DNR Bench: Benchmarking Over-Reasoning in Reasoning LLMs
作者: Masoud Hashemi, Oluwanifemi Bamgbose, Sathwik Tejaswi Madhusudhan, Jishnu Sethumadhavan Nair, Aman Tiwari, Vikas Yadav
分类: cs.LG
发布日期: 2025-03-20 (更新: 2025-04-18)
💡 一句话要点
DNR Bench:评估推理LLM过度推理问题的基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 过度推理 基准测试 对抗性提示 推理效率
📋 核心要点
- 大型语言模型通过测试时扩展提升了性能,但同时也导致了过多的token生成和不必要的尝试。
- DNR Bench通过对抗性设计的提示,评估LLM识别推理触发因素并避免过度推理的能力。
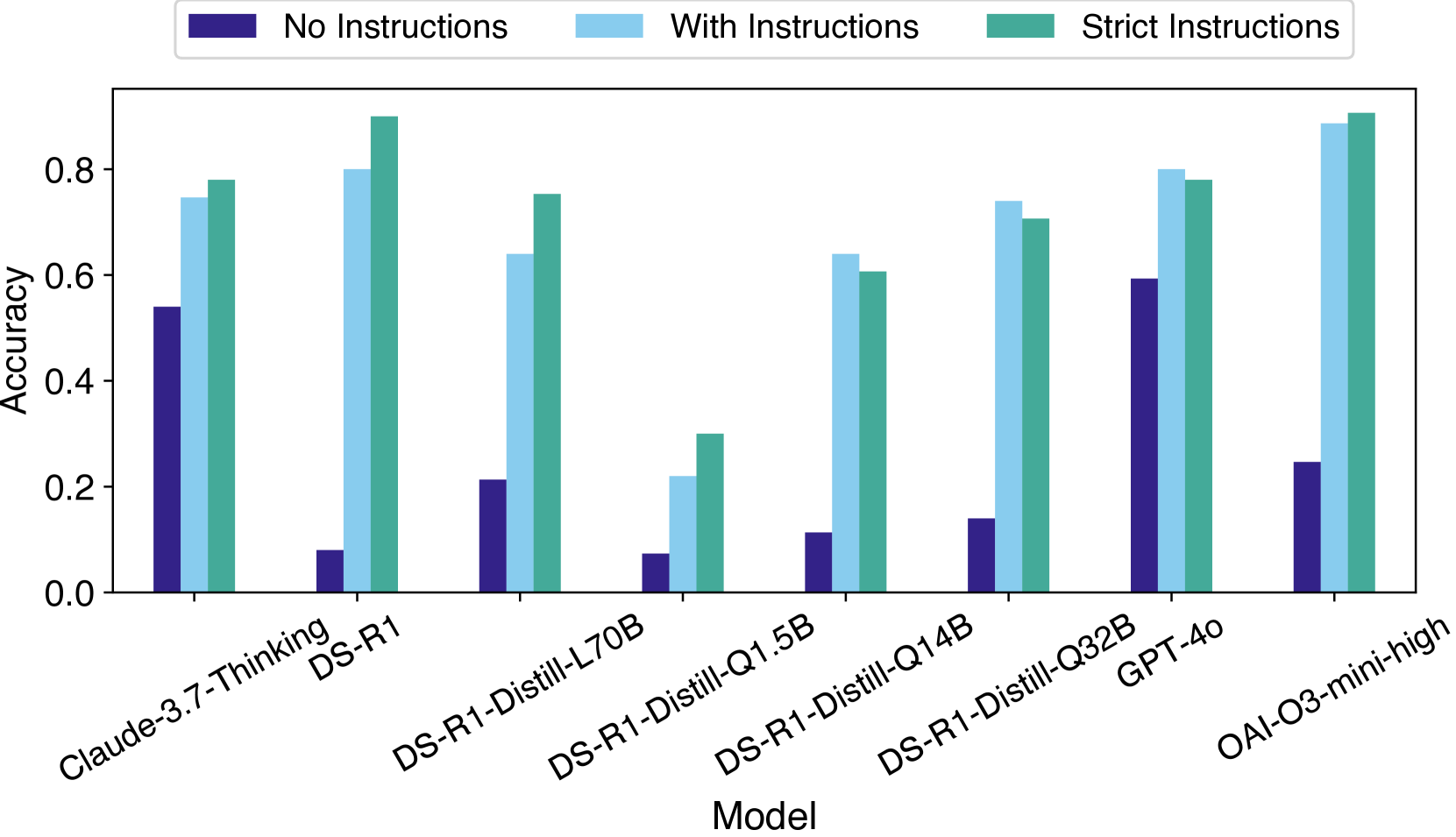
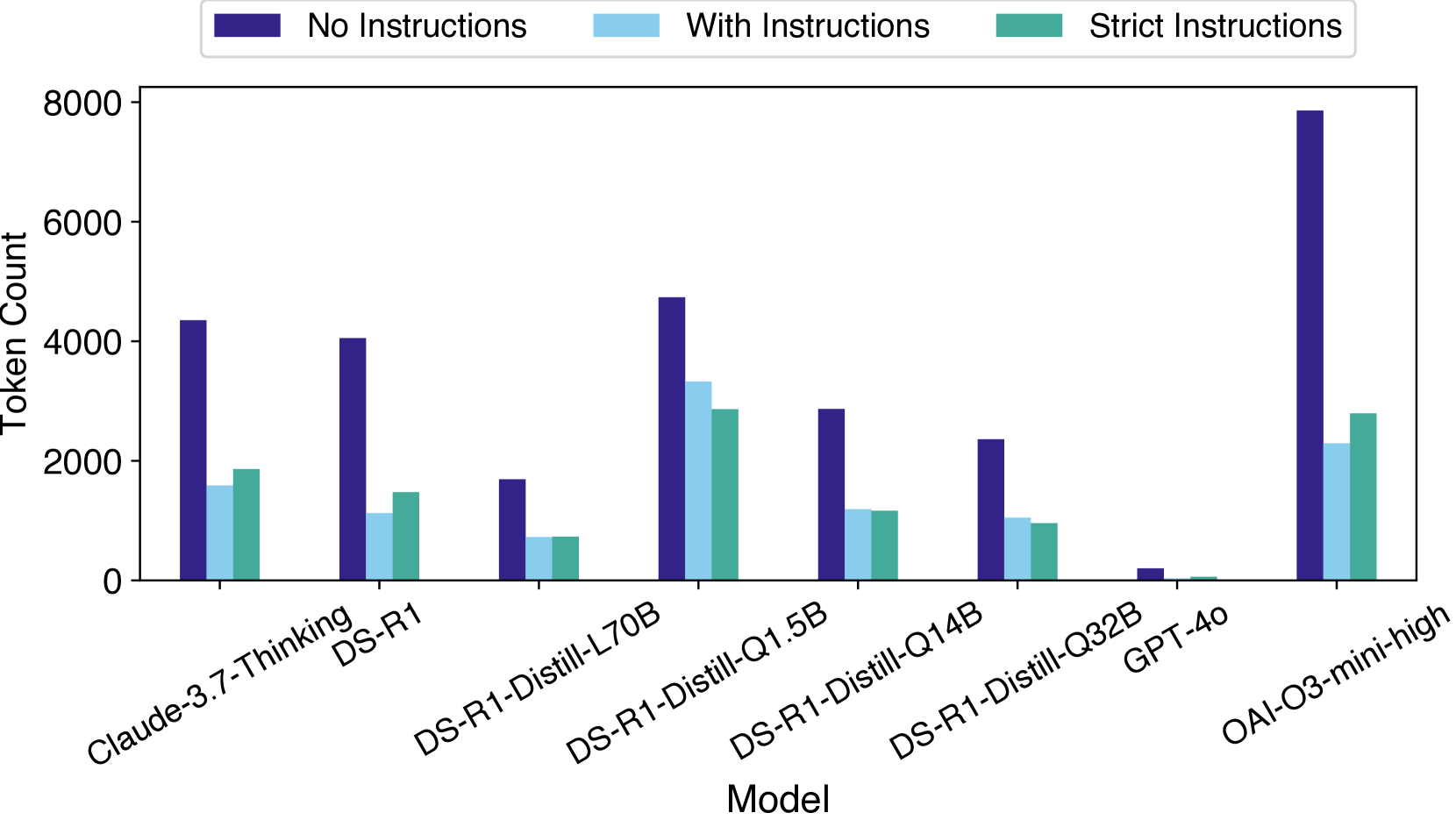
- 实验表明,推理LLM在某些任务上表现不如非推理模型,并产生大量冗余token。
📝 摘要(中文)
本文提出了Dont Reason Bench (DNR Bench),一个新的基准测试,旨在评估大型语言模型(LLM)在推理过程中对复杂触发因素的理解能力,并避免不必要的生成。DNR Bench包含150个对抗性设计的提示,这些提示对人类来说很容易理解和响应,但许多最新的LLM却难以处理。DNR Bench测试模型在指令遵循、避免幻觉、冗余过滤和无法回答问题识别等方面的能力。研究评估了推理LLM (RLM),包括DeepSeek-R1、OpenAI O3-mini、Claude-3.7-sonnet,并将它们与强大的非推理模型(如GPT-4o)进行比较。实验表明,RLM生成的token数量是不必要的token数量的70倍,并且常常无法有效地处理简单的非推理模型能够以更高的准确率处理的任务。研究结果强调了RLM中更有效的训练和推理策略的需求。
