DashCLIP: Leveraging multimodal models for generating semantic embeddings for DoorDash
作者: Omkar Gurjar, Kin Sum Liu, Praveen Kolli, Utsaw Kumar, Mandar Rahurkar
分类: cs.IR, cs.LG
发布日期: 2025-03-18 (更新: 2025-11-06)
💡 一句话要点
DashCLIP:利用多模态模型为DoorDash生成语义嵌入,提升产品理解和用户意图识别
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 对比学习 语义嵌入 自然语言处理 推荐系统 LLM 电商 用户意图理解
📋 核心要点
- 现有视觉-语言模型难以捕捉产品和用户意图之间细微关系,导致语义表示质量不高。
- 提出联合训练框架,通过对比学习对齐单模态和多模态编码器,提升语义表示能力。
- 实验表明,该方法在产品分类、相关性预测和个性化广告推荐方面均有显著提升。
📝 摘要(中文)
尽管视觉-语言模型在各种生成任务中取得了成功,但由于现有模型无法捕捉实体之间细微的关系,因此获得高质量的产品和用户意图的语义表示仍然具有挑战性。本文提出了一种联合训练框架,通过图像-文本数据的对比学习来对齐产品和用户查询的单模态和多模态编码器。该方法使用LLM策划的相关性数据集训练查询编码器,无需依赖用户互动历史。这些嵌入表现出强大的泛化能力,并提高了产品分类和相关性预测等应用中的性能。在个性化广告推荐方面,部署后点击率和转化率的显著提升进一步证实了其对关键业务指标的影响。我们相信,该框架的灵活性使其成为丰富电子商务领域用户体验的有前景的解决方案。
🔬 方法详解
问题定义:论文旨在解决电商平台(如DoorDash)中,如何为产品和用户查询生成高质量语义嵌入的问题。现有方法,特别是直接使用预训练的视觉-语言模型,无法充分捕捉产品和用户意图之间细微而重要的关系,导致下游任务(如产品分类、相关性预测)效果不佳。现有方法依赖用户互动历史,存在冷启动问题。
核心思路:论文的核心思路是通过联合训练产品和用户查询的编码器,使其能够更好地理解图像和文本信息,并捕捉它们之间的相关性。通过对比学习,将单模态(图像或文本)和多模态(图像-文本对)的编码器对齐,从而学习到更鲁棒和泛化的语义表示。使用LLM生成相关性数据集,避免依赖用户历史数据。
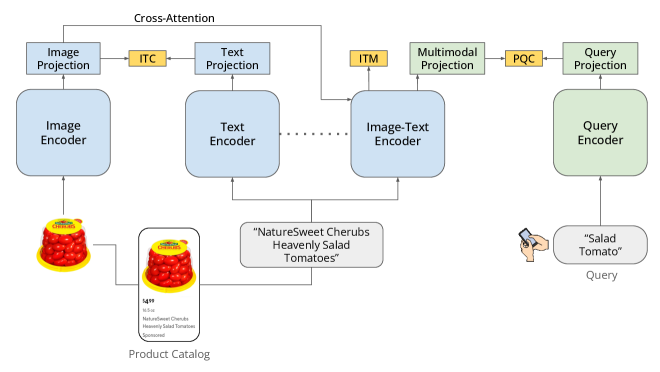
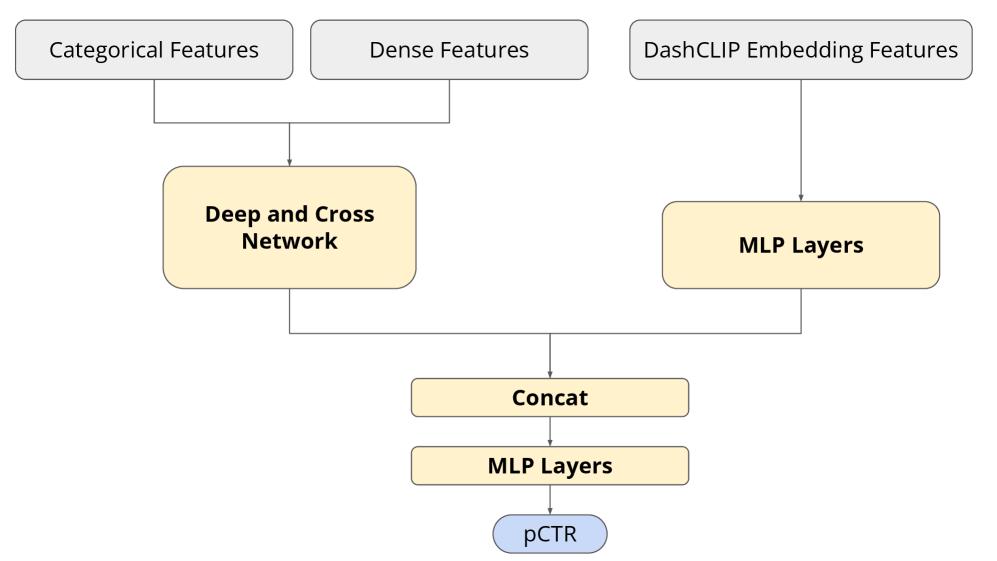
技术框架:整体框架包含以下几个主要模块:1) 产品图像编码器;2) 产品文本编码器;3) 用户查询编码器。这些编码器可以是Transformer或其他类型的神经网络。训练过程包括:a) 使用图像-文本数据进行对比学习,对齐产品图像和文本的嵌入空间;b) 使用LLM生成的相关性数据集训练用户查询编码器,使其能够预测查询与产品之间的相关性。
关键创新:该论文的关键创新在于:1) 提出了一种联合训练框架,能够同时优化产品和用户查询的语义嵌入;2) 使用LLM生成相关性数据集,解决了冷启动问题,避免了对用户互动历史的依赖;3) 通过对比学习对齐单模态和多模态编码器,提升了语义表示的鲁棒性和泛化能力。
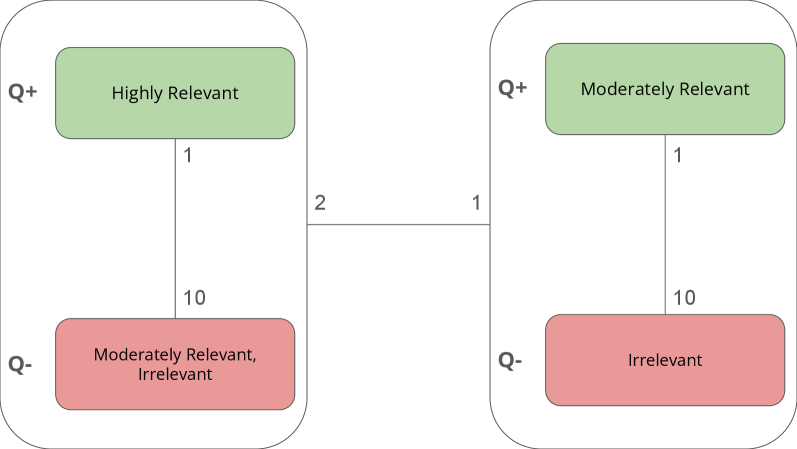
