Conformal Prediction Sets for Deep Generative Models via Reduction to Conformal Regression
作者: Hooman Shahrokhi, Devjeet Raj Roy, Yan Yan, Venera Arnaoudova, Janaradhan Rao Doppa
分类: cs.LG, cs.AI
发布日期: 2025-03-13 (更新: 2025-06-16)
💡 一句话要点
提出Generative Prediction Sets (GPS)算法,为深度生成模型生成具有验证保证的预测集合。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 共形推断 深度生成模型 预测集合 代码生成 自然语言生成
📋 核心要点
- 现有方法难以保证深度生成模型输出预测集合的有效性,即集合中至少包含一个满足用户定义标准的结果。
- GPS算法通过对获得可接受输出所需的最小样本数进行共形回归,从而生成具有可证明保证的预测集合。
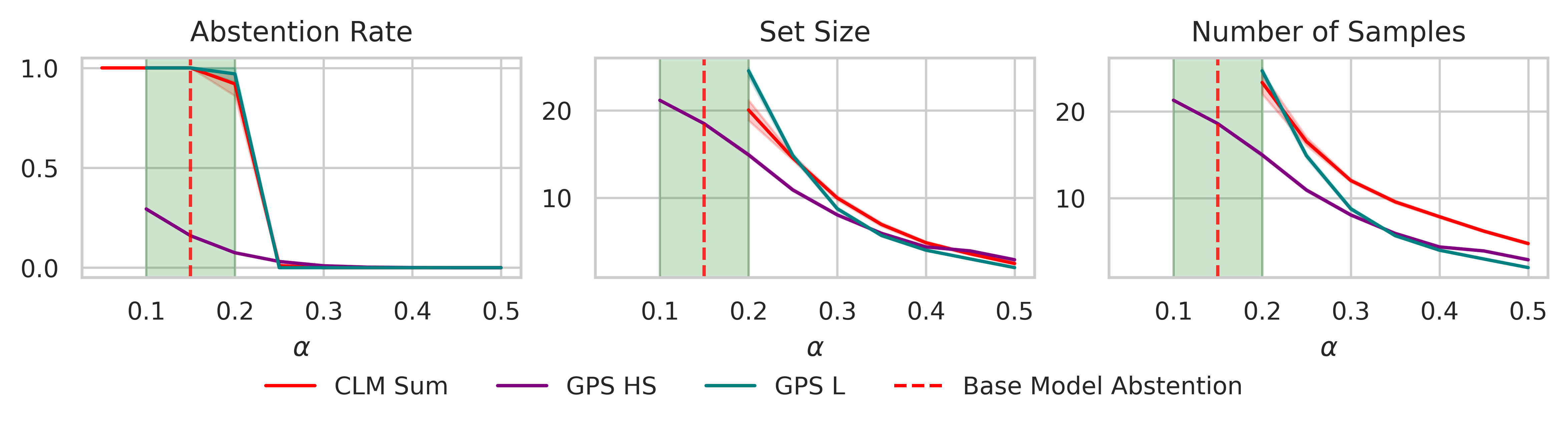
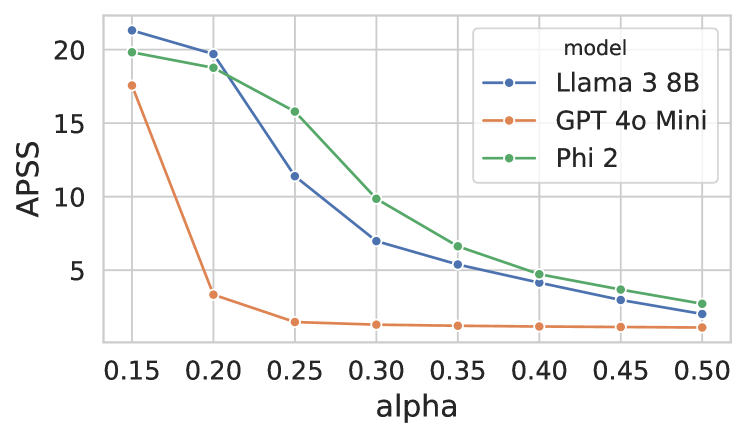
- 实验表明,GPS在代码生成和数学文字问题等任务上,优于当前最先进的方法,验证了其有效性。
📝 摘要(中文)
本文研究了从黑盒深度生成模型中采样输出(例如,软件代码和自然语言文本),为给定输入(例如,文本提示)生成有效且小的预测集合的问题。预测集合的有效性由用户定义的二元可接受性函数决定,该函数取决于目标应用。例如,在代码生成应用中,要求集合中至少有一个程序通过所有测试用例。为了解决这个问题,我们开发了一种简单有效的共形推断算法,称为Generative Prediction Sets (GPS)。给定一组校准示例和对深度生成模型的黑盒访问权限,GPS可以生成具有可证明保证的预测集合。GPS背后的关键思想是利用分布中固有的结构,即获得可接受输出所需的最小样本数,从而开发一种简单的关于最小样本数的共形回归方法。在多个代码和数学文字问题数据集上使用不同的大型语言模型进行的实验证明了GPS优于最先进的方法。
🔬 方法详解
问题定义:论文旨在解决如何为深度生成模型生成有效且小的预测集合的问题。现有方法通常难以保证预测集合的有效性,即无法确保集合中至少包含一个满足用户定义的可接受性标准的输出。例如,在代码生成任务中,需要生成的代码至少能通过所有测试用例。现有方法缺乏对预测集合有效性的可靠保证。
核心思路:论文的核心思路是利用共形推断的思想,将预测集合的生成问题转化为一个共形回归问题。具体来说,论文关注的是获得一个可接受的输出所需的最小样本数。通过对这个最小样本数进行回归,可以估计出需要生成多少个样本才能以一定的置信度保证预测集合的有效性。这种方法的核心在于利用了生成模型输出分布的内在结构。
技术框架:GPS算法的整体流程如下:1) 使用校准数据集,通过黑盒深度生成模型生成多个候选输出。2) 定义一个可接受性函数,用于判断一个输出是否满足要求(例如,代码是否通过所有测试用例)。3) 计算每个校准样本获得可接受输出所需的最小样本数。4) 使用共形回归方法,基于最小样本数构建一个非一致性度量。5) 对于新的输入,生成多个候选输出,并使用非一致性度量来确定哪些输出应该包含在预测集合中,以保证预测集合的有效性。
关键创新:GPS算法的关键创新在于将预测集合的生成问题转化为一个关于最小样本数的共形回归问题。与直接预测输出不同,GPS预测的是需要生成多少个样本才能获得一个可接受的输出。这种方法能够更有效地利用生成模型的输出分布信息,并提供可证明的有效性保证。此外,GPS算法只需要对生成模型进行黑盒访问,不需要修改模型的内部结构或训练过程。
