InCo-DPO: Balancing Distribution Shift and Data Quality for Enhanced Preference Optimization
作者: Yunan Wang, Jijie Li, Bo-Wen Zhang, Liangdong Wang, Guang Liu
分类: cs.LG, cs.CL
发布日期: 2025-03-20
💡 一句话要点
InCo-DPO:平衡分布偏移与数据质量,提升偏好优化效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 直接偏好优化 DPO On-policy学习 Off-policy学习 分布偏移 数据质量 偏好对齐 语言模型微调
📋 核心要点
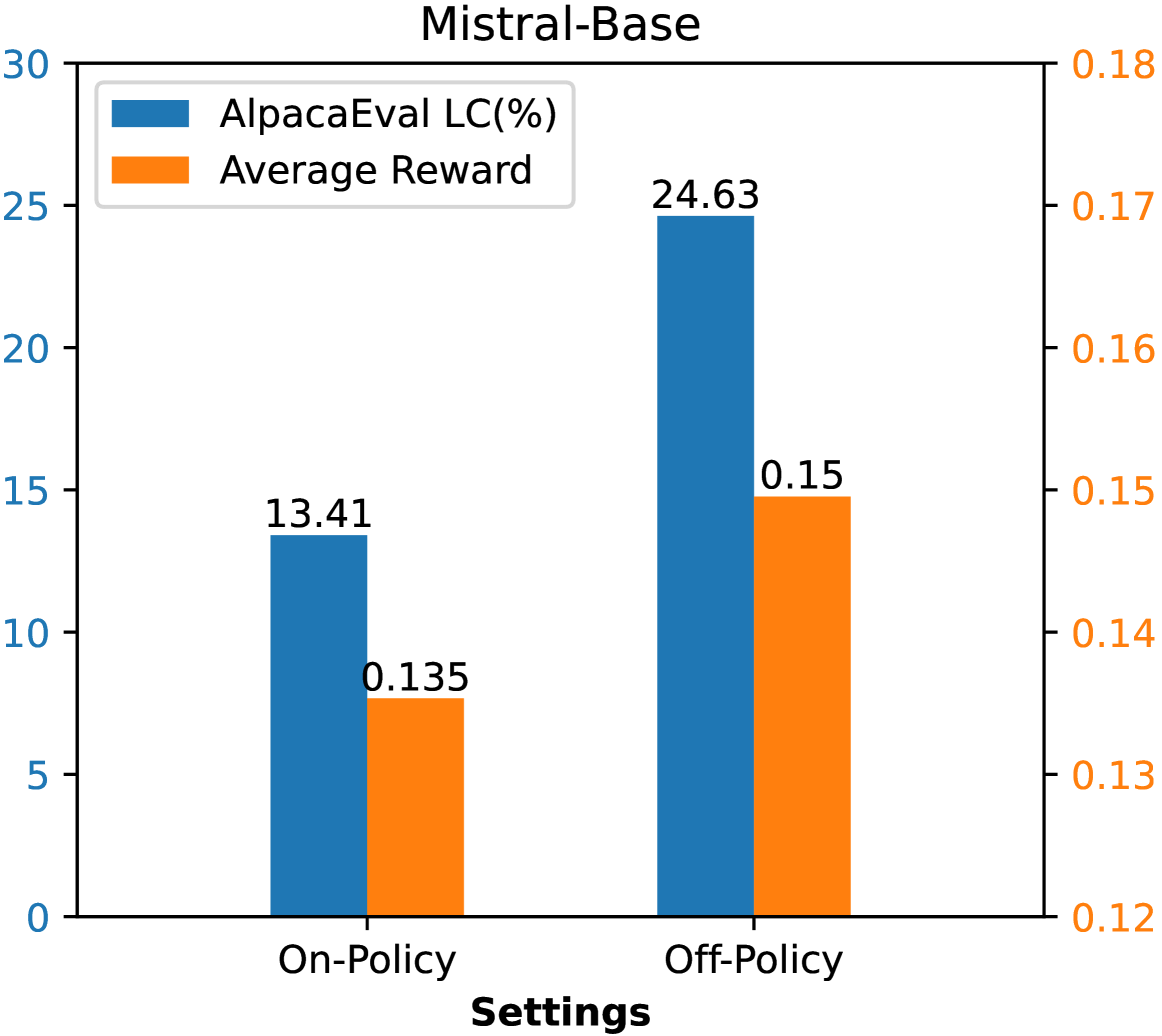
- 现有DPO方法过度依赖on-policy数据,忽略了off-policy数据在提升数据质量方面的潜力,但后者存在分布偏移问题。
- InCo-DPO通过整合on-policy和off-policy数据,动态调整二者比例,以平衡分布偏移和数据质量,实现更优的偏好优化。
- 实验表明,InCo-DPO在Alpaca-Eval 2.0和Arena-Hard基准上均优于单独使用on-policy或off-policy数据的方法,并在Arena-Hard上取得了SOTA胜率。
📝 摘要(中文)
直接偏好优化(DPO)旨在优化语言模型以对齐人类偏好。通常,使用策略模型直接生成的on-policy样本,由于其与模型具有分布一致性,能够获得更好的性能。本文指出候选偏好样本的质量是另一个关键因素。虽然on-policy数据的质量受到策略模型能力的固有约束,但off-policy数据可以来自不同的来源,在质量方面具有更大的潜力,尽管存在分布偏移。然而,当前的研究主要依赖于on-policy数据,而忽略了off-policy数据在数据质量方面的价值,这是由于分布偏移带来的挑战。在本文中,我们提出了InCo-DPO,一种通过整合on-policy和off-policy数据来合成偏好数据的高效方法,允许动态调整以平衡分布偏移和数据质量,从而找到最佳的权衡。