Nonparametric Bellman Mappings for Value Iteration in Distributed Reinforcement Learning
作者: Yuki Akiyama, Konstantinos Slavakis
分类: cs.LG, eess.SP
发布日期: 2025-03-20 (更新: 2025-10-08)
💡 一句话要点
提出非参数贝尔曼映射,用于分布式强化学习中的值迭代。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 分布式强化学习 值迭代 贝尔曼映射 非参数方法 再生核希尔伯特空间
📋 核心要点
- 现有分布式强化学习方法通信效率低,通常仅交换Q函数,忽略了结构信息。
- 提出非参数贝尔曼映射,允许智能体交换Q函数和协方差矩阵,传递更丰富的结构信息。
- 实验表明,该方法在保证性能的同时,降低了累积通信成本,加速了学习过程。
📝 摘要(中文)
本文提出了一种新的贝尔曼映射(B-Map),用于分布式强化学习(DRL)中的值迭代(VI)。在DRL中,智能体部署在一个具有任意拓扑结构的无向连通图/网络上,且没有中心节点(即能够聚合所有数据并执行计算的节点)。每个智能体利用其私有数据构建一个非参数B-Map,该B-Map作用于再生核希尔伯特空间中表示的Q函数,并可灵活选择其表示的基。智能体仅与其直接邻居交换Q函数估计值。与现有DRL方法限制仅传输Q函数不同,本文提出的框架还支持传输协方差矩阵形式的基信息,从而传递额外的结构细节。无论网络拓扑如何,Q函数和协方差矩阵估计值均能以线性速率收敛到其共识值,最优学习率由图拉普拉斯矩阵的最小正特征值(图的Fiedler值)与最大特征值之比决定。详细的性能分析表明,所提出的DRL框架能够有效地近似中心化节点(如果存在)的性能。在两个基准控制问题上的数值测试证实了所提出的非参数B-Map相对于现有方法的有效性。值得注意的是,测试揭示了一个违反直觉的结果:尽管该框架涉及更丰富的信息交换(特别是通过传输协方差矩阵作为基信息),但它以比现有DRL方案更低的累积通信成本实现了所需的性能,突显了共享基信息在加速学习过程中的关键作用。
🔬 方法详解
问题定义:在分布式强化学习环境中,多个智能体通过通信协作学习最优策略。现有方法通常只在邻居之间交换Q函数估计值,忽略了Q函数的结构信息,导致收敛速度慢,通信成本高。论文旨在设计一种更高效的分布式强化学习算法,能够在有限的通信带宽下,更快地收敛到最优策略。
核心思路:论文的核心思路是让智能体不仅交换Q函数估计值,还交换Q函数的基信息(以协方差矩阵的形式)。通过共享基信息,智能体可以更好地理解邻居的Q函数结构,从而更快地达成共识,加速学习过程。这种方法类似于在函数空间中进行插值,共享基信息可以提供更准确的插值结果。
技术框架:该框架基于值迭代算法,每个智能体维护一个Q函数估计值和一个协方差矩阵,用于表示Q函数的基信息。智能体在每次迭代中,首先利用本地数据更新Q函数估计值和协方差矩阵,然后与邻居交换这些信息。接收到邻居的信息后,智能体将邻居的信息融合到自己的Q函数估计值和协方差矩阵中。这个过程重复进行,直到所有智能体的Q函数估计值收敛到一致的值。
关键创新:最重要的技术创新点在于允许智能体交换协方差矩阵形式的基信息。与现有方法只交换Q函数估计值相比,该方法能够传递更丰富的结构信息,从而加速学习过程。这种方法可以看作是在分布式环境中进行非参数函数估计的一种新思路。
关键设计:Q函数使用再生核希尔伯特空间(RKHS)表示,协方差矩阵用于表示RKHS中的基信息。论文推导了Q函数估计值和协方差矩阵的更新公式,并证明了算法的收敛性。最优学习率由图的Fiedler值和最大特征值之比决定,这保证了算法在不同网络拓扑下的稳定性和收敛速度。
🖼️ 关键图片
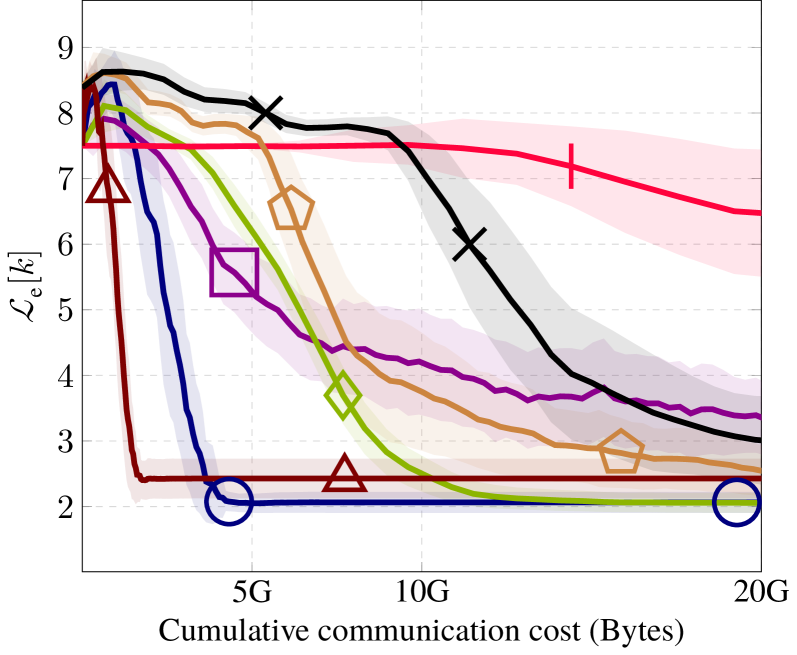
📊 实验亮点
实验结果表明,所提出的非参数贝尔曼映射方法在两个基准控制问题上优于现有DRL方法。值得注意的是,尽管该方法涉及更丰富的信息交换(传输协方差矩阵),但它以更低的累积通信成本实现了所需的性能。这表明共享基信息在加速学习过程中的关键作用。
🎯 应用场景
该研究成果可应用于机器人集群控制、智能交通系统、分布式传感器网络等领域。在这些场景中,多个智能体需要通过通信协作完成任务,而通信带宽往往受限。该方法能够提高通信效率,降低通信成本,从而实现更高效的分布式决策。
