DAPO: An Open-Source LLM Reinforcement Learning System at Scale
作者: Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, Wei-Ying Ma, Ya-Qin Zhang, Lin Yan, Mu Qiao, Yonghui Wu, Mingxuan Wang
分类: cs.LG, cs.CL
发布日期: 2025-03-18 (更新: 2025-05-20)
备注: Project Page: https://dapo-sia.github.io/
💡 一句话要点
DAPO:一个大规模LLM强化学习开源系统,在AIME 2024上达到50分
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 大型语言模型 开源系统 策略优化 解耦裁剪 动态采样 AIME Qwen2.5
📋 核心要点
- 现有先进推理LLM的关键技术细节被隐藏,社区难以复现其强化学习训练结果。
- 提出解耦裁剪和动态采样策略优化(DAPO)算法,并开源大规模强化学习系统。
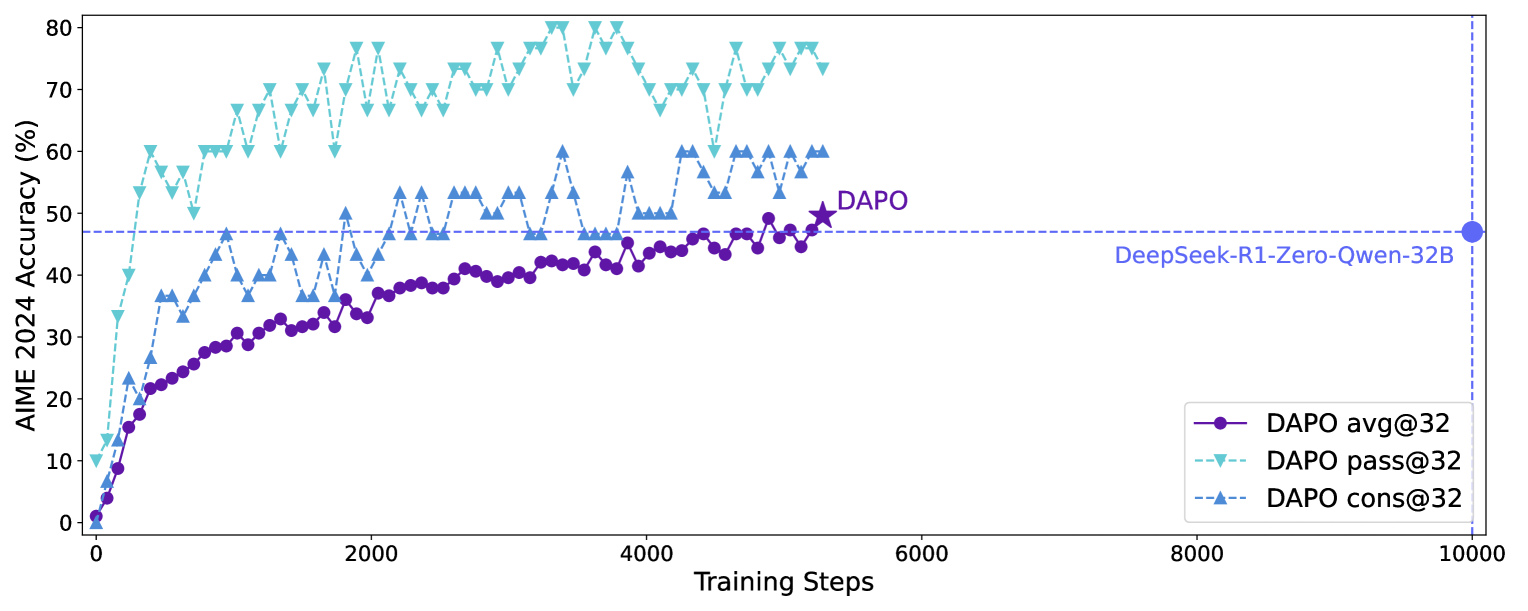
- 使用Qwen2.5-32B模型,在AIME 2024上达到50分,验证了所提方法和系统的有效性。
📝 摘要(中文)
