Low-cost Real-world Implementation of the Swing-up Pendulum for Deep Reinforcement Learning Experiments
作者: Peter Böhm, Pauline Pounds, Archie C. Chapman
分类: cs.LG, cs.AI, cs.RO, eess.SY
发布日期: 2025-03-14
备注: Australasian Conference on Robotics and Automation (ACRA) 2022
💡 一句话要点
提出一种低成本倒立摆实验平台,用于弥合深度强化学习中的Sim-to-Real差距
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 倒立摆 Sim-to-Real 强化学习 物理实验平台
📋 核心要点
- 深度强化学习在模拟环境中表现出色,但直接应用于真实世界时,性能显著下降,主要原因是模拟环境与真实环境存在差异。
- 论文提出一种低成本的倒立摆物理平台,旨在帮助研究人员更好地研究和解决深度强化学习中的Sim-to-Real迁移问题。
- 该平台设计考虑了真实系统中存在的延迟问题,并使用易于获取的材料和零件,降低了研究和教育的成本和门槛。
📝 摘要(中文)
深度强化学习(DRL)在虚拟和模拟领域取得了成功,但由于模拟环境和真实环境之间的关键差异,DRL训练的策略在实际应用中的成功案例有限。为了帮助研究人员弥合 extit{sim-to-real差距},本文介绍了一种低成本的物理倒立摆装置和软件环境,用于探索sim-to-real DRL方法。特别地,我们装置的设计能够详细检查物理系统中在感知、通信、学习、推理和驱动时产生的延迟。此外,我们希望改善教育系统的可及性,因此我们的装置使用现成的材料和零件来降低成本和物流障碍。我们的设计展示了商用现成的电子、机电和传感器系统,结合常见的金属挤压件、销钉和3D打印耦合件,如何为经济实惠的物理DRL装置提供途径。该物理装置辅以使用高保真物理引擎和OpenAI Gym接口实现的模拟环境。
🔬 方法详解
问题定义:现有深度强化学习算法在模拟环境中训练的模型,难以直接应用于真实物理系统,存在“Sim-to-Real”的差距。主要痛点在于模拟环境无法完全模拟真实世界的物理特性,例如延迟、摩擦、噪声等,导致模型在真实环境中泛化能力不足。
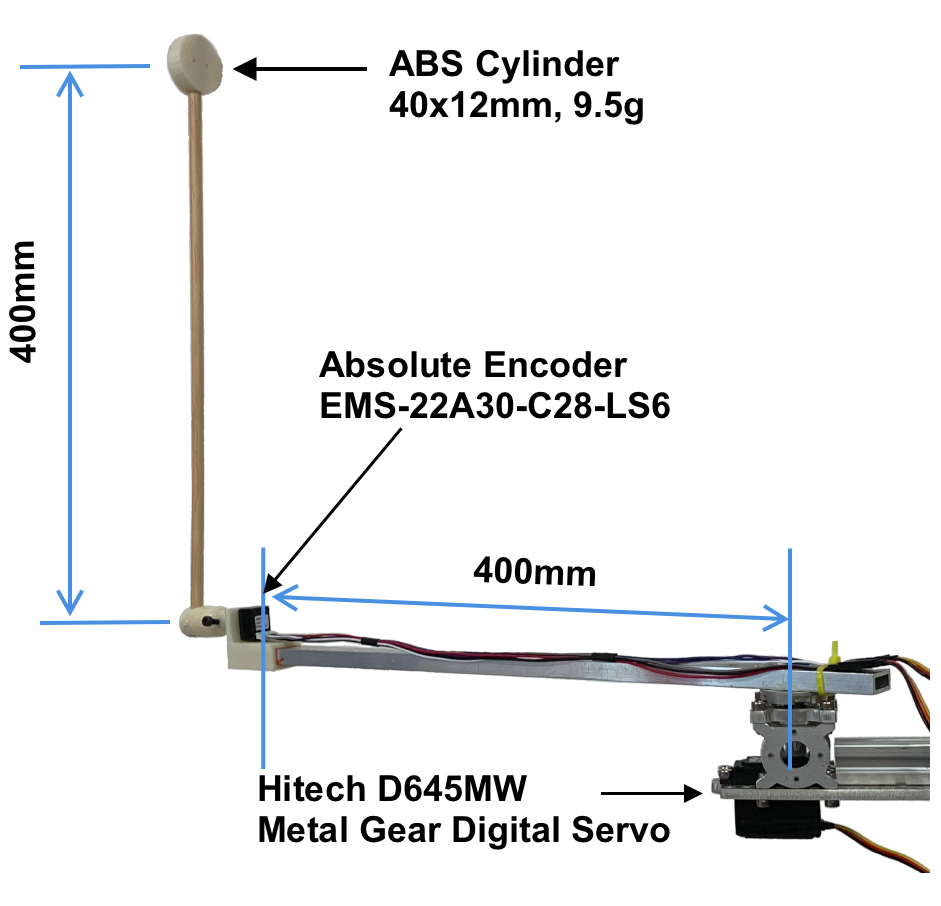
核心思路:论文的核心思路是构建一个低成本、易于复现的物理倒立摆实验平台,并提供配套的模拟环境。通过在该平台上进行深度强化学习实验,研究人员可以更好地理解和解决Sim-to-Real问题。该平台的设计重点关注了真实物理系统中存在的延迟问题,并力求使用易于获取的材料和零件,降低实验成本。
技术框架:该平台由物理倒立摆装置和模拟环境两部分组成。物理倒立摆装置采用商用现成的电子、机电和传感器系统,结合常见的金属挤压件、销钉和3D打印耦合件构建。模拟环境使用高保真物理引擎实现,并提供OpenAI Gym接口,方便研究人员使用现有的深度强化学习算法。整体流程是:首先在模拟环境中训练深度强化学习模型,然后在物理倒立摆装置上进行测试和验证,并根据实验结果对模型进行改进。
关键创新:该论文的关键创新在于提供了一个低成本、易于复现、且考虑了真实系统延迟的物理倒立摆实验平台。该平台能够帮助研究人员更好地研究和解决深度强化学习中的Sim-to-Real问题,并降低了相关研究的门槛。
