PANDORA: Diffusion Policy Learning for Dexterous Robotic Piano Playing
作者: Yanjia Huang, Renjie Li, Zhengzhong Tu
分类: cs.LG, cs.RO, cs.SD, eess.AS
发布日期: 2025-03-17
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
PANDORA:用于灵巧机器人钢琴演奏的扩散策略学习框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散模型 策略学习 机器人钢琴演奏 大型语言模型 语义反馈 逆运动学 ROBOPIANIST
📋 核心要点
- 现有机器人钢琴演奏方法难以兼顾演奏精度和音乐表现力,尤其缺乏对高层次音乐语义的理解。
- PANDORA利用扩散模型生成平滑的动作轨迹,并结合LLM的语义反馈动态调整奖励,提升演奏表现力。
- 实验表明,PANDORA在ROBOPIANIST环境中显著优于基线方法,验证了扩散模型和LLM反馈的有效性。
📝 摘要(中文)
本文提出PANDORA,一种新颖的基于扩散的策略学习框架,专为灵巧机器人钢琴演奏而设计。该方法采用条件U-Net架构,并使用基于FiLM的全局条件增强,迭代地将嘈杂的动作序列去噪为平滑的高维轨迹。为了实现精确的琴键执行和富有表现力的音乐演奏,我们设计了一个复合奖励函数,该函数集成了特定于任务的准确性、音频保真度和来自大型语言模型(LLM)Oracle的高级语义反馈。LLM Oracle评估音乐表现力和风格细微差别,从而实现动态的、针对特定手的奖励调整。PANDORA进一步通过残差逆运动学细化策略进行增强,在ROBOPIANIST环境中实现了最先进的性能,在精度和表现力方面均显着优于基线。消融研究验证了基于扩散的去噪和LLM驱动的语义反馈在增强机器人音乐才能方面的关键贡献。
🔬 方法详解
问题定义:现有的机器人钢琴演奏方法通常难以同时保证演奏的准确性和音乐的表现力。尤其是在处理复杂的音乐作品时,机器人往往缺乏对音乐高层次语义的理解,导致演奏缺乏情感和风格。此外,精确控制灵巧手部动作以实现准确的琴键敲击也是一个挑战。
