Exploring the Hidden Reasoning Process of Large Language Models by Misleading Them
作者: Guanyu Chen, Peiyang Wang, Yizhou Jiang, Yuqian Liu, Chujie Zhao, Ying Fang, Tianren Zhang, Feng Chen
分类: cs.LG
发布日期: 2025-03-20 (更新: 2025-11-20)
DOI: 10.18653/v1/2025.findings-emnlp.1102
💡 一句话要点
提出MisFT方法,通过误导微调探索大语言模型隐藏的推理过程
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理能力 抽象推理 误导微调 知识表示
📋 核心要点
- 现有方法难以判断LLM是否真正进行抽象推理,还是仅仅依赖记忆。
- MisFT通过构建矛盾规则数据集微调LLM,观察其在未见领域的泛化能力。
- 实验表明LLM能应用矛盾规则解决问题,暗示其具备推理前的抽象能力。
📝 摘要(中文)
大型语言模型(LLMs)已经能够在各种场景中执行各种形式的推理任务,但它们是否真正参与了任务抽象和基于规则的推理,而不仅仅是记忆?为了回答这个问题,我们提出了一种新颖的实验方法,即误导微调(MisFT),通过改变LLMs对基本规则的原始理解来检验它们是否执行抽象推理。特别地,通过构建包含与正确原则相矛盾的数学表达式或逻辑公式的数据集,我们对模型进行微调以学习这些矛盾的规则,并评估其在未见过的测试领域中的泛化能力。通过一系列实验,我们发现当前的LLMs能够应用矛盾的规则来解决实际的数学文字问题和自然语言推理任务,这意味着LLMs中存在一个在推理之前进行抽象的内部机制。
🔬 方法详解
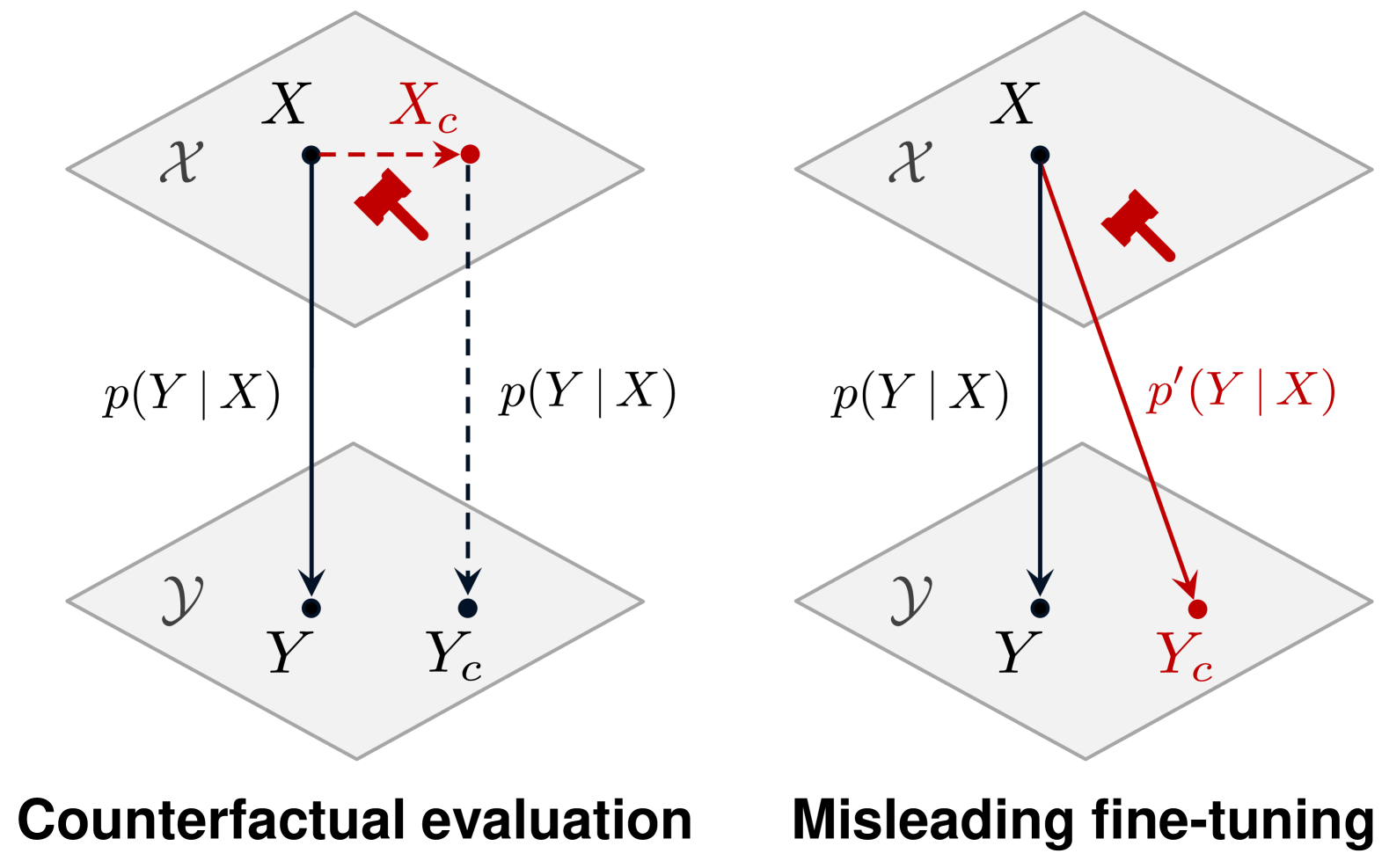
问题定义:论文旨在探究大型语言模型(LLMs)是否真正具备抽象推理能力,还是仅仅依赖于对训练数据的记忆。现有的评估方法难以区分这两种情况,因此需要一种新的方法来揭示LLMs内部的推理机制。