本文提出了解耦裁剪和动态采样策略优化(DAPO)算法,并完全开源了一个最先进的大规模强化学习系统,该系统使用Qwen2.5-32B基础模型在AIME 2024上达到了50分。与之前隐藏训练细节的工作不同,本文介绍了算法的四个关键技术,这些技术使大规模LLM强化学习取得成功。此外,本文还开源了基于verl框架构建的训练代码,以及精心策划和处理的数据集。该开源系统的这些组成部分增强了可重复性,并支持未来对大规模LLM强化学习的研究。
🔬 方法详解
问题定义:现有先进推理LLM的强化学习训练细节不公开,导致研究人员难以复现和进一步改进这些模型。这阻碍了社区对大规模LLM强化学习的理解和发展。因此,需要一个开源的、可复现的系统,以及详细的算法描述,以促进该领域的研究。
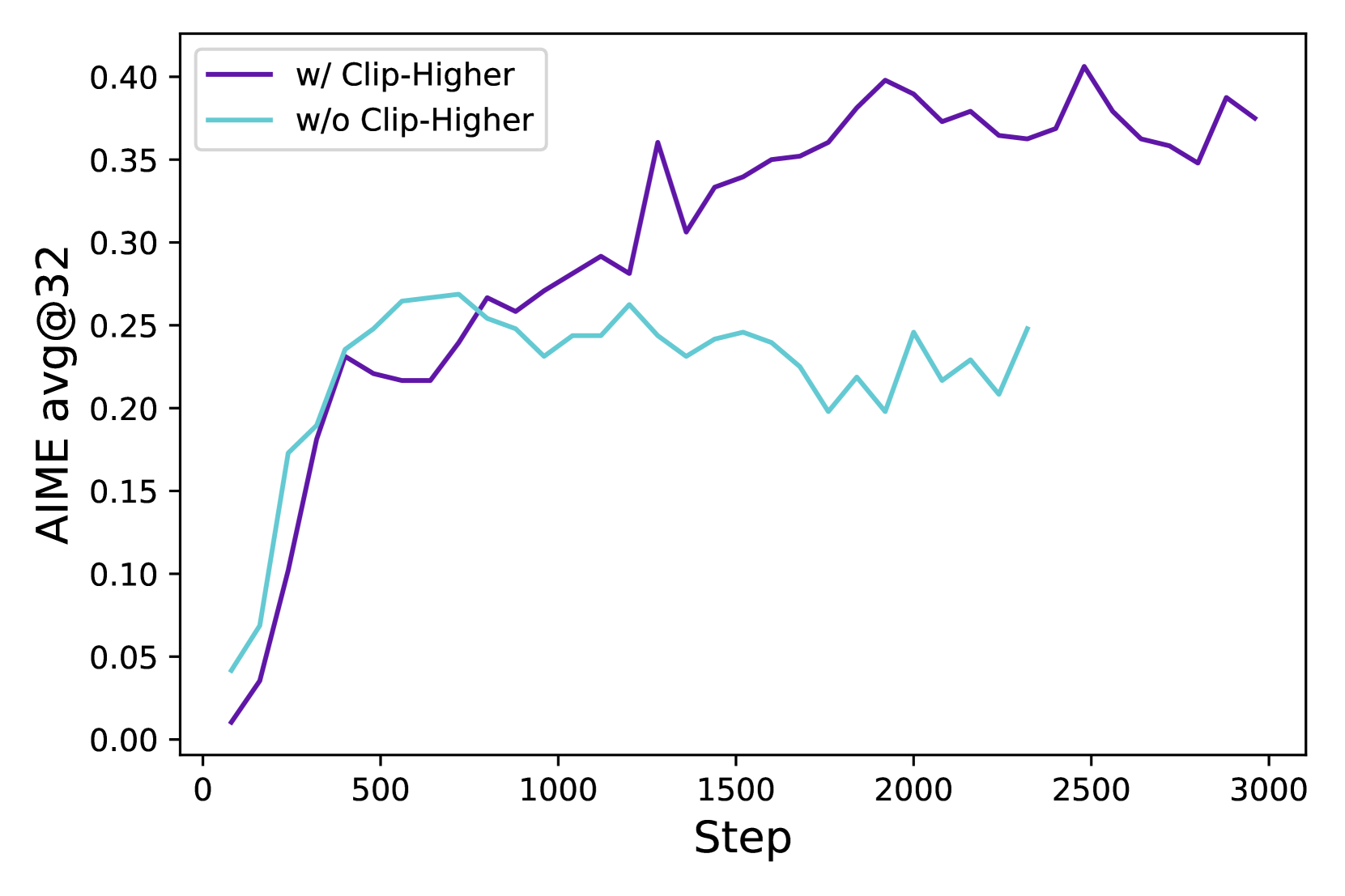
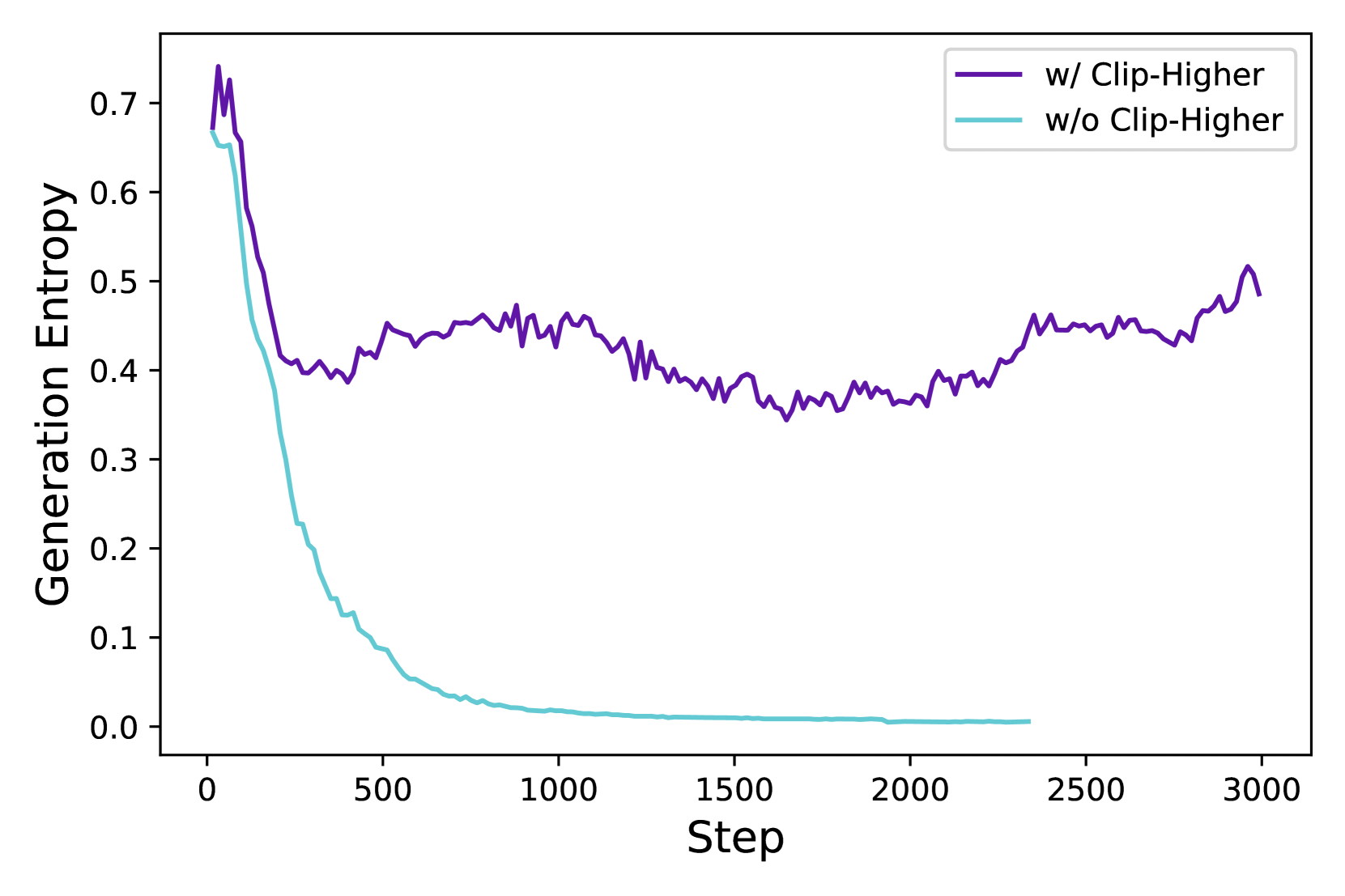
核心思路:DAPO算法的核心思路是通过解耦裁剪和动态采样来优化策略,从而提高强化学习的效率和稳定性。解耦裁剪旨在减少策略更新过程中的方差,而动态采样则根据策略的性能动态调整采样分布,从而更有效地探索状态空间。
技术框架:DAPO系统基于verl框架构建,包含以下主要模块:1) 环境交互模块,负责与环境进行交互,收集训练数据;2) 策略模型,使用Qwen2.5-32B作为基础模型,负责生成动作;3) 奖励模型,用于评估动作的质量;4) 策略优化模块,使用DAPO算法更新策略模型。
关键创新:DAPO算法的关键创新在于其解耦裁剪和动态采样的策略优化方法。解耦裁剪通过将策略更新分解为多个独立的步骤,减少了更新过程中的方差,提高了训练的稳定性。动态采样则根据策略的性能动态调整采样分布,从而更有效地探索状态空间,加速了训练过程。