关键设计:物理倒立摆装置的关键设计包括:选择合适的电机和传感器,以保证系统的稳定性和精度;设计合理的机械结构,以减小摩擦和提高响应速度;考虑真实系统中存在的延迟,并在控制算法中进行补偿。模拟环境的关键设计包括:使用高保真物理引擎,以尽可能真实地模拟物理系统的行为;提供OpenAI Gym接口,方便研究人员使用现有的深度强化学习算法。
🖼️ 关键图片


📊 实验亮点
该论文提供了一个完整的低成本倒立摆实验平台的设计方案,并详细描述了物理装置和模拟环境的构建过程。该平台能够模拟真实系统中存在的延迟,并提供OpenAI Gym接口,方便研究人员使用现有的深度强化学习算法。虽然论文没有给出具体的性能数据,但该平台为深度强化学习的Sim-to-Real研究提供了一个有价值的工具。
🎯 应用场景
该研究成果可应用于机器人控制、自动化控制等领域。通过在低成本的物理平台上进行深度强化学习实验,可以加速算法的开发和验证,并降低实际部署的风险。此外,该平台还可用于教育领域,帮助学生更好地理解深度强化学习的原理和应用。
📄 摘要(原文)
Deep reinforcement learning (DRL) has had success in virtual and simulated domains, but due to key differences between simulated and real-world environments, DRL-trained policies have had limited success in real-world applications. To assist researchers to bridge the \textit{sim-to-real gap}, in this paper, we describe a low-cost physical inverted pendulum apparatus and software environment for exploring sim-to-real DRL methods. In particular, the design of our apparatus enables detailed examination of the delays that arise in physical systems when sensing, communicating, learning, inferring and actuating. Moreover, we wish to improve access to educational systems, so our apparatus uses readily available materials and parts to reduce cost and logistical barriers. Our design shows how commercial, off-the-shelf electronics and electromechanical and sensor systems, combined with common metal extrusions, dowel and 3D printed couplings provide a pathway for affordable physical DRL apparatus. The physical apparatus is complemented with a simulated environment implemented using a high-fidelity physics engine and OpenAI Gym interface.