Samoyeds: Accelerating MoE Models with Structured Sparsity Leveraging Sparse Tensor Cores
作者: Chenpeng Wu, Qiqi Gu, Heng Shi, Jianguo Yao, Haibing Guan
分类: cs.LG, cs.AI, cs.DC, cs.OS
发布日期: 2025-03-13
💡 一句话要点
Samoyeds:利用稀疏张量核心加速双侧结构化稀疏MoE模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 MoE 稀疏计算 结构化稀疏 稀疏张量核心 模型加速 大语言模型
📋 核心要点
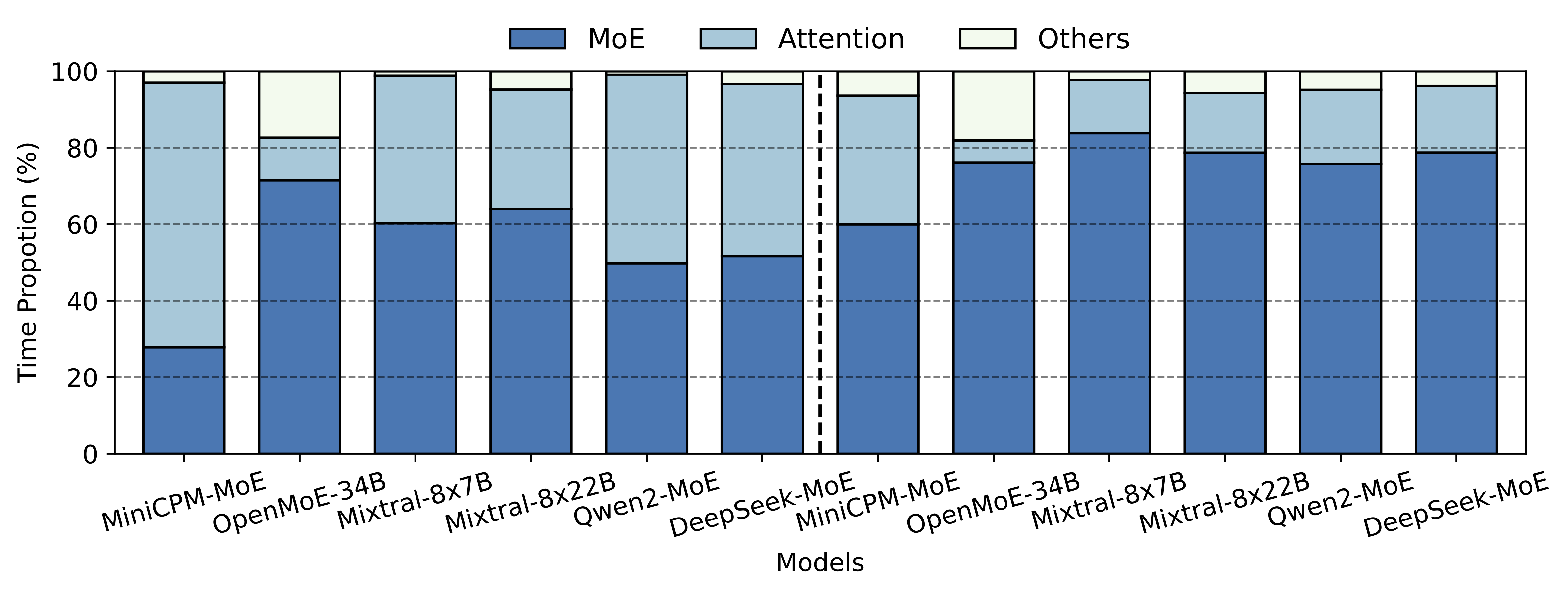
- 现有MoE模型加速方法主要关注模型参数稀疏性,忽略了激活中的稀疏模式,导致计算效率瓶颈。
- Samoyeds系统同时利用激活和模型参数的结构化稀疏性,并针对稀疏张量核心进行了优化。
- 实验结果表明,Samoyeds在内核和模型层面均优于现有方法,并显著提升了内存效率和模型精度。
📝 摘要(中文)
基于混合专家模型(MoE)的大型语言模型(LLM)的规模不断扩大,带来了巨大的计算和内存挑战,因此需要创新的解决方案来提高效率,同时不影响模型精度。结构化稀疏性通过利用新兴的稀疏计算硬件,成为应对这些挑战的一种引人注目的策略。以往的研究主要集中在模型参数的稀疏性上,而忽略了激活中固有的稀疏模式。这种疏忽可能导致与激活相关的额外计算成本,从而导致次优性能。本文提出了Samoyeds,一种利用稀疏张量核心(SpTCs)的MoE LLM创新加速系统。Samoyeds是第一个同时将稀疏性应用于激活和模型参数的系统。它引入了一种为MoE计算量身定制的定制稀疏数据格式,并开发了一种专门的稀疏-稀疏矩阵乘法内核。此外,Samoyeds还结合了专门为在SpTC上执行双侧结构化稀疏MoE LLM而设计的系统优化,进一步提高了系统性能。评估表明,Samoyeds在内核级别上优于SOTA工作高达1.99倍,在模型级别上优于1.58倍。此外,它还提高了内存效率,平均将最大支持的批处理大小提高了4.41倍。此外,Samoyeds在模型精度和硬件可移植性方面均优于现有的SOTA结构化稀疏解决方案。
🔬 方法详解
问题定义:现有MoE模型加速方法主要关注模型参数的稀疏性,忽略了激活中固有的稀疏模式。这种忽略导致激活相关的计算开销,从而限制了整体加速效果。此外,现有方法通常没有充分利用稀疏张量核心(SpTCs)的硬件特性,导致硬件利用率不高。
核心思路:Samoyeds的核心思路是同时利用激活和模型参数的结构化稀疏性,并针对SpTCs进行优化。通过定制稀疏数据格式和稀疏-稀疏矩阵乘法内核,最大化SpTCs的利用率,从而实现高效的MoE模型加速。
技术框架:Samoyeds包含以下主要模块:1) 稀疏数据格式设计:针对MoE计算特点,设计了一种新的稀疏数据格式,用于存储激活和模型参数。2) 稀疏-稀疏矩阵乘法内核:开发了一种专门的稀疏-稀疏矩阵乘法内核,用于在SpTCs上高效执行MoE计算。3) 系统优化:针对双侧结构化稀疏MoE LLM在SpTCs上的执行,进行了一系列系统优化,例如数据布局优化、计算调度优化等。
关键创新:Samoyeds的关键创新在于:1) 同时利用激活和模型参数的结构化稀疏性。2) 针对MoE计算特点,设计了一种新的稀疏数据格式。3) 开发了一种专门的稀疏-稀疏矩阵乘法内核,并针对SpTCs进行了优化。与现有方法相比,Samoyeds能够更充分地利用硬件资源,从而实现更高的加速效果。
关键设计:Samoyeds的关键设计包括:1) 稀疏数据格式:具体格式未知,但强调针对MoE计算特点设计。2) 稀疏-稀疏矩阵乘法内核:具体实现未知,但强调针对SpTCs优化。3) 系统优化:具体优化策略未知,但包括数据布局和计算调度优化。
🖼️ 关键图片
📊 实验亮点