关键设计:DAPO算法的关键设计包括:1) 解耦裁剪的具体实现方式,例如如何将策略更新分解为多个步骤;2) 动态采样的具体实现方式,例如如何根据策略的性能调整采样分布;3) 奖励模型的选择和训练方法;4) 策略模型的网络结构和参数设置;5) 损失函数的设计,例如如何平衡策略的探索和利用。
🖼️ 关键图片
📊 实验亮点
DAPO系统使用Qwen2.5-32B基础模型在AIME 2024上达到了50分,证明了该系统和算法的有效性。与之前隐藏训练细节的工作不同,该研究完全开源了训练代码和数据集,增强了可重复性,并为未来的研究提供了基础。
🎯 应用场景
该研究成果可应用于各种需要复杂推理能力的大型语言模型应用场景,例如数学问题求解、代码生成、对话系统等。开源系统和算法的公开,有助于加速这些领域的研发进程,并促进相关技术的普及和应用。此外,该系统还可以作为研究平台,用于探索新的强化学习算法和技术。
📄 摘要(原文)
Inference scaling empowers LLMs with unprecedented reasoning ability, with reinforcement learning as the core technique to elicit complex reasoning. However, key technical details of state-of-the-art reasoning LLMs are concealed (such as in OpenAI o1 blog and DeepSeek R1 technical report), thus the community still struggles to reproduce their RL training results. We propose the $\textbf{D}$ecoupled Clip and $\textbf{D}$ynamic s$\textbf{A}$mpling $\textbf{P}$olicy $\textbf{O}$ptimization ($\textbf{DAPO}$) algorithm, and fully open-source a state-of-the-art large-scale RL system that achieves 50 points on AIME 2024 using Qwen2.5-32B base model. Unlike previous works that withhold training details, we introduce four key techniques of our algorithm that make large-scale LLM RL a success. In addition, we open-source our training code, which is built on the verl framework, along with a carefully curated and processed dataset. These components of our open-source system enhance reproducibility and support future research in large-scale LLM RL.