因此,InCo-DPO克服了off-policy数据中分布偏移的限制和on-policy数据中的质量约束。我们使用Alpaca-Eval 2.0和Arena-Hard基准评估了InCo-DPO。实验结果表明,我们的方法不仅优于on-policy和off-policy数据,而且在使用Gemma-2模型和vanilla DPO的情况下,在Arena-Hard上实现了60.8%的最先进胜率。
🔬 方法详解
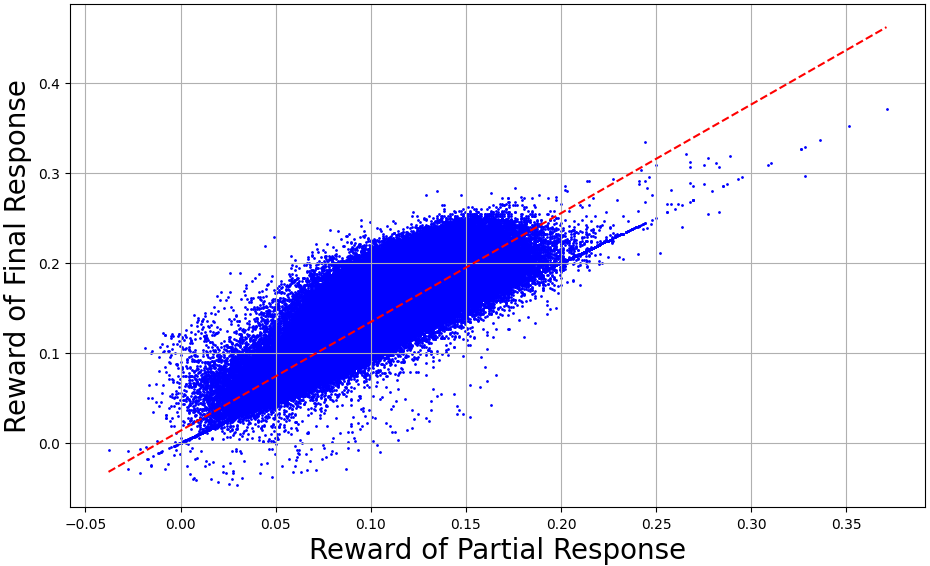
问题定义:现有直接偏好优化(DPO)方法主要依赖on-policy数据,虽然保证了分布一致性,但受限于模型自身能力,数据质量难以提升。Off-policy数据来源广泛,质量潜力更大,但存在与模型分布不一致的问题,导致训练效果不佳。因此,如何有效利用off-policy数据,在分布偏移和数据质量之间取得平衡,是本文要解决的核心问题。
核心思路:InCo-DPO的核心思路是通过动态调整on-policy和off-policy数据的比例,实现分布偏移和数据质量之间的最佳平衡。该方法认为,在训练初期,模型能力较弱,off-policy数据可以提供更高质量的监督信号;随着训练进行,模型能力提升,on-policy数据的重要性逐渐增加,以保证分布一致性。
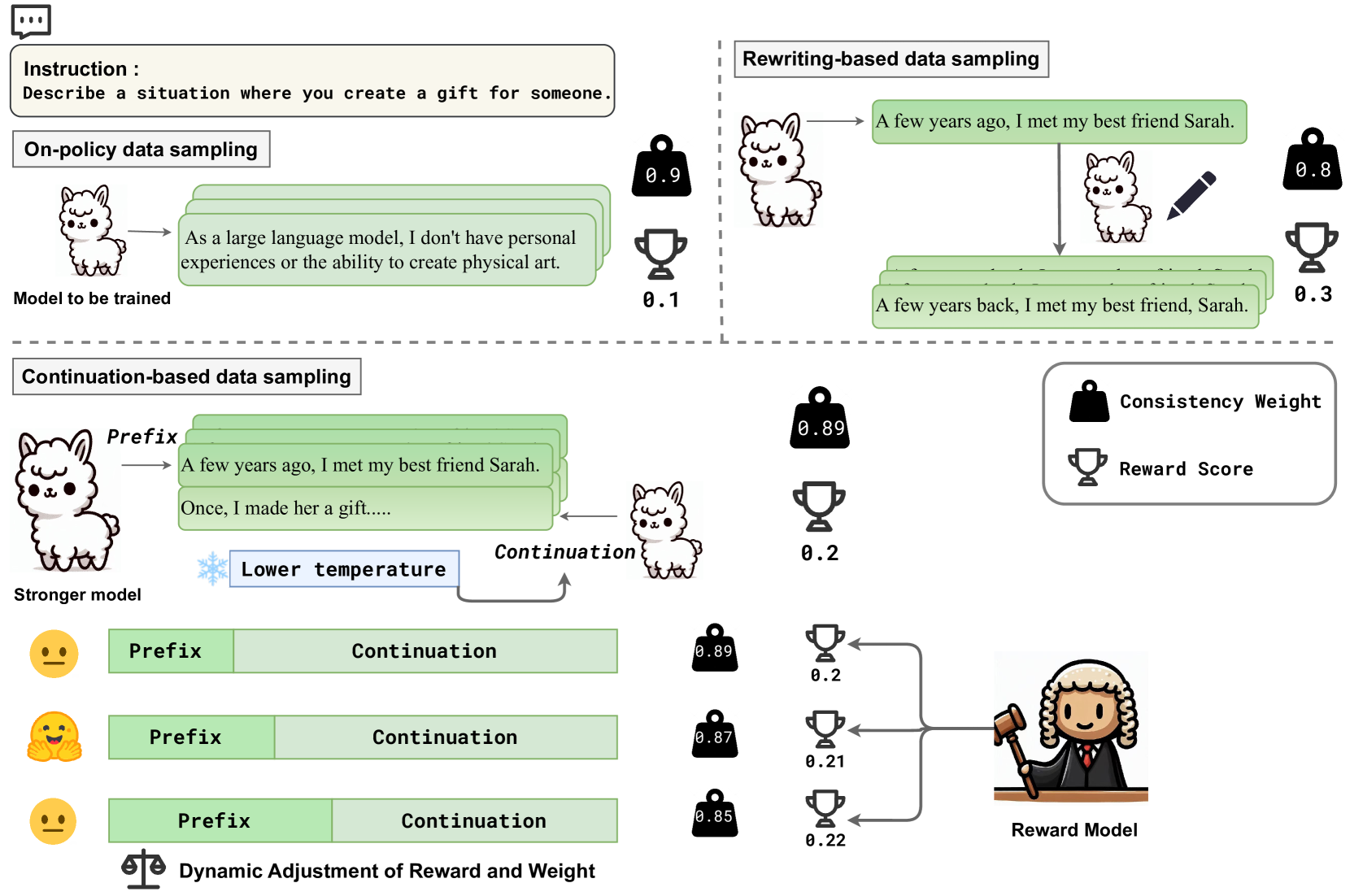
技术框架:InCo-DPO的整体框架是在标准DPO训练流程中,引入一个动态混合机制。该机制根据训练进度,自适应地调整on-policy和off-policy数据的采样比例。具体来说,在每个训练迭代中,首先从on-policy数据和off-policy数据集中分别采样一定数量的样本,然后将这些样本混合在一起,用于DPO损失函数的计算和模型参数的更新。
关键创新:InCo-DPO的关键创新在于提出了一个动态调整on-policy和off-policy数据比例的策略。与现有方法固定使用on-policy数据或简单混合on-policy和off-policy数据不同,InCo-DPO能够根据模型训练状态,自适应地调整数据比例,从而更好地平衡分布偏移和数据质量。
