MoECollab: Democratizing LLM Development Through Collaborative Mixture of Experts
作者: Harshit
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-03-16
💡 一句话要点
MoECollab:通过协作式混合专家模型 democratize 大语言模型开发
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 分布式训练 大语言模型 模型 democratize 路由优化
📋 核心要点
- 现有LLM开发高度中心化,资源受限组织难以参与,阻碍了LLM技术的广泛发展。
- MoECollab将LLM分解为多个专家模块,通过门控网络协调,实现分布式协作开发。
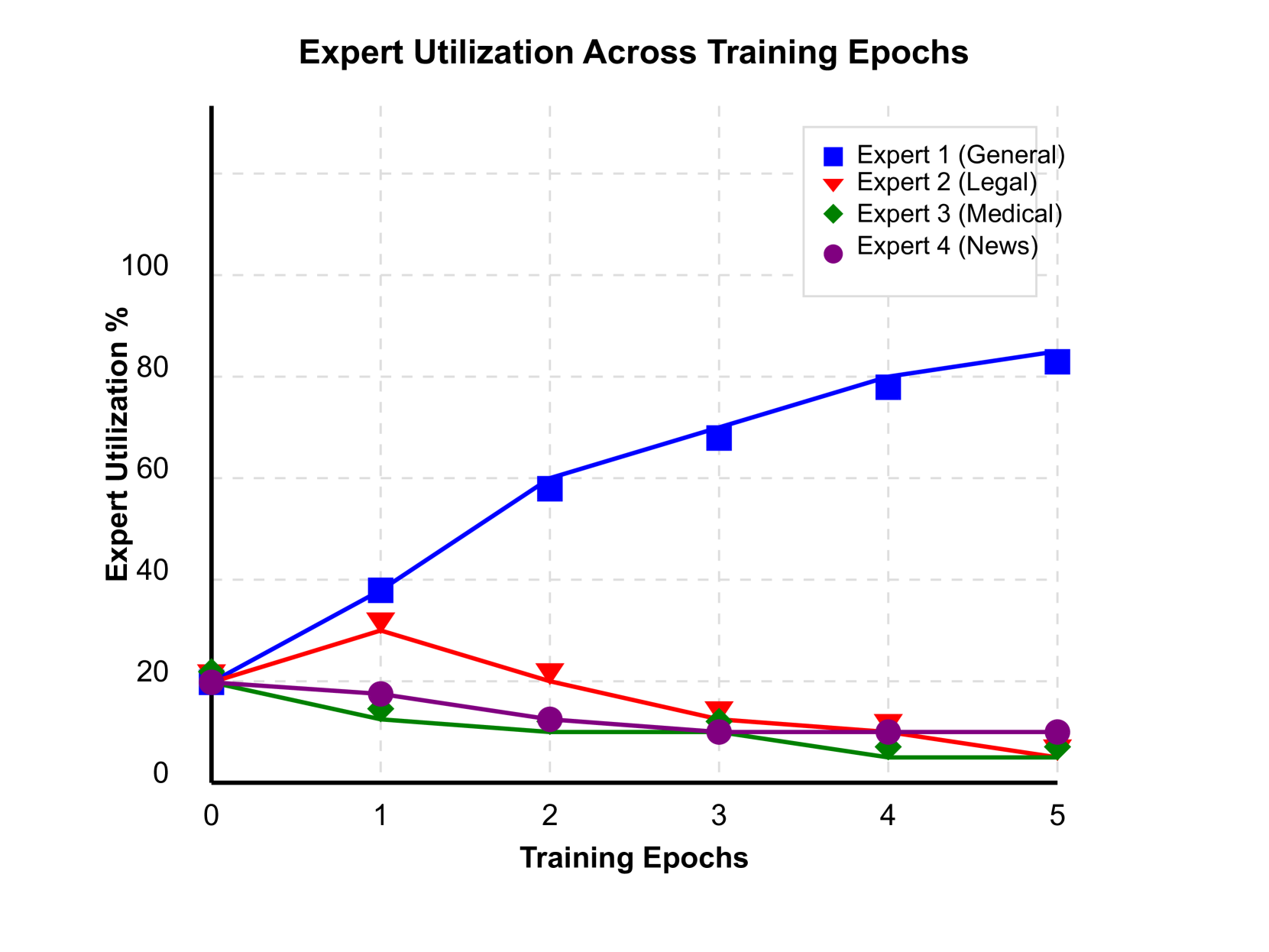
- 实验表明,MoECollab在降低计算成本的同时,显著提升了模型准确率和专家利用率。
📝 摘要(中文)
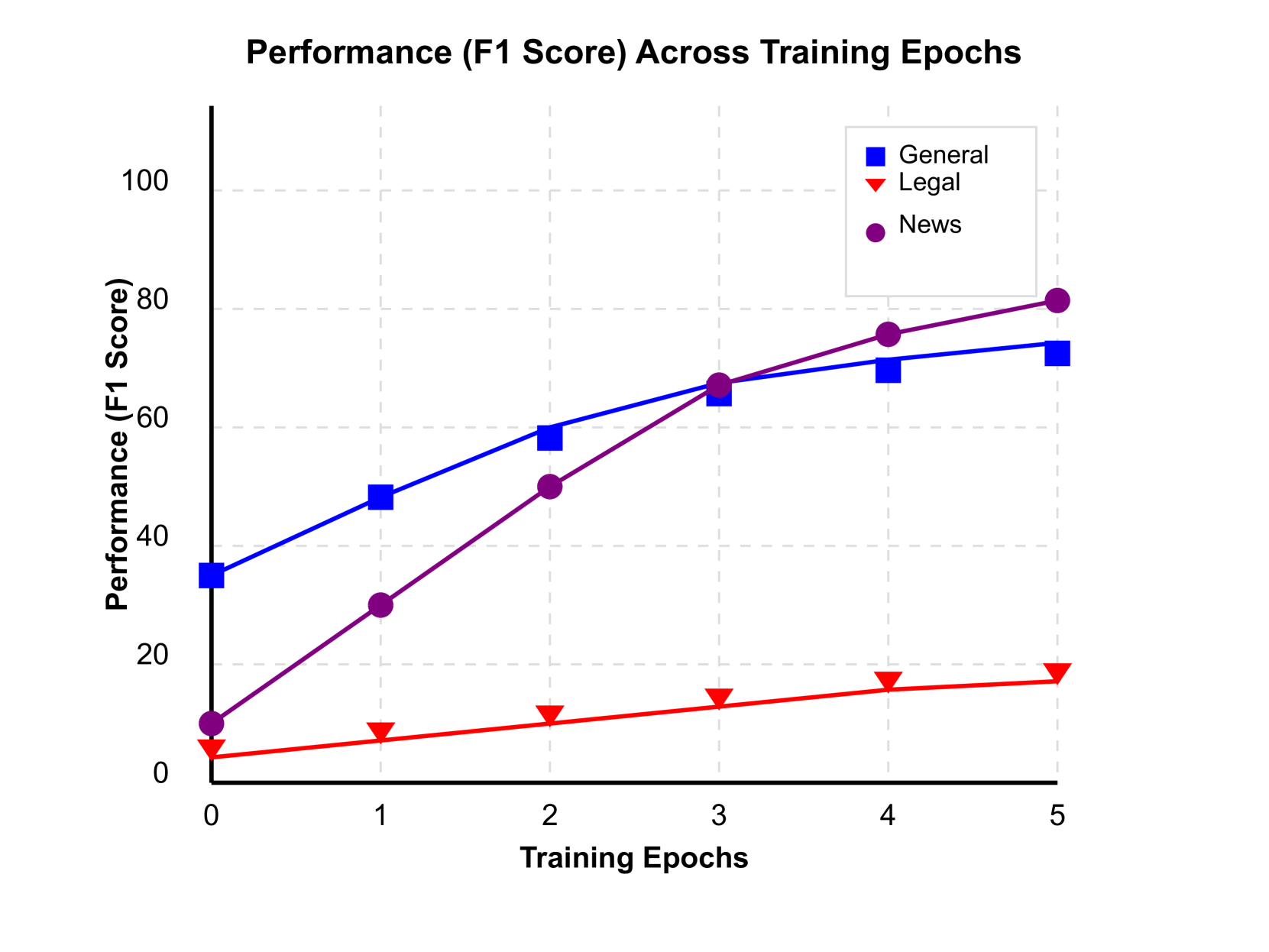
大型语言模型(LLM)的开发日益集中化,限制了资源匮乏的组织参与。本文介绍了MoECollab,一种利用混合专家(MoE)架构的新框架,以实现分布式、协作式的LLM开发。通过将单体模型分解为由可训练门控网络协调的专业专家模块,我们的框架允许不同的贡献者参与,而无需考虑计算资源。我们提供了一个完整的技术实现,包括专家动态、门控机制和集成策略的数学基础。在多个数据集上的实验表明,我们的方法在降低34%计算需求的同时,实现了比基线模型高3-7%的准确率提升。专家专业化带来了显著的领域特定收益,在一般分类中F1得分从51%提高到88%,在新闻分类中准确率从23%提高到44%。我们形式化了路由熵优化问题,并证明了适当的正则化技术如何使专家利用率提高14%。这些结果验证了MoECollab作为一种通过架构支持的协作来 democratize LLM 开发的有效方法。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的开发高度依赖于拥有大量计算资源的机构,这使得小型团队和个人难以参与LLM的开发和定制。现有的单体模型训练成本高昂,难以针对特定领域进行优化。
