1000 Layer Networks for Self-Supervised RL: Scaling Depth Can Enable New Goal-Reaching Capabilities
作者: Kevin Wang, Ishaan Javali, Michał Bortkiewicz, Tomasz Trzciński, Benjamin Eysenbach
分类: cs.LG, cs.AI
发布日期: 2025-03-19 (更新: 2025-11-23)
备注: Link to project website: https://wang-kevin3290.github.io/scaling-crl/
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
通过扩展深度至1000层,提升自监督强化学习在目标导向任务中的性能。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自监督学习 强化学习 深度学习 目标导向 机器人控制
📋 核心要点
- 现有强化学习方法依赖浅层网络,限制了其在复杂任务中的性能和可扩展性。
- 论文提出通过大幅增加神经网络深度(高达1024层)来提升自监督强化学习的效果。
- 实验表明,在无监督目标条件下,深层网络显著提高了智能体在运动和操作任务中的成功率。
📝 摘要(中文)
自监督学习的扩展推动了语言和视觉领域的突破,但强化学习(RL)中类似进展仍然难以实现。本文研究了自监督RL的构建模块,这些模块可以显著提高可扩展性,其中网络深度是一个关键因素。近年来,大多数RL论文都依赖于浅层架构(大约2-5层),而本文证明,将深度增加到1024层可以显著提高性能。实验在一个无监督的目标条件环境中进行,不提供演示或奖励,因此智能体必须(从头开始)探索并学习如何最大化达到指定目标的可能性。在模拟的运动和操作任务中评估,该方法将自监督对比RL算法的性能提高了2倍-50倍,优于其他目标条件基线。增加模型深度不仅提高了成功率,而且从根本上改变了学习到的行为。
🔬 方法详解
问题定义:论文旨在解决自监督强化学习中,智能体在复杂、无奖励环境中难以有效探索和学习目标导向行为的问题。现有方法通常采用浅层神经网络,表达能力有限,难以捕捉复杂环境中的长期依赖关系,导致学习效率低下和性能瓶颈。
核心思路:论文的核心思路是,通过大幅增加神经网络的深度,提升模型对环境的建模能力和策略学习能力。深层网络能够学习到更抽象、更高级别的特征表示,从而更好地理解环境状态和目标之间的关系,指导智能体进行有效的探索和决策。
技术框架:整体框架基于自监督对比强化学习,智能体在没有外部奖励信号的情况下,通过最大化达到指定目标的可能性来学习。具体流程包括:1) 智能体与环境交互,收集经验数据;2) 使用深层神经网络对经验数据进行编码,学习状态表示;3) 通过对比学习,训练模型区分不同的状态和目标;4) 使用学习到的状态表示,训练策略网络,指导智能体进行目标导向的动作选择。
关键创新:最重要的技术创新点在于,证明了在自监督强化学习中,大幅增加神经网络的深度可以带来显著的性能提升。这与以往强化学习研究中普遍采用浅层网络的做法形成鲜明对比,揭示了深度在强化学习中的重要作用。
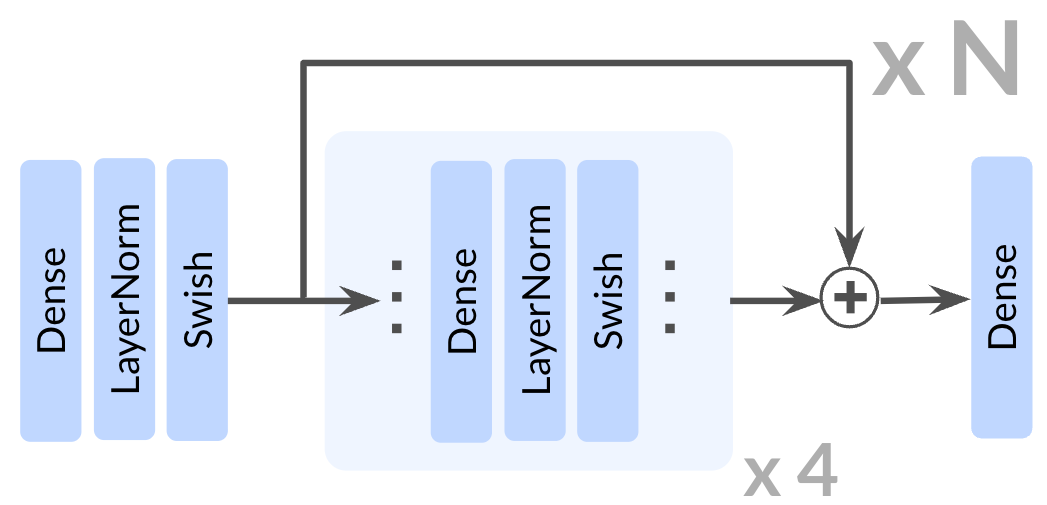
关键设计:论文采用了高达1024层的神经网络,并针对深层网络的训练问题,可能采用了残差连接、批量归一化等技术。损失函数方面,采用了对比损失函数,鼓励模型学习到区分不同状态和目标的表示。具体的网络结构和参数设置在论文中应该有详细描述(未知)。