核心思路:PANDORA的核心思路是利用扩散模型学习生成高质量的机器人动作轨迹,并通过大型语言模型(LLM)提供的高级语义反馈来指导策略学习,从而提升机器人演奏的音乐表现力。通过将动作生成建模为去噪过程,可以生成更平滑、自然的动作序列。
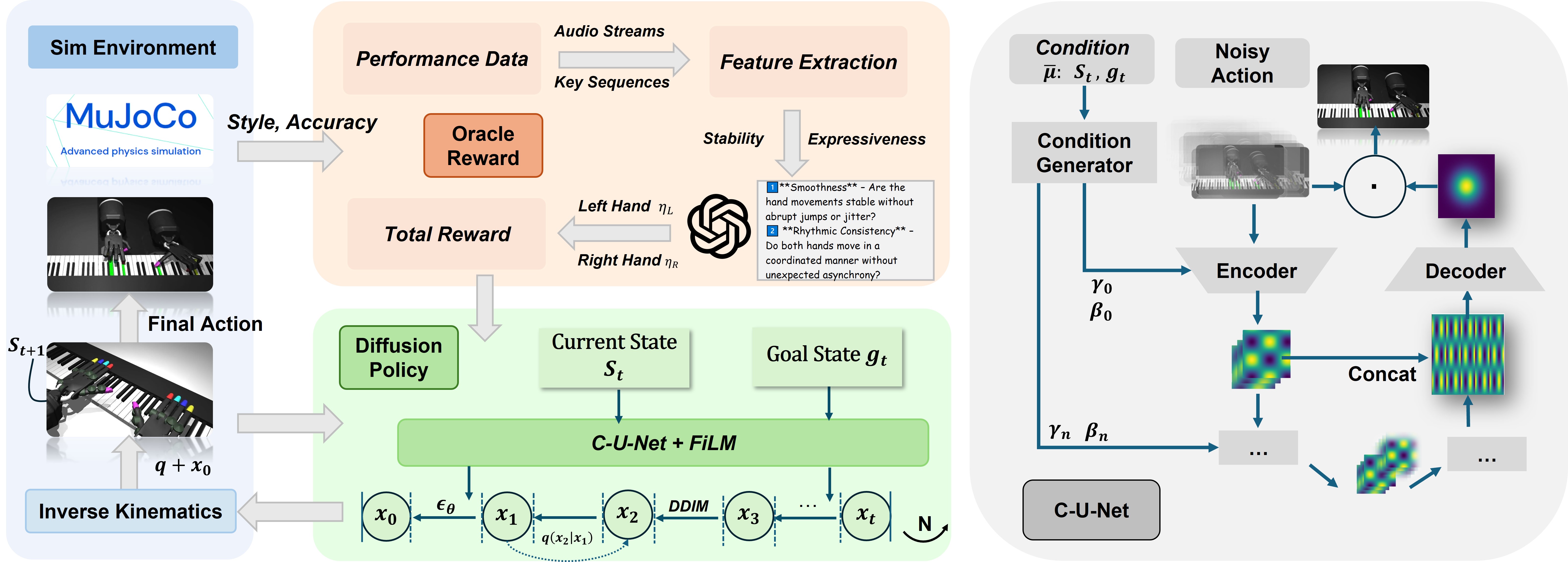
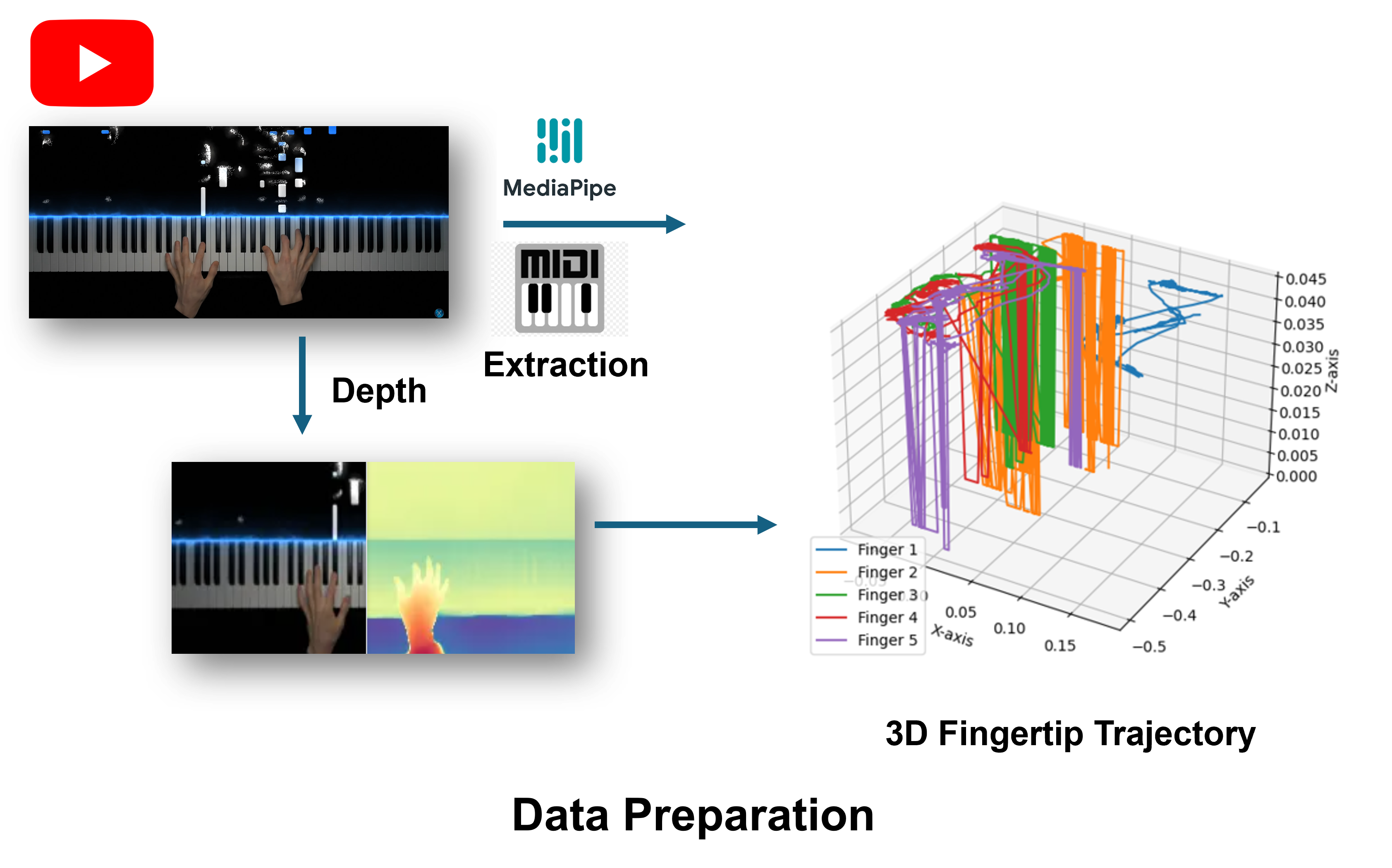
技术框架:PANDORA的整体框架包含以下几个主要模块:1) 基于条件U-Net的扩散模型,用于生成机器人动作轨迹;2) 基于FiLM的全局条件模块,用于将音乐信息融入扩散模型;3) 复合奖励函数,结合了任务精度、音频保真度和LLM语义反馈;4) 残差逆运动学细化策略,用于进一步优化动作轨迹。整个流程首先由扩散模型生成初始动作序列,然后通过逆运动学进行转换,最后通过残差策略进行微调。
关键创新:PANDORA最重要的技术创新点在于将扩散模型与LLM语义反馈相结合,用于机器人钢琴演奏。扩散模型能够生成平滑、自然的动作轨迹,而LLM则能够提供高层次的音乐语义信息,从而指导策略学习,提升演奏的表现力。这种结合使得机器人能够更好地理解和表达音乐的情感和风格。
关键设计:PANDORA的关键设计包括:1) 使用条件U-Net作为扩散模型的主干网络;2) 使用FiLM层将全局音乐信息融入U-Net;3) 设计复合奖励函数,其中LLM的反馈作为奖励信号的一部分,用于指导策略学习;4) 使用残差逆运动学策略,对动作轨迹进行微调,以提高精度。
🖼️ 关键图片
📊 实验亮点
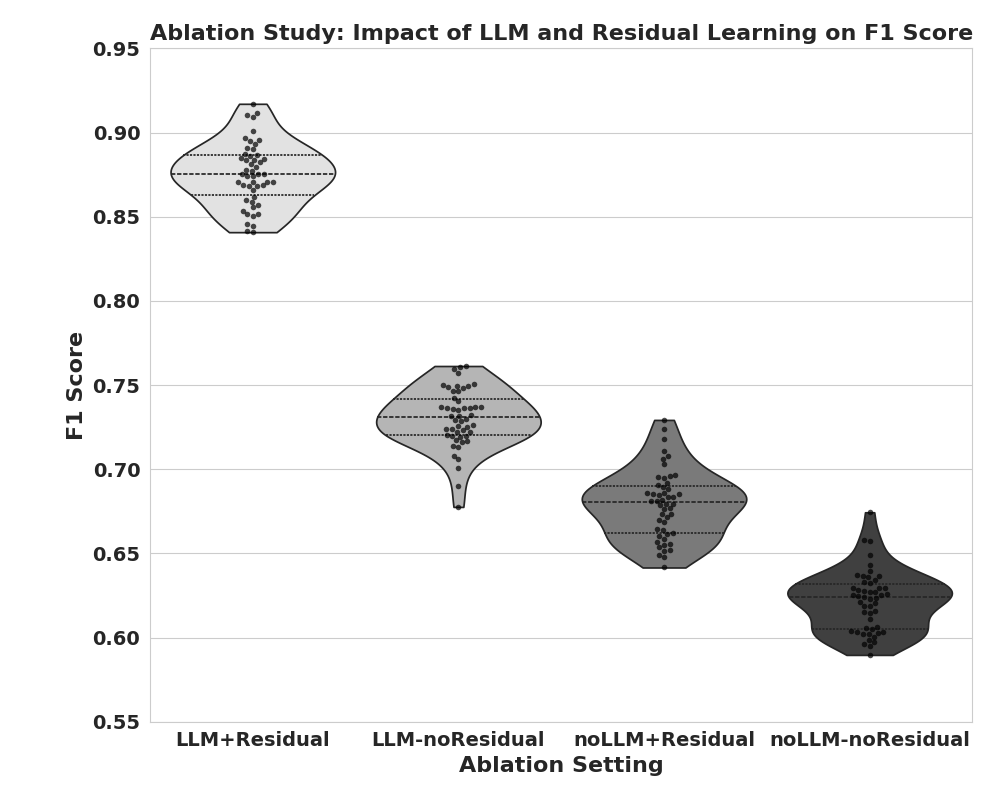
PANDORA在ROBOPIANIST环境中取得了显著的性能提升,在精度和表现力方面均优于基线方法。消融实验表明,扩散模型和LLM语义反馈对提升机器人演奏水平至关重要。具体数据未知,但摘要强调了“显著优于基线”的结果。
🎯 应用场景
PANDORA的研究成果可应用于机器人音乐表演、人机协作音乐创作等领域。该技术不仅能提升机器人演奏的艺术性,还能为音乐教育、娱乐等行业带来新的可能性。未来,该技术有望扩展到其他需要精细动作控制和高层次语义理解的机器人应用中,例如机器人辅助手术、艺术创作等。
📄 摘要(原文)
We present PANDORA, a novel diffusion-based policy learning framework designed specifically for dexterous robotic piano performance. Our approach employs a conditional U-Net architecture enhanced with FiLM-based global conditioning, which iteratively denoises noisy action sequences into smooth, high-dimensional trajectories. To achieve precise key execution coupled with expressive musical performance, we design a composite reward function that integrates task-specific accuracy, audio fidelity, and high-level semantic feedback from a large language model (LLM) oracle. The LLM oracle assesses musical expressiveness and stylistic nuances, enabling dynamic, hand-specific reward adjustments. Further augmented by a residual inverse-kinematics refinement policy, PANDORA achieves state-of-the-art performance in the ROBOPIANIST environment, significantly outperforming baselines in both precision and expressiveness. Ablation studies validate the critical contributions of diffusion-based denoising and LLM-driven semantic feedback in enhancing robotic musicianship. Videos available at: https://taco-group.github.io/PANDORA