What Makes a Reward Model a Good Teacher? An Optimization Perspective
作者: Noam Razin, Zixuan Wang, Hubert Strauss, Stanley Wei, Jason D. Lee, Sanjeev Arora
分类: cs.LG, cs.AI, cs.CL, stat.ML
发布日期: 2025-03-19 (更新: 2025-09-27)
备注: Accepted to NeurIPS 2025; Code available at https://github.com/princeton-pli/what-makes-good-rm
💡 一句话要点
揭示奖励模型有效性的关键:优化视角下的方差重要性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 人类反馈强化学习 奖励模型 奖励方差 优化地形 语言模型
📋 核心要点
- 现有RLHF方法主要依赖奖励模型的准确性,忽略了其对优化过程的影响,可能导致训练效率低下。
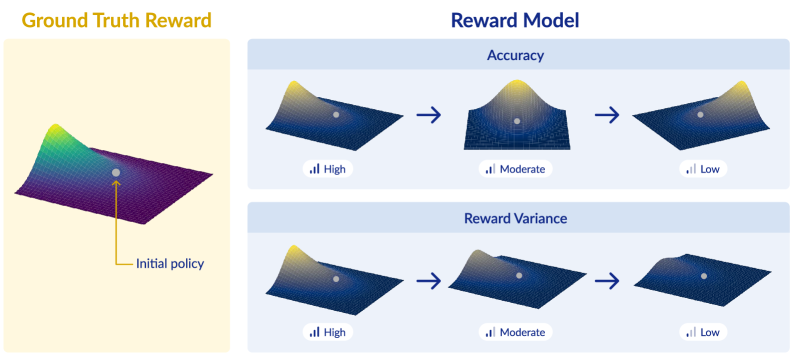
- 论文提出奖励模型不仅要准确,还要诱导足够的奖励方差,以避免优化地形过于平坦,从而加速训练。
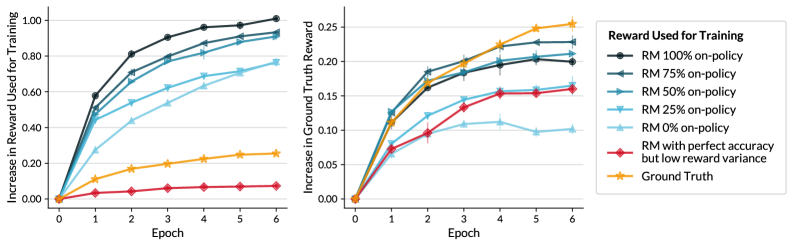
- 实验结果表明,即使准确率高的奖励模型,如果方差低,其性能可能不如方差较高的模型,验证了理论的有效性。
📝 摘要(中文)
人类反馈强化学习(RLHF)的成功很大程度上取决于奖励模型的质量。虽然奖励模型的质量主要通过准确性来评估,但准确性是否完全捕捉了奖励模型作为有效教师的全部要素尚不清楚。本文从优化的角度探讨了这个问题。首先,我们证明,无论奖励模型多么准确,如果它导致低奖励方差,那么RLHF目标函数将呈现平坦的优化地形。因此,即使是完全准确的奖励模型也可能导致极慢的优化速度,甚至表现不如方差较高的不太准确的模型。此外,我们还表明,对于一个语言模型有效的奖励模型,可能对另一个语言模型产生较低的奖励方差,从而导致平坦的优化地形。这些结果确立了仅基于准确性或独立于其指导的语言模型来评估奖励模型的根本局限性。使用高达80亿参数的模型进行的实验证实了我们的理论,证明了奖励方差、准确性和奖励最大化率之间的相互作用。总的来说,我们的研究结果强调,除了准确性之外,奖励模型还需要诱导足够的方差才能实现有效的优化。
🔬 方法详解
问题定义:现有的人类反馈强化学习(RLHF)方法主要依赖奖励模型的准确性来评估其质量。然而,仅仅关注准确性忽略了奖励模型对后续强化学习优化过程的影响。一个高准确率但低方差的奖励模型可能导致优化地形平坦,使得强化学习智能体难以探索和学习,最终导致训练效率低下甚至无法收敛。因此,如何评估奖励模型作为“教师”的有效性,以及如何设计更好的奖励模型,是本文要解决的核心问题。
核心思路:本文的核心思路是,从优化的角度重新审视奖励模型的作用。作者认为,一个好的奖励模型不仅要准确地反映人类的偏好,还要能够提供足够的奖励方差,从而避免优化地形过于平坦。奖励方差可以促进强化学习智能体进行有效的探索,并加速学习过程。因此,奖励模型的有效性应该同时考虑其准确性和奖励方差。
技术框架:本文主要通过理论分析和实验验证来支持其观点。理论分析部分,作者证明了低奖励方差会导致RLHF目标函数的平坦优化地形。实验部分,作者使用不同大小的语言模型和奖励模型,评估了奖励模型的准确性、奖励方差以及强化学习的训练效果。通过控制奖励模型的方差,观察其对训练速度和最终性能的影响。
关键创新:本文最重要的技术创新在于,提出了奖励方差是评估奖励模型有效性的一个关键指标。以往的研究主要关注奖励模型的准确性,而忽略了其对优化过程的影响。本文首次从优化的角度揭示了奖励方差的重要性,并证明了低奖励方差会导致优化困难。这一发现为设计更好的奖励模型提供了新的思路。
