Empowering Time Series Analysis with Synthetic Data: A Survey and Outlook in the Era of Foundation Models
作者: Xu Liu, Taha Aksu, Juncheng Liu, Qingsong Wen, Yuxuan Liang, Caiming Xiong, Silvio Savarese, Doyen Sahoo, Junnan Li, Chenghao Liu
分类: cs.LG
发布日期: 2025-03-14
💡 一句话要点
综述:合成数据赋能时序分析,展望基础模型时代的应用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时序分析 合成数据 基础模型 大型语言模型 数据生成 预训练 微调
📋 核心要点
- 时序分析模型依赖于大规模高质量数据集,但真实数据获取面临监管、多样性和质量挑战。
- 合成数据通过提供可扩展、无偏和高质量的替代方案,有效缓解了真实数据获取的难题。
- 该综述分析了合成数据在时序基础模型和大型语言模型中的应用,并展望了未来研究方向。
📝 摘要(中文)
时序分析对于理解复杂系统的动态至关重要。近年来,基础模型的进步催生了任务无关的时序基础模型(TSFMs)和基于大型语言模型的时序模型(TSLLMs),实现了泛化学习和上下文信息的整合。然而,它们的成功依赖于大规模、多样化和高质量的数据集,但由于监管、多样性、质量和数量的限制,构建这些数据集极具挑战性。合成数据作为一种可行的解决方案应运而生,通过提供可扩展、无偏和高质量的替代方案来应对这些挑战。本综述全面回顾了用于TSFMs和TSLLMs的合成数据,分析了数据生成策略及其在模型预训练、微调和评估中的作用,并确定了未来的研究方向。
🔬 方法详解
问题定义:论文旨在解决时序分析领域中,由于真实时序数据获取困难(受限于监管、多样性、质量和数量等因素),导致时序基础模型(TSFMs)和基于大型语言模型的时序模型(TSLLMs)训练受限的问题。现有方法依赖于真实数据,难以满足模型对大规模、多样化和高质量数据的需求。
核心思路:论文的核心思路是利用合成数据来弥补真实时序数据的不足。通过生成具有特定属性和模式的合成数据,可以有效地扩充训练数据集,提高模型的泛化能力和鲁棒性。合成数据可以克服真实数据获取的限制,例如数据隐私、数据稀缺等问题。
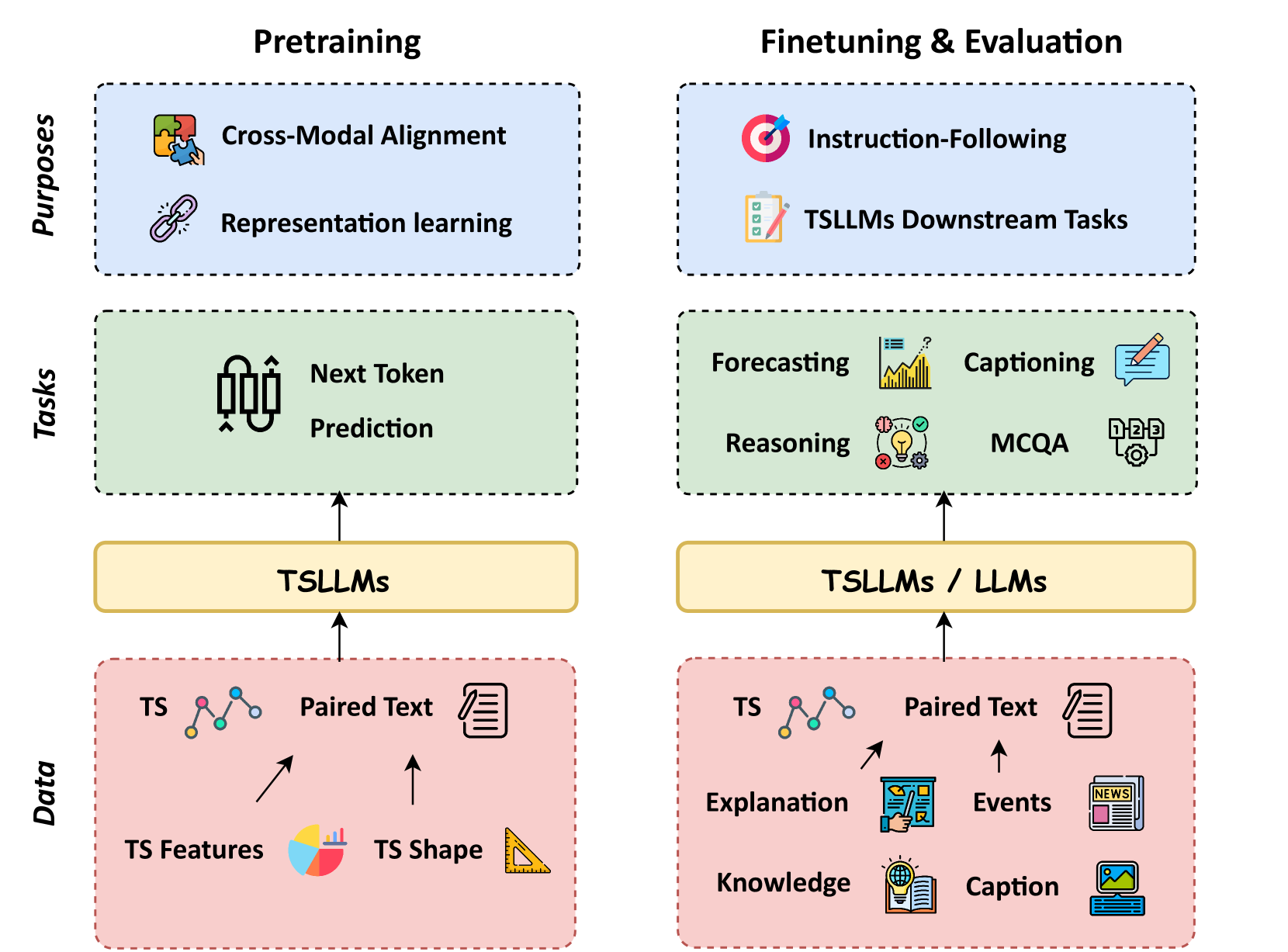
技术框架:该综述论文主要围绕合成数据在时序分析中的应用展开,并未提出新的技术框架。其主要内容包括:1) 分析了合成数据生成策略,例如基于统计模型、生成对抗网络(GANs)和变分自编码器(VAEs)等方法;2) 探讨了合成数据在模型预训练、微调和评估中的作用;3) 总结了现有研究的优缺点,并提出了未来研究方向。
