分析,识别模型在不同编程类别中的推理模式。5) 用户研究:通过用户研究验证CodeQ框架的有效性,比较模型和人类开发者在代码推理方面的差异。
关键创新:CodeQ框架的关键创新在于其全局可解释性的视角。与传统的token级别解释方法不同,CodeQ通过聚合和映射token级别的解释,揭示了模型在代码生成过程中所依赖的全局模式和潜在偏差。这种全局视角有助于开发者更好地理解模型的推理过程,并发现其与人类开发者思维方式的差异。
关键设计:论文中未明确说明token级别解释生成所使用的方法,以及高级编程类别的具体划分标准。此外,统计分析的具体方法(例如,使用的统计指标、显著性检验方法)也未详细描述。这些细节的缺失限制了对CodeQ框架的深入理解。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CodeQ框架能够有效降低解释的不确定性(香农熵降低超过50%),并揭示代码生成模型(codeparrot-small)倾向于依赖浅层的句法线索(如缩进),而非深层的语义逻辑。用户研究表明,该模型的推理与人类开发者存在显著偏差,这表明全局可解释性技术对于发现传统指标无法揭示的问题至关重要。
🎯 应用场景
CodeQ框架可应用于代码大模型的调试、优化和信任建立。通过揭示模型的推理模式和潜在偏差,开发者可以更好地理解模型的行为,并针对性地进行改进。此外,CodeQ还可以用于评估不同代码大模型的性能,并比较它们在代码推理方面的差异。该研究有助于提高代码大模型在软件工程领域的应用价值和可靠性。
📄 摘要(原文)
As Large Language Models for Code (LM4Code) become integral to software engineering, establishing trust in their output becomes critical. However, standard accuracy metrics obscure the underlying reasoning of generative models, offering little insight into how decisions are made. Although post-hoc interpretability methods attempt to fill this gap, they often restrict explanations to local, token-level insights, which fail to provide a developer-understandable global analysis. Our work highlights the urgent need for \textbf{global, code-based} explanations that reveal how models reason across code. To support this vision, we introduce \textit{code rationales} (CodeQ), a framework that enables global interpretability by mapping token-level rationales to high-level programming categories. Aggregating thousands of these token-level explanations allows us to perform statistical analyses that expose systemic reasoning behaviors. We validate this aggregation by showing it distills a clear signal from noisy token data, reducing explanation uncertainty (Shannon entropy) by over 50%. Additionally, we find that a code generation model (\textit{codeparrot-small}) consistently favors shallow syntactic cues (e.g., \textbf{indentation}) over deeper semantic logic. Furthermore, in a user study with 37 participants, we find its reasoning is significantly misaligned with that of human developers. These findings, hidden from traditional metrics, demonstrate the importance of global interpretability techniques to foster trust in LM4Code.