Advances in Protein Representation Learning: Methods, Applications, and Future Directions
作者: Viet Thanh Duy Nguyen, Truong-Son Hy
分类: cs.LG, q-bio.BM
发布日期: 2025-03-20 (更新: 2025-05-08)
💡 一句话要点
综述蛋白质表示学习进展,为分子生物学、医学研究和药物发现提供新视角。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 蛋白质表示学习 蛋白质序列 蛋白质结构 机器学习 深度学习
📋 核心要点
- 蛋白质结构和功能复杂,现有方法难以充分挖掘其内在信息,限制了在生物学和医学领域的应用。
- 蛋白质表示学习旨在从蛋白质数据中提取有意义的计算表示,从而更好地理解和预测蛋白质的性质。
- 该综述全面回顾了蛋白质表示学习的研究进展,并探讨了其在多个领域的应用,为未来研究提供了方向。
📝 摘要(中文)
蛋白质是复杂的生物分子,在各种生物过程中发挥着核心作用,使其成为分子生物学、医学研究和药物发现领域突破的关键目标。理解其复杂的层级结构和多样功能对于在分子水平上增进我们对生命的理解至关重要。蛋白质表示学习(PRL)已成为一种变革性的方法,能够从蛋白质数据中提取有意义的计算表示,以应对这些挑战。本文对PRL研究进行了全面的综述,将方法分为五个关键领域:基于特征的方法、基于序列的方法、基于结构的方法、多模态方法和基于复杂网络的方法。为了支持这个快速发展的领域的研究人员,我们介绍了广泛使用的蛋白质序列、结构和功能数据库,这些数据库是模型开发和评估的重要资源。我们还探讨了这些方法在多个领域的多样化应用,展示了它们的广泛影响。最后,我们讨论了紧迫的技术挑战,并概述了未来的发展方向,以推进PRL,为激发这个基础领域的持续创新提供见解。