Samoyeds在内核级别上比最先进的方法快1.99倍,在模型级别上快1.58倍。此外,它还提高了内存效率,平均将最大支持的批处理大小提高了4.41倍。Samoyeds在模型精度和硬件可移植性方面也优于现有的最先进的结构化稀疏解决方案。这些结果表明,Samoyeds是一种高效且通用的MoE模型加速系统。
🎯 应用场景
Samoyeds可应用于各种需要高效MoE模型推理的场景,例如自然语言处理、推荐系统、语音识别等。通过提高模型推理速度和降低内存占用,Samoyeds可以支持更大规模的模型和更大的批处理大小,从而提高应用性能和用户体验。该研究的成果也有助于推动稀疏计算硬件的发展和应用。
📄 摘要(原文)
The escalating size of Mixture-of-Experts (MoE) based Large Language Models (LLMs) presents significant computational and memory challenges, necessitating innovative solutions to enhance efficiency without compromising model accuracy. Structured sparsity emerges as a compelling strategy to address these challenges by leveraging the emerging sparse computing hardware. Prior works mainly focus on the sparsity in model parameters, neglecting the inherent sparse patterns in activations. This oversight can lead to additional computational costs associated with activations, potentially resulting in suboptimal performance. This paper presents Samoyeds, an innovative acceleration system for MoE LLMs utilizing Sparse Tensor Cores (SpTCs). Samoyeds is the first to apply sparsity simultaneously to both activations and model parameters. It introduces a bespoke sparse data format tailored for MoE computation and develops a specialized sparse-sparse matrix multiplication kernel. Furthermore, Samoyeds incorporates systematic optimizations specifically designed for the execution of dual-side structured sparse MoE LLMs on SpTCs, further enhancing system performance. Evaluations show that Samoyeds outperforms SOTA works by up to 1.99$\times$ at the kernel level and 1.58$\times$ at the model level. Moreover, it enhances memory efficiency, increasing maximum supported batch sizes by 4.41$\times$ on average. Additionally, Samoyeds surpasses existing SOTA structured sparse solutions in both model accuracy and hardware portability.