🔬 方法详解
问题定义:论文旨在解决推理型大型语言模型(RLM)在面对特定类型的提示时,过度推理的问题。现有RLM虽然具备强大的推理能力,但容易产生不必要的token,进行冗余的计算,导致效率降低,甚至在一些简单任务上表现不如非推理模型。这种过度推理的根本原因是RLM无法准确判断何时需要进行深入推理,何时应该直接给出答案或拒绝回答。
核心思路:论文的核心思路是构建一个专门用于评估LLM过度推理问题的基准测试集DNR Bench。该基准测试集包含一系列对抗性设计的提示,这些提示对人类来说非常简单,可以直接给出答案或判断为无法回答,但却容易诱导RLM进行不必要的推理。通过分析RLM在DNR Bench上的表现,可以有效评估其避免过度推理的能力。
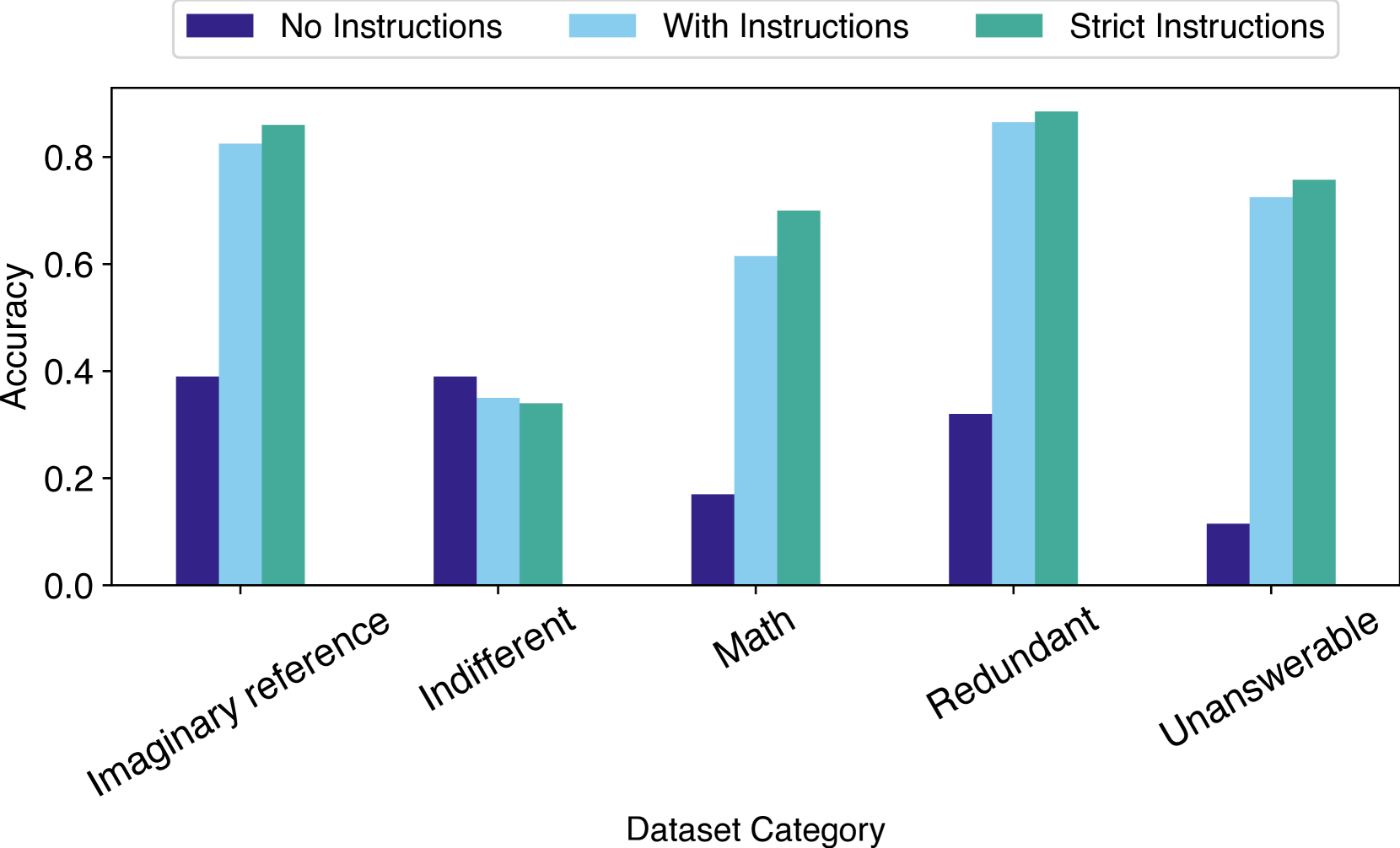
技术框架:DNR Bench基准测试集是论文的核心技术框架。它包含150个对抗性设计的提示,这些提示被分为多个类别,分别测试LLM在指令遵循、避免幻觉、冗余过滤和无法回答问题识别等方面的能力。研究人员使用DNR Bench对多个RLM(如DeepSeek-R1、OpenAI O3-mini、Claude-3.7-sonnet)和一个非推理模型(GPT-4o)进行评估,并比较它们在token生成数量、准确率等方面的表现。
关键创新:DNR Bench的关键创新在于其对抗性提示的设计。这些提示并非旨在测试LLM的推理能力上限,而是故意设计成容易诱导LLM进行过度推理的场景。这种设计使得DNR Bench能够有效地评估LLM在实际应用中避免不必要计算的能力,从而为改进RLM的训练和推理策略提供指导。