核心思路:MoECollab的核心思想是利用混合专家(MoE)架构,将大型模型分解为多个小型、专业的专家模块。每个专家模块可以由不同的团队或个人独立开发和训练,从而实现分布式协作。通过门控网络动态地将输入路由到最合适的专家,从而提高模型的效率和专业性。
技术框架:MoECollab框架包含以下几个主要模块:1) 专家模块:每个专家模块是一个小型神经网络,负责处理特定领域或任务的数据。2) 门控网络:门控网络根据输入数据的特征,动态地选择激活哪些专家模块。3) 集成策略:将不同专家模块的输出进行集成,得到最终的预测结果。整个流程是,输入数据首先经过门控网络,门控网络输出每个专家的权重,然后根据权重选择激活的专家,最后将激活的专家的输出进行加权平均或组合,得到最终结果。
关键创新:MoECollab的关键创新在于其架构设计,它允许分布式协作开发LLM,降低了开发门槛。此外,论文还提出了路由熵优化方法,通过正则化技术提高专家利用率。这种架构支持了更灵活的模型定制和领域专业化。
关键设计:论文形式化了路由熵优化问题,并提出了相应的正则化技术。具体来说,通过在损失函数中添加路由熵项,鼓励门控网络更均匀地分配流量给不同的专家,从而提高专家利用率。此外,论文还详细描述了专家模块的训练方法、门控网络的结构设计以及集成策略的选择。
🖼️ 关键图片
📊 实验亮点
MoECollab在多个数据集上取得了显著的性能提升。相较于基线模型,准确率提升了3-7%,计算需求降低了34%。在一般分类任务中,F1得分从51%提高到88%,在新闻分类任务中,准确率从23%提高到44%。通过路由熵优化,专家利用率提高了14%。
🎯 应用场景
MoECollab可应用于各种需要领域专业知识的LLM应用场景,例如:特定行业领域的智能客服、专业领域的文本生成、个性化教育等。通过降低LLM开发门槛,促进更多创新应用涌现,加速LLM技术在各行业的普及。
📄 摘要(原文)
Large Language Model (LLM) development has become increasingly centralized, limiting participation to well-resourced organizations. This paper introduces MoECollab, a novel framework leveraging Mixture of Experts (MoE) architecture to enable distributed, collaborative LLM development. By decomposing monolithic models into specialized expert modules coordinated by a trainable gating network, our framework allows diverse contributors to participate regardless of computational resources. We provide a complete technical implementation with mathematical foundations for expert dynamics, gating mechanisms, and integration strategies. Experiments on multiple datasets demonstrate that our approach achieves accuracy improvements of 3-7% over baseline models while reducing computational requirements by 34%. Expert specialization yields significant domain-specific gains, with improvements from 51% to 88% F1 score in general classification and from 23% to 44% accuracy in news categorization. We formalize the routing entropy optimization problem and demonstrate how proper regularization techniques lead to 14% higher expert utilization rates. These results validate MoECollab as an effective approach for democratizing LLM development through architecturally-supported collaboration.