🖼️ 关键图片
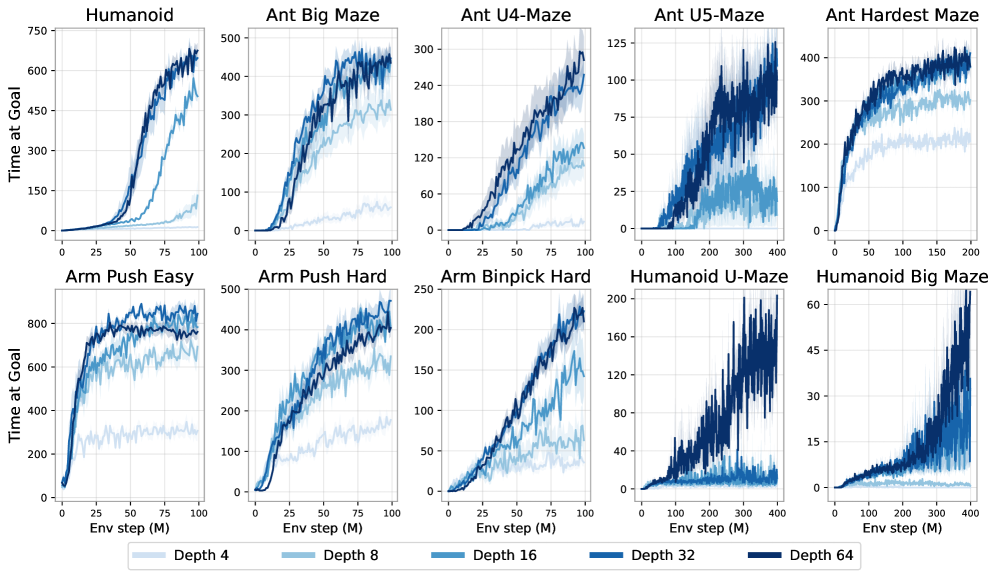

📊 实验亮点
实验结果表明,在模拟的运动和操作任务中,使用1024层深层网络的自监督对比RL算法的性能提高了2倍-50倍,显著优于其他目标条件基线。这表明,增加模型深度不仅提高了成功率,而且从根本上改变了学习到的行为,使智能体能够学习到更复杂、更有效的策略。
🎯 应用场景
该研究成果可应用于机器人控制、游戏AI、自动驾驶等领域。通过深层自监督强化学习,可以训练智能体在复杂、无奖励或稀疏奖励的环境中自主学习完成各种任务,例如机器人自主导航、物体操作、游戏策略学习等。未来,该技术有望推动智能体在更广泛的应用场景中实现自主学习和智能决策。
📄 摘要(原文)
Scaling up self-supervised learning has driven breakthroughs in language and vision, yet comparable progress has remained elusive in reinforcement learning (RL). In this paper, we study building blocks for self-supervised RL that unlock substantial improvements in scalability, with network depth serving as a critical factor. Whereas most RL papers in recent years have relied on shallow architectures (around 2 - 5 layers), we demonstrate that increasing the depth up to 1024 layers can significantly boost performance. Our experiments are conducted in an unsupervised goal-conditioned setting, where no demonstrations or rewards are provided, so an agent must explore (from scratch) and learn how to maximize the likelihood of reaching commanded goals. Evaluated on simulated locomotion and manipulation tasks, our approach increases performance on the self-supervised contrastive RL algorithm by $2\times$ - $50\times$, outperforming other goal-conditioned baselines. Increasing the model depth not only increases success rates but also qualitatively changes the behaviors learned. The project webpage and code can be found here: https://wang-kevin3290.github.io/scaling-crl/.