关键设计:GPS算法的关键设计包括:1) 可接受性函数的定义,这取决于具体的应用场景。2) 非一致性度量的选择,论文中使用了基于最小样本数的共形回归方法。3) 置信水平的选择,这决定了预测集合的有效性保证程度。论文中没有明确指出具体的网络结构或损失函数,因为GPS算法是通用的,可以应用于各种深度生成模型。
🖼️ 关键图片

📊 实验亮点
实验结果表明,GPS算法在代码生成和数学文字问题等任务上,显著优于当前最先进的方法。具体来说,GPS能够在保证预测集合有效性的前提下,生成更小的预测集合,从而提高了生成效率。论文在多个数据集上进行了实验,并使用了不同的大型语言模型,验证了GPS算法的通用性和有效性。
🎯 应用场景
该研究成果可广泛应用于需要从深度生成模型中生成可靠输出的场景,例如代码生成、自然语言生成、药物发现等。在这些领域,确保生成结果的有效性至关重要。GPS算法能够为这些应用提供一种生成具有可验证保证的预测集合的有效方法,从而提高生成结果的可靠性和实用性,并降低下游任务的风险。
📄 摘要(原文)
We consider the problem of generating valid and small prediction sets by sampling outputs (e.g., software code and natural language text) from a black-box deep generative model for a given input (e.g., textual prompt). The validity of a prediction set is determined by a user-defined binary admissibility function depending on the target application. For example, requiring at least one program in the set to pass all test cases in code generation application. To address this problem, we develop a simple and effective conformal inference algorithm referred to as Generative Prediction Sets (GPS). Given a set of calibration examples and black-box access to a deep generative model, GPS can generate prediction sets with provable guarantees. The key insight behind GPS is to exploit the inherent structure within the distribution over the minimum number of samples needed to obtain an admissible output to develop a simple conformal regression approach over the minimum number of samples. Experiments on multiple datasets for code and math word problems using different large language models demonstrate the efficacy of GPS over state-of-the-art methods.