关键设计:本文并没有提出具体的奖励模型设计方案,而是侧重于理论分析和实验验证。在实验中,作者通过调整奖励模型的输出范围或添加噪声等方式来控制奖励方差。此外,作者还分析了不同语言模型对奖励方差的影响,发现一个语言模型上有效的奖励模型,可能在另一个语言模型上产生较低的奖励方差。这些实验设计旨在验证奖励方差对强化学习训练效果的影响。
🖼️ 关键图片
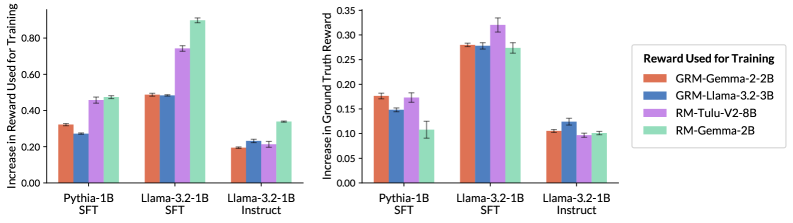
📊 实验亮点
实验结果表明,即使奖励模型具有较高的准确性,如果其奖励方差较低,则RLHF的训练效果可能较差,甚至不如准确性较低但方差较高的奖励模型。使用高达80亿参数的模型进行的实验验证了奖励方差、准确性和奖励最大化率之间的相互作用,证实了理论分析的有效性。
🎯 应用场景
该研究成果可应用于改进人类反馈强化学习(RLHF)的训练过程,通过设计能够产生足够奖励方差的奖励模型,提高语言模型等人工智能系统的训练效率和性能。此外,该研究也为奖励模型的设计和评估提供了新的思路和方法。
📄 摘要(原文)
The success of Reinforcement Learning from Human Feedback (RLHF) critically depends on the quality of the reward model. However, while this quality is primarily evaluated through accuracy, it remains unclear whether accuracy fully captures what makes a reward model an effective teacher. We address this question from an optimization perspective. First, we prove that regardless of how accurate a reward model is, if it induces low reward variance, then the RLHF objective suffers from a flat landscape. Consequently, even a perfectly accurate reward model can lead to extremely slow optimization, underperforming less accurate models that induce higher reward variance. We additionally show that a reward model that works well for one language model can induce low reward variance, and thus a flat objective landscape, for another. These results establish a fundamental limitation of evaluating reward models solely based on accuracy or independently of the language model they guide. Experiments using models of up to 8B parameters corroborate our theory, demonstrating the interplay between reward variance, accuracy, and reward maximization rate. Overall, our findings highlight that beyond accuracy, a reward model needs to induce sufficient variance for efficient~optimization.