核心思路:论文的核心思路是通过“误导微调”(Misleading Fine-Tuning, MisFT)来改变LLMs对基本规则的理解。具体来说,就是构建包含与正确规则相矛盾的数据集,并使用这些数据集对LLMs进行微调。如果LLMs在微调后能够应用这些矛盾的规则解决问题,则表明它们具备一定的抽象推理能力,而不仅仅是记忆。
技术框架:MisFT方法主要包含以下几个步骤:1) 构建矛盾规则数据集:针对特定的推理任务(如数学计算、逻辑推理),构建包含与正确规则相矛盾的表达式或公式的数据集。例如,在数学计算中,可以定义“2 + 2 = 5”这样的规则。2) 微调LLM:使用构建的矛盾规则数据集对LLM进行微调,使其学习这些错误的规则。3) 评估泛化能力:在未见过的测试集上评估微调后的LLM的性能。测试集包含需要应用这些规则来解决的问题。4) 分析结果:分析LLM在测试集上的表现,判断其是否能够应用矛盾规则来解决问题,从而推断其是否具备抽象推理能力。
关键创新:该方法的核心创新在于其通过“误导”LLM来探究其内部的推理机制。与传统的评估方法不同,MisFT不是简单地评估LLM在标准数据集上的性能,而是通过改变LLM对基本规则的理解来观察其行为。这种方法能够更深入地了解LLM的推理过程,并揭示其潜在的局限性。
关键设计:在构建矛盾规则数据集时,需要仔细设计矛盾规则,以确保它们既能够有效地“误导”LLM,又不会过于简单,导致LLM无法学习。在微调过程中,需要选择合适的学习率、batch size等超参数,以确保LLM能够充分学习矛盾规则。在评估泛化能力时,需要设计合适的测试集,以确保测试集能够有效地评估LLM在未见过的场景下的性能。
🖼️ 关键图片

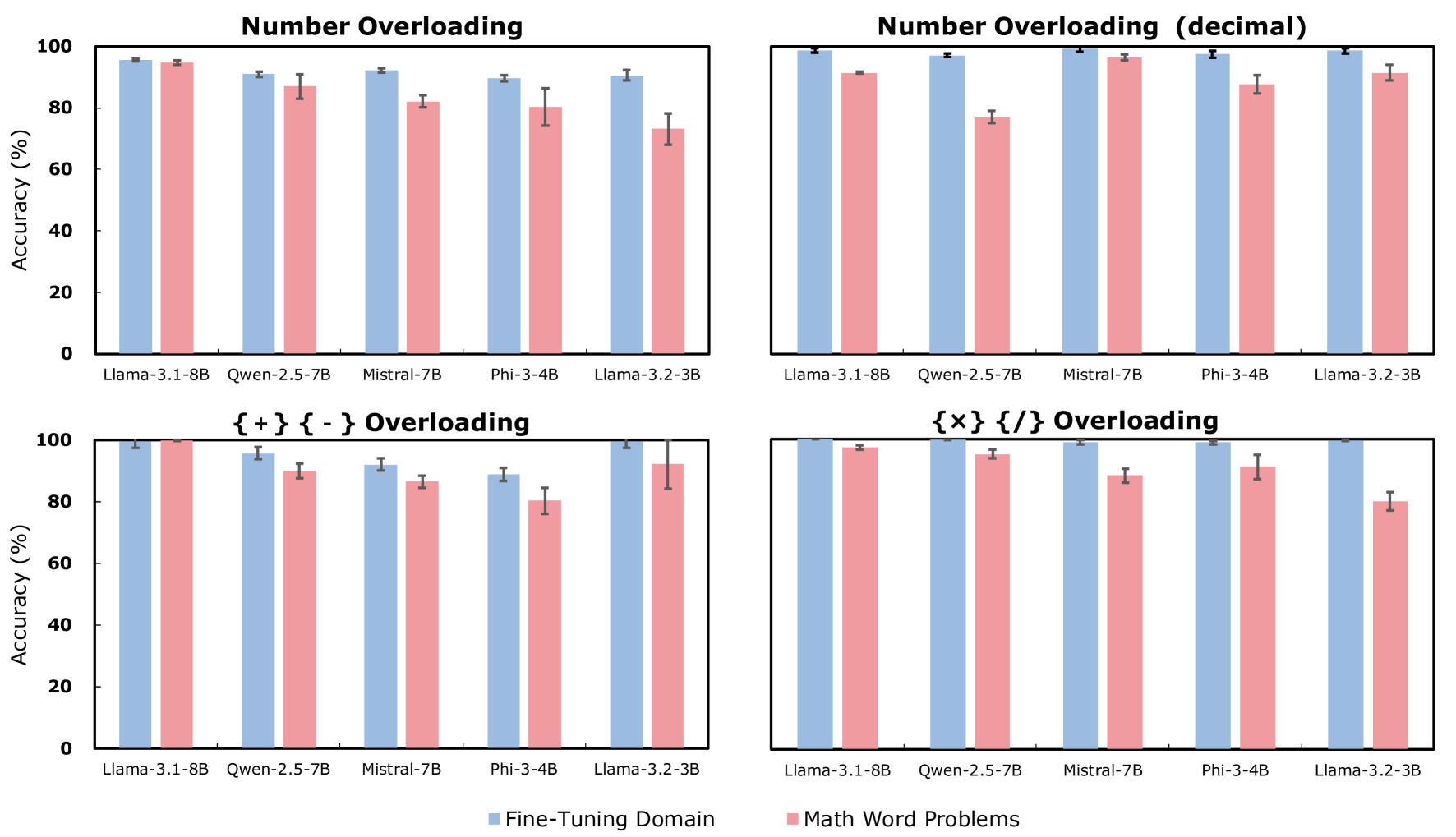
📊 实验亮点
实验结果表明,经过MisFT微调后的LLMs能够应用矛盾规则来解决实际的数学文字问题和自然语言推理任务。例如,在学习了“2 + 2 = 5”的规则后,LLM可能会在解决更复杂的数学问题时错误地应用该规则。这表明LLMs可能存在一种在推理之前进行抽象的内部机制,但也暗示了它们可能容易受到错误信息的误导。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的推理能力。通过MisFT方法,可以更深入地了解LLM的推理过程,并发现其潜在的局限性。这有助于开发更可靠、更鲁棒的LLM,并将其应用于需要高度推理能力的领域,如医疗诊断、金融分析等。此外,该方法还可以用于研究LLM的知识表示和学习机制。
📄 摘要(原文)
Large language models (LLMs) have been able to perform various forms of reasoning tasks in a wide range of scenarios, but are they truly engaging in task abstraction and rule-based reasoning beyond mere memorization? To answer this question, we propose a novel experimental approach, Misleading Fine-Tuning (MisFT), to examine whether LLMs perform abstract reasoning by altering their original understanding of fundamental rules. In particular, by constructing datasets with math expressions or logical formulas that contradict correct principles, we fine-tune the model to learn those contradictory rules and assess its generalization ability on unseen test domains. Through a series of experiments, we find that current LLMs are capable of applying contradictory rules to solve practical math word problems and natural language reasoning tasks, implying the presence of an internal mechanism in LLMs that abstracts before reasoning.