关键设计:InCo-DPO的关键设计在于如何确定on-policy和off-policy数据的动态混合比例。论文中可能采用了一种基于训练损失或模型性能的启发式方法,例如,当训练损失下降缓慢或模型在验证集上的性能提升停滞时,增加off-policy数据的比例,反之则增加on-policy数据的比例。具体的损失函数和网络结构与标准DPO保持一致,主要修改在于数据采样阶段。
🖼️ 关键图片
📊 实验亮点
InCo-DPO在Alpaca-Eval 2.0和Arena-Hard基准测试中均取得了显著的性能提升。特别是在Arena-Hard基准上,使用Gemma-2模型和vanilla DPO,InCo-DPO实现了60.8%的最先进胜率,超越了现有on-policy和off-policy方法,验证了其在平衡分布偏移和数据质量方面的有效性。
🎯 应用场景
InCo-DPO方法可广泛应用于各种需要对齐人类偏好的语言模型训练任务中,例如对话系统、文本生成、代码生成等。通过有效利用高质量的off-policy数据,可以显著提升模型的性能和用户体验。该方法具有很高的实际应用价值,可以帮助开发者训练出更智能、更符合人类期望的AI系统。
📄 摘要(原文)
Direct Preference Optimization (DPO) optimizes language models to align with human preferences. Utilizing on-policy samples, generated directly by the policy model, typically results in better performance due to its distribution consistency with the model compared to off-policy samples. This paper identifies the quality of candidate preference samples as another critical factor. While the quality of on-policy data is inherently constrained by the capabilities of the policy model, off-policy data, which can be derived from diverse sources, offers greater potential for quality despite experiencing distribution shifts. However, current research mostly relies on on-policy data and neglects the value of off-policy data in terms of data quality, due to the challenge posed by distribution shift. In this paper, we propose InCo-DPO, an efficient method for synthesizing preference data by integrating on-policy and off-policy data, allowing dynamic adjustments to balance distribution shifts and data quality, thus finding an optimal trade-off. Consequently, InCo-DPO overcomes the limitations of distribution shifts in off-policy data and the quality constraints of on-policy data. We evaluated InCo-DPO with the Alpaca-Eval 2.0 and Arena-Hard benchmarks. Experimental results demonstrate that our approach not only outperforms both on-policy and off-policy data but also achieves a state-of-the-art win rate of 60.8 on Arena-Hard with the vanilla DPO using Gemma-2 model.