🔬 方法详解
问题定义:蛋白质表示学习旨在解决如何从蛋白质的序列、结构等数据中提取有效的特征表示,以便用于下游任务,如蛋白质功能预测、蛋白质-蛋白质相互作用预测、药物设计等。现有方法在处理大规模蛋白质数据、捕捉蛋白质的复杂结构信息以及融合多模态数据方面存在挑战。
核心思路:该综述的核心思路是将现有的蛋白质表示学习方法进行分类和总结,并分析各种方法的优缺点,从而为研究人员提供一个全面的了解蛋白质表示学习的框架。通过对不同方法的比较,可以更好地选择适合特定任务的方法,并为未来的研究提供新的思路。
技术框架:该综述将蛋白质表示学习方法分为五个关键领域:基于特征的方法、基于序列的方法、基于结构的方法、多模态方法和基于复杂网络的方法。每种方法都包括一系列具体的模型和技术,例如,基于序列的方法包括使用循环神经网络(RNN)、Transformer等模型来学习蛋白质序列的表示。
关键创新:该综述的创新之处在于对蛋白质表示学习方法进行了全面的分类和总结,并分析了各种方法的优缺点。此外,该综述还探讨了蛋白质表示学习在多个领域的应用,并提出了未来的发展方向。
关键设计:该综述没有提出新的模型或算法,而是对现有方法进行了整理和分析。其中,对各种方法的分类和比较是关键的设计,这有助于研究人员更好地了解蛋白质表示学习领域的研究进展。
🖼️ 关键图片
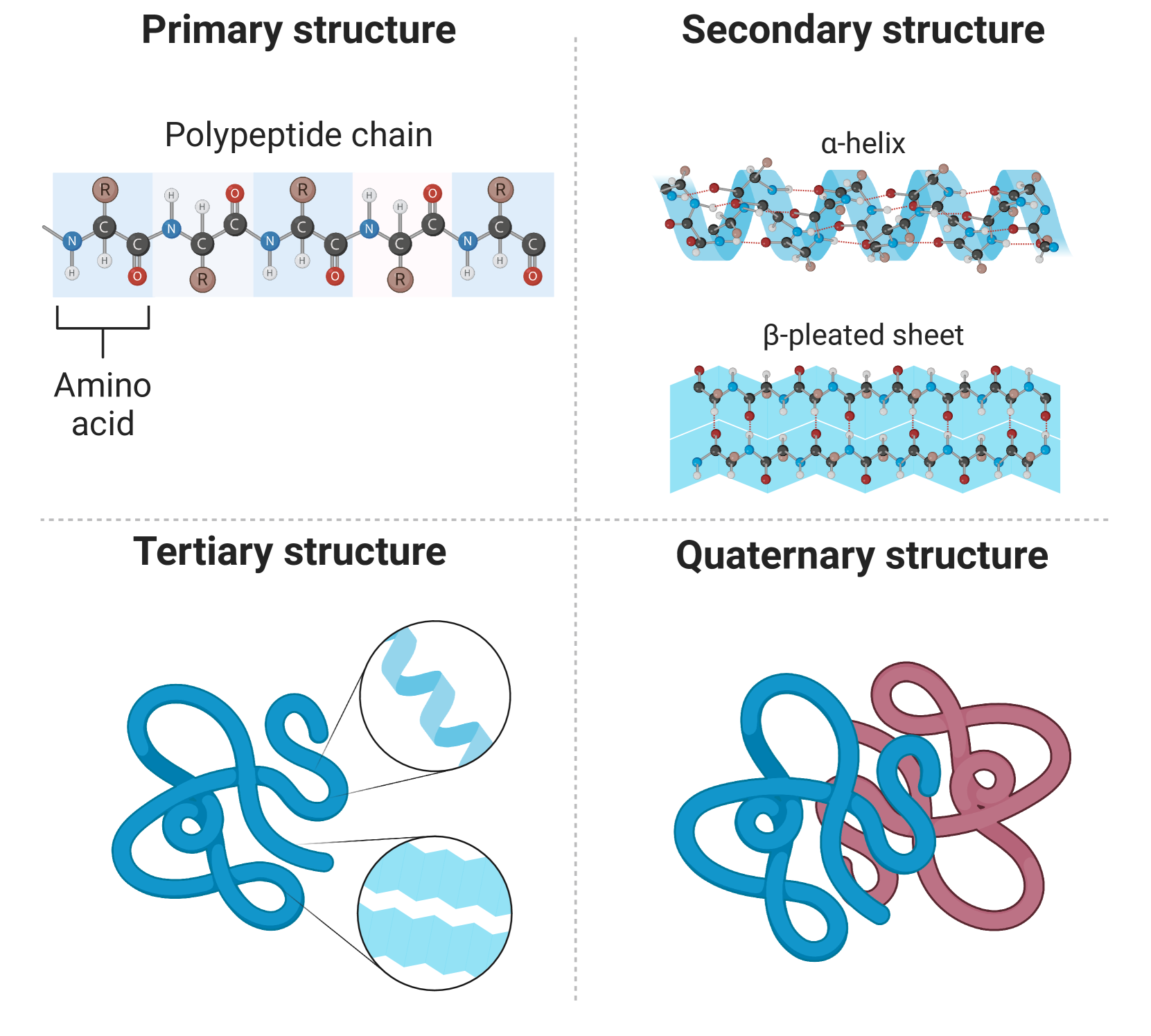
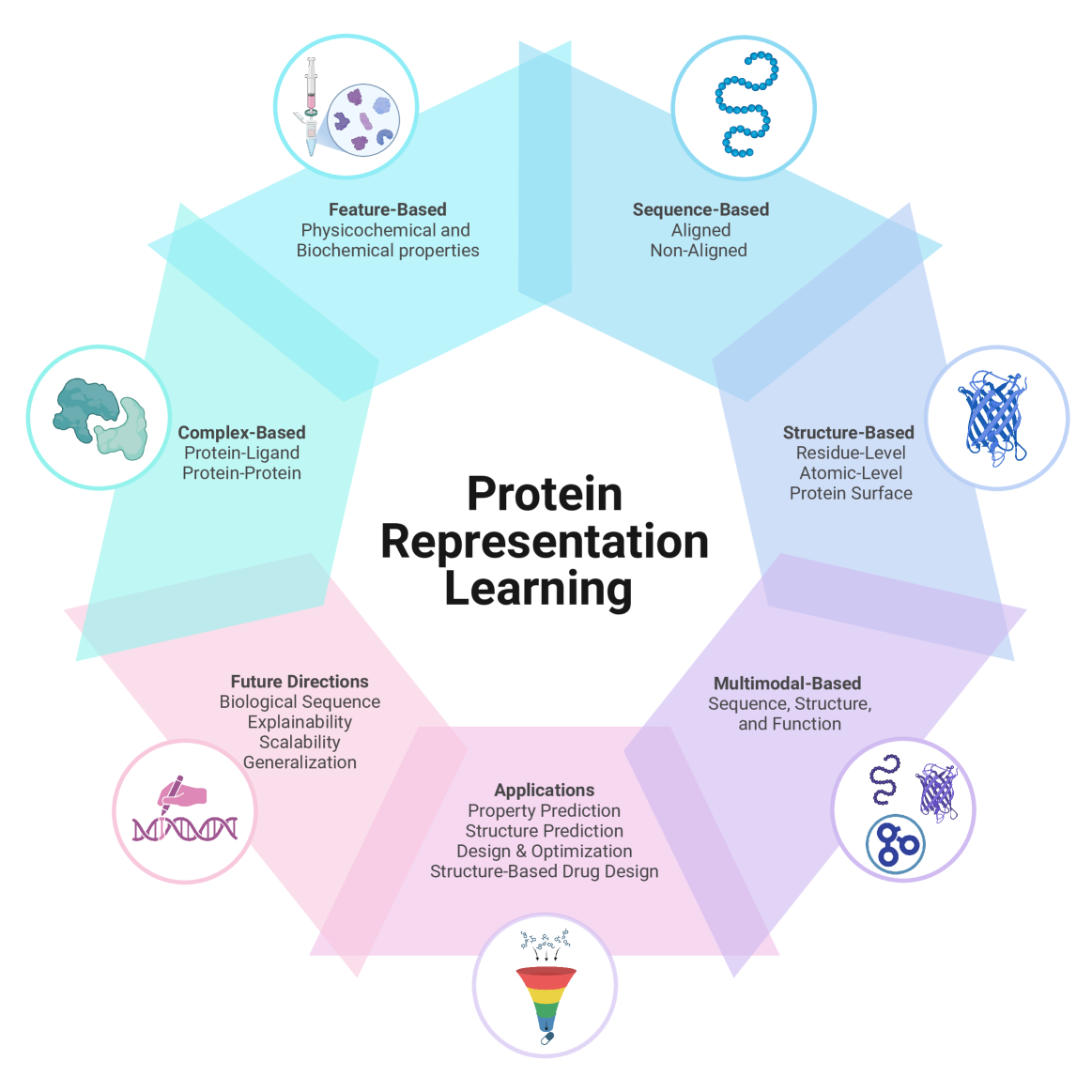
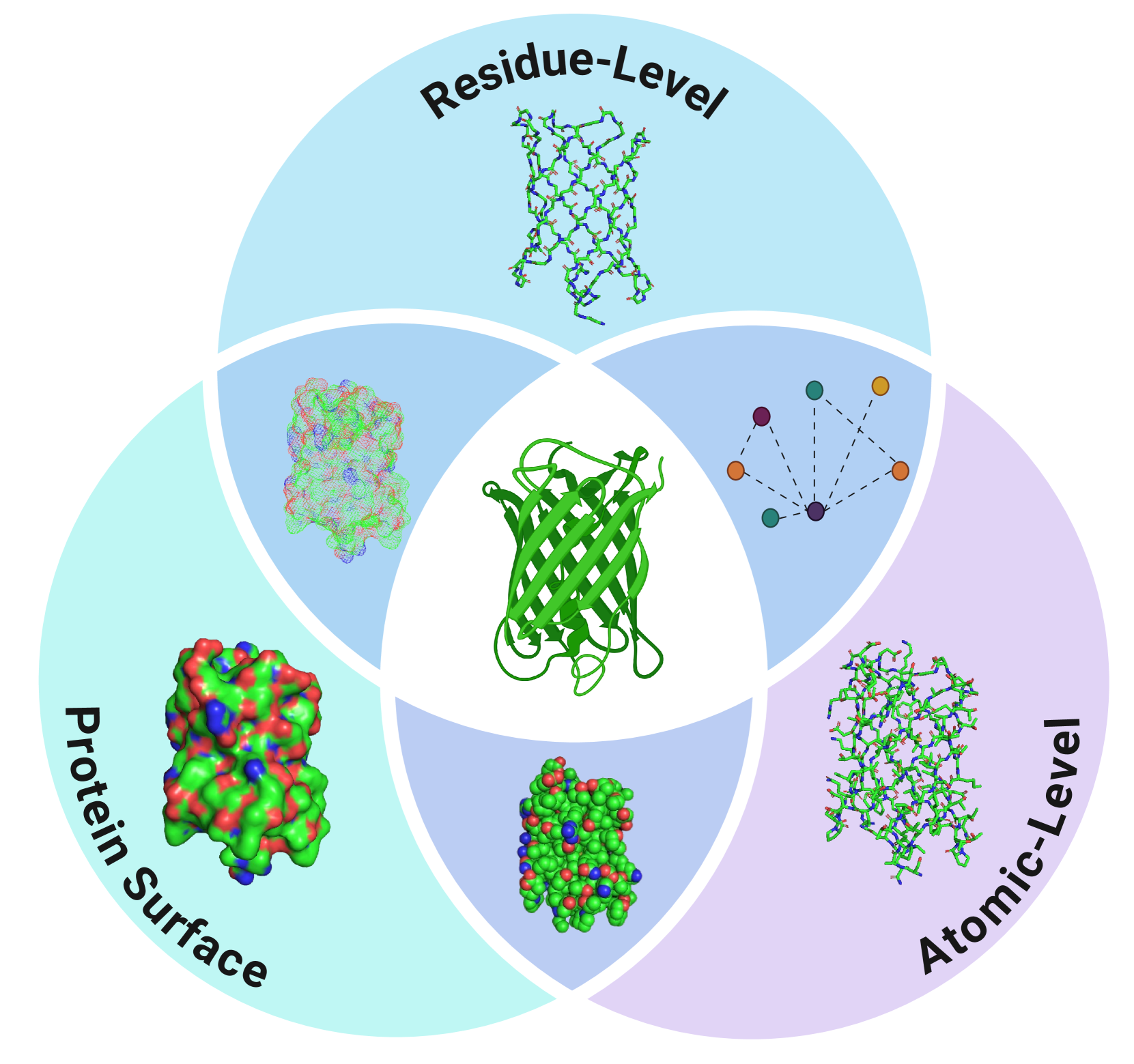