关键设计:论文使用对比损失函数来对齐不同模态的嵌入空间。具体来说,对于每个图像-文本对,目标是使图像和文本的嵌入向量尽可能接近,同时使它们与其他不相关的图像和文本的嵌入向量尽可能远离。LLM生成相关性数据集时,使用了特定的prompt工程来确保生成的数据集质量。用户查询编码器的训练使用了交叉熵损失函数,目标是预测查询与产品之间的相关性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在产品分类和相关性预测任务中均取得了显著的性能提升。在个性化广告推荐方面,部署后点击率和转化率分别提升了显著百分比(具体数值未知),证实了该方法对关键业务指标的积极影响。该方法无需依赖用户历史数据,解决了冷启动问题。
🎯 应用场景
该研究成果可广泛应用于电商平台的搜索、推荐、广告等场景。通过提升产品和用户意图的语义理解,可以提高搜索结果的相关性、推荐的准确性和广告的点击率,从而改善用户体验,提升平台收益。该方法还可以扩展到其他领域,例如图像检索、文本分类等。
📄 摘要(原文)
Despite the success of vision-language models in various generative tasks, obtaining high-quality semantic representations for products and user intents is still challenging due to the inability of off-the-shelf models to capture nuanced relationships between the entities. In this paper, we introduce a joint training framework for product and user queries by aligning uni-modal and multi-modal encoders through contrastive learning on image-text data. Our novel approach trains a query encoder with an LLM-curated relevance dataset, eliminating the reliance on engagement history. These embeddings demonstrate strong generalization capabilities and improve performance across applications, including product categorization and relevance prediction. For personalized ads recommendation, a significant uplift in the click-through rate and conversion rate after the deployment further confirms the impact on key business metrics. We believe that the flexibility of our framework makes it a promising solution toward enriching the user experience across the e-commerce landscape.