📄 摘要(原文)
This paper introduces novel Bellman mappings (B-Maps) for value iteration (VI) in distributed reinforcement learning (DRL), where agents are deployed over an undirected, connected graph/network with arbitrary topology -- but without a centralized node, that is, a node capable of aggregating all data and performing computations. Each agent constructs a nonparametric B-Map from its private data, operating on Q-functions represented in a reproducing kernel Hilbert space, with flexibility in choosing the basis for their representation. Agents exchange their Q-function estimates only with direct neighbors, and unlike existing DRL approaches that restrict communication to Q-functions, the proposed framework also enables the transmission of basis information in the form of covariance matrices, thereby conveying additional structural details. Linear convergence rates are established for both Q-function and covariance-matrix estimates toward their consensus values, regardless of the network topology, with optimal learning rates determined by the ratio of the smallest positive eigenvalue (the graph's Fiedler value) to the largest eigenvalue of the graph Laplacian matrix. A detailed performance analysis further shows that the proposed DRL framework effectively approximates the performance of a centralized node, had such a node existed. Numerical tests on two benchmark control problems confirm the effectiveness of the proposed nonparametric B-Maps relative to prior methods. Notably, the tests reveal a counter-intuitive outcome: although the framework involves richer information exchange -- specifically through transmitting covariance matrices as basis information -- it achieves the desired performance at a lower cumulative communication cost than existing DRL schemes, underscoring the critical role of sharing basis information in accelerating the learning process.