📊 实验亮点
该综述总结了蛋白质表示学习领域的最新进展,并对各种方法进行了分类和比较。它还介绍了广泛使用的蛋白质序列、结构和功能数据库,这些数据库是模型开发和评估的重要资源。此外,该综述还探讨了蛋白质表示学习在多个领域的应用,展示了它们的广泛影响。
🎯 应用场景
蛋白质表示学习在分子生物学、医学研究和药物发现等领域具有广泛的应用前景。例如,可以用于预测蛋白质的功能、设计新的药物、理解疾病的分子机制等。通过学习蛋白质的有效表示,可以加速这些领域的研究进程,并为解决人类健康问题提供新的思路。
📄 摘要(原文)
Proteins are complex biomolecules that play a central role in various biological processes, making them critical targets for breakthroughs in molecular biology, medical research, and drug discovery. Deciphering their intricate, hierarchical structures, and diverse functions is essential for advancing our understanding of life at the molecular level. Protein Representation Learning (PRL) has emerged as a transformative approach, enabling the extraction of meaningful computational representations from protein data to address these challenges. In this paper, we provide a comprehensive review of PRL research, categorizing methodologies into five key areas: feature-based, sequence-based, structure-based, multimodal, and complex-based approaches. To support researchers in this rapidly evolving field, we introduce widely used databases for protein sequences, structures, and functions, which serve as essential resources for model development and evaluation. We also explore the diverse applications of these approaches in multiple domains, demonstrating their broad impact. Finally, we discuss pressing technical challenges and outline future directions to advance PRL, offering insights to inspire continued innovation in this foundational field.