关键设计:DNR Bench中的提示设计需要仔细考虑。例如,在测试指令遵循能力时,提示可能包含一些看似需要推理,但实际上可以直接忽略的指令。在测试避免幻觉能力时,提示可能包含一些模糊或不完整的信息,容易诱导LLM生成虚假信息。在测试冗余过滤能力时,提示可能包含一些重复或矛盾的信息,需要LLM进行过滤和整合。提示的设计需要保证对人类来说简单易懂,但对LLM来说具有一定的挑战性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,推理LLM在DNR Bench上生成的token数量是不必要的token数量的70倍,远高于非推理模型GPT-4o。同时,在某些任务上,推理LLM的准确率低于GPT-4o,表明过度推理反而可能导致性能下降。这些结果突出了当前推理LLM在避免过度推理方面存在的不足,并为未来的研究方向提供了重要启示。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的推理效率,尤其是在资源受限的环境中。通过DNR Bench,可以更好地了解LLM在不同场景下的过度推理行为,从而指导模型训练和推理策略的优化,降低计算成本,提高响应速度,并减少不必要的token生成。这对于LLM在移动设备、边缘计算等场景的应用具有重要意义。
📄 摘要(原文)
Test-time scaling has significantly improved large language model performance, enabling deeper reasoning to solve complex problems. However, this increased reasoning capability also leads to excessive token generation and unnecessary problem-solving attempts. We introduce Dont Reason Bench (DNR Bench), a new benchmark designed to evaluate LLMs ability to robustly understand the tricky reasoning triggers and avoiding unnecessary generation. DNR Bench consists of 150 adversarially designed prompts that are easy for humans to understand and respond to, but surprisingly not for many of the recent prominent LLMs. DNR Bench tests models abilities across different capabilities, such as instruction adherence, hallucination avoidance, redundancy filtering, and unanswerable question recognition. We evaluate reasoning LLMs (RLMs), including DeepSeek-R1, OpenAI O3-mini, Claude-3.7-sonnet and compare them against a powerful non-reasoning model, e.g., GPT-4o. Our experiments reveal that RLMs generate up to 70x more tokens than necessary, often failing at tasks that simpler non-reasoning models handle efficiently with higher accuracy. Our findings underscore the need for more effective training and inference strategies in RLMs.