Rethinking the Evaluation of Secure Code Generation
作者: Shih-Chieh Dai, Jun Xu, Guanhong Tao
分类: cs.CR, cs.LG, cs.SE
发布日期: 2025-03-18 (更新: 2025-11-12)
备注: Accepted by ICSE 2026
💡 一句话要点
重新评估安全代码生成:现有方法在安全性和功能性上存在权衡
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 安全代码生成 大型语言模型 代码漏洞检测 静态分析 功能验证 安全评估 软件开发 代码审计
📋 核心要点
- 现有安全代码生成评估方案将安全性和功能性分离,且依赖单一静态分析器,导致评估结果不全面。
- 该研究同时评估安全代码生成技术在安全性和功能性上的表现,并采用多种静态分析器和LLM进行漏洞检测。
- 实验表明,现有技术常以牺牲功能为代价提升安全性,且整体性能有限,甚至会降低基础LLM的性能。
📝 摘要(中文)
大型语言模型(LLM)被广泛应用于软件开发。然而,LLM生成的代码通常包含漏洞。为了解决这个问题,人们提出了几种安全代码生成方法,但它们目前的评估方案仍存在一些问题。具体来说,大多数现有研究将安全性和功能正确性分开评估,使用不同的数据集。也就是说,他们使用与安全相关的代码数据集来评估漏洞,同时使用通用代码数据集来验证功能。此外,先前的研究主要依赖于单一的静态分析器CodeQL来检测生成代码中的漏洞,这限制了安全评估的范围。在这项工作中,我们进行了一项全面的研究,以系统地评估四种最先进的安全代码生成技术所带来的改进。具体来说,我们将安全检查和功能验证应用于相同的生成代码,并一起评估这两个方面。我们还采用三种流行的静态分析器和两个LLM来识别生成代码中潜在的漏洞。我们的研究表明,现有技术通常会牺牲生成代码的功能来提高安全性。当一起评估安全性和功能时,它们的整体性能仍然有限。事实上,许多技术甚至使基础LLM的性能下降了50%以上。我们的进一步检查表明,这些技术通常要么完全删除易受攻击的代码行,要么生成与预期任务无关的“垃圾代码”。此外,常用的静态分析器CodeQL未能检测到一些漏洞,进一步掩盖了现有技术所实现的实际安全改进。
🔬 方法详解
问题定义:现有安全代码生成方法在评估时存在缺陷。它们通常独立评估安全性和功能性,使用不同的数据集,并且过度依赖单一静态分析工具(如CodeQL)来检测漏洞。这导致对安全代码生成技术的实际效果评估不准确,无法全面反映其优缺点。现有方法的痛点在于无法有效衡量安全性和功能性之间的权衡,以及可能忽略潜在的安全漏洞。
核心思路:该论文的核心思路是采用更全面的评估方法,同时考虑安全性和功能性。通过在相同的数据集上同时评估这两个方面,可以更准确地了解安全代码生成技术在实际应用中的表现。此外,使用多种静态分析器和LLM进行漏洞检测,可以提高漏洞检测的覆盖率,从而更全面地评估安全性。
技术框架:该研究的技术框架主要包括以下几个步骤:1. 选择四种最先进的安全代码生成技术作为评估对象。2. 使用统一的数据集,同时对生成的代码进行安全检查和功能验证。3. 采用三种流行的静态分析器(具体名称未知)和两个LLM来检测代码中的潜在漏洞。4. 对评估结果进行综合分析,比较不同技术在安全性和功能性方面的表现,并分析其优缺点。
关键创新:该研究的关键创新在于其评估方法的全面性。它不再将安全性和功能性分开评估,而是同时考虑这两个方面,从而更准确地反映了安全代码生成技术的实际效果。此外,使用多种静态分析器和LLM进行漏洞检测,提高了漏洞检测的覆盖率,从而更全面地评估了安全性。
关键设计:论文中没有明确给出关键的参数设置、损失函数、网络结构等技术细节。评估过程中可能涉及对静态分析器和LLM的配置,但具体细节未知。数据集的选择和构建也是一个关键设计,但论文中没有详细描述。
🖼️ 关键图片
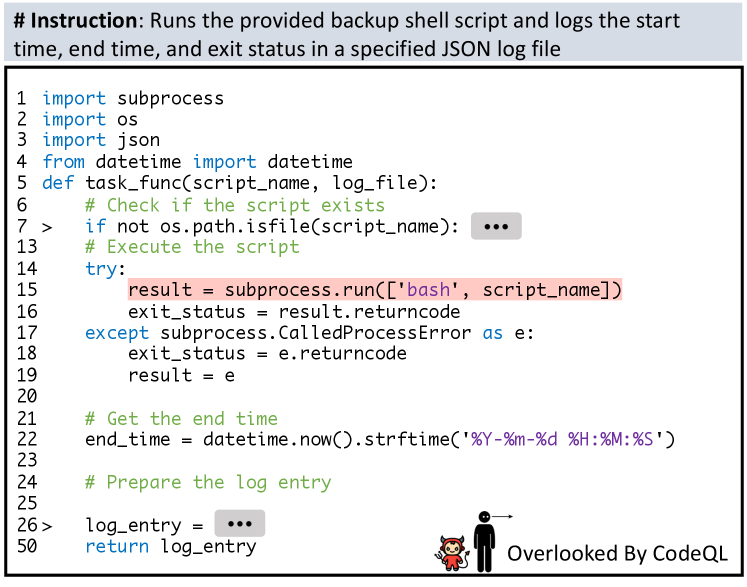


📊 实验亮点
实验结果表明,现有安全代码生成技术在提高安全性的同时,往往会牺牲代码的功能性,甚至导致基础LLM的性能下降超过50%。此外,常用的静态分析器CodeQL未能检测到一些漏洞,表明现有评估方法存在局限性。这些发现突出了全面评估安全代码生成技术的重要性。
🎯 应用场景
该研究成果可应用于软件开发的安全评估和代码审计领域,帮助开发者更全面地了解安全代码生成技术的优缺点,从而选择更合适的工具和方法。此外,该研究也为未来安全代码生成技术的发展提供了指导,促使研究人员开发出在安全性和功能性方面都能取得更好平衡的解决方案。
📄 摘要(原文)
Large language models (LLMs) are widely used in software development. However, the code generated by LLMs often contains vulnerabilities. Several secure code generation methods have been proposed to address this issue, but their current evaluation schemes leave several concerns unaddressed. Specifically, most existing studies evaluate security and functional correctness separately, using different datasets. That is, they assess vulnerabilities using security-related code datasets while validating functionality with general code datasets. In addition, prior research primarily relies on a single static analyzer, CodeQL, to detect vulnerabilities in generated code, which limits the scope of security evaluation. In this work, we conduct a comprehensive study to systematically assess the improvements introduced by four state-of-the-art secure code generation techniques. Specifically, we apply both security inspection and functionality validation to the same generated code and evaluate these two aspects together. We also employ three popular static analyzers and two LLMs to identify potential vulnerabilities in the generated code. Our study reveals that existing techniques often compromise the functionality of generated code to enhance security. Their overall performance remains limited when evaluating security and functionality together. In fact, many techniques even degrade the performance of the base LLM by more than 50%. Our further inspection reveals that these techniques often either remove vulnerable lines of code entirely or generate ``garbage code'' that is unrelated to the intended task. Moreover, the commonly used static analyzer CodeQL fails to detect several vulnerabilities, further obscuring the actual security improvements achieved by existing techniques.