关键创新:该论文的关键创新在于对合成数据在时序分析领域应用的全面综述。它系统地整理了现有的研究成果,并指出了未来研究的潜在方向。虽然没有提出新的合成数据生成方法,但它为研究人员提供了一个清晰的路线图,帮助他们更好地利用合成数据来解决时序分析中的实际问题。
关键设计:由于是综述论文,没有具体的参数设置、损失函数或网络结构等技术细节。论文主要关注不同合成数据生成方法的特点和适用场景,以及合成数据在不同模型训练阶段的应用策略。例如,论文可能会讨论GANs在生成逼真时序数据方面的优势,以及VAEs在生成多样化时序数据方面的潜力。
🖼️ 关键图片

📊 实验亮点
该综述全面回顾了合成数据在时序分析领域的应用,重点分析了不同数据生成策略在模型预训练、微调和评估中的作用。论文总结了现有方法的优缺点,并指出了未来研究方向,为研究人员提供了宝贵的参考。
🎯 应用场景
该研究成果对金融、医疗、物联网等多个时序数据分析领域具有重要应用价值。合成数据可以用于训练更强大的时序预测模型,提高异常检测的准确性,并促进新算法的开发。通过解决数据稀缺和隐私问题,合成数据有望加速时序分析技术在各行业的落地应用。
📄 摘要(原文)
Time series analysis is crucial for understanding dynamics of complex systems. Recent advances in foundation models have led to task-agnostic Time Series Foundation Models (TSFMs) and Large Language Model-based Time Series Models (TSLLMs), enabling generalized learning and integrating contextual information. However, their success depends on large, diverse, and high-quality datasets, which are challenging to build due to regulatory, diversity, quality, and quantity constraints. Synthetic data emerge as a viable solution, addressing these challenges by offering scalable, unbiased, and high-quality alternatives. This survey provides a comprehensive review of synthetic data for TSFMs and TSLLMs, analyzing data generation strategies, their role in model pretraining, fine-tuning, and evaluation, and identifying future research directions.