Streaming Generation of Co-Speech Gestures via Accelerated Rolling Diffusion
作者: Evgeniia Vu, Andrei Boiarov, Dmitry Vetrov
分类: cs.LG, cs.CV, cs.HC
发布日期: 2025-03-13 (更新: 2025-11-19)
备注: Accepted at the 40th AAAI Conference on Artificial Intelligence (AAAI-26) Main Track
💡 一句话要点
提出加速滚动扩散的流式手势生成框架,实现实时协同语音手势生成
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 协同语音手势生成 滚动扩散模型 流式生成 实时生成 噪声调度 深度学习
📋 核心要点
- 现有协同语音手势生成方法难以兼顾时间连贯性和高效采样,限制了实时应用。
- 论文提出加速滚动扩散框架,通过结构化噪声调度实现连续手势生成,无需后处理。
- 实验表明,该框架在ZEGGS和BEAT数据集上优于现有方法,并实现了高达4倍的加速。
📝 摘要(中文)
本文提出了一种用于流式手势生成的新框架,该框架通过结构化的渐进噪声调度扩展了滚动扩散模型,从而在保持真实性和多样性的同时,实现无缝的长序列运动合成。该框架与现有的基于扩散的手势生成模型普遍兼容,将它们转换为能够连续生成而无需后处理的流式方法。在ZEGGS和BEAT数据集上的评估表明,该框架始终优于最先进的基线方法,证明了其作为实时协同语音手势合成的通用且高效的解决方案的有效性。此外,本文还提出了一种滚动扩散阶梯加速(RDLA)方法,该方法采用基于阶梯的噪声调度策略来同时去噪多个帧,从而显著提高采样效率,同时保持运动一致性,在实验中实现了高达4倍的加速,并具有很高的视觉保真度和时间连贯性。全面的用户研究进一步验证了该框架生成与音频输入紧密同步的逼真、多样化手势的能力。
🔬 方法详解
问题定义:论文旨在解决实时协同语音手势生成问题。现有方法在生成长序列手势时,通常需要大量的计算资源,难以保证实时性,并且容易出现时间上的不连贯。此外,现有的基于扩散模型的方法通常需要后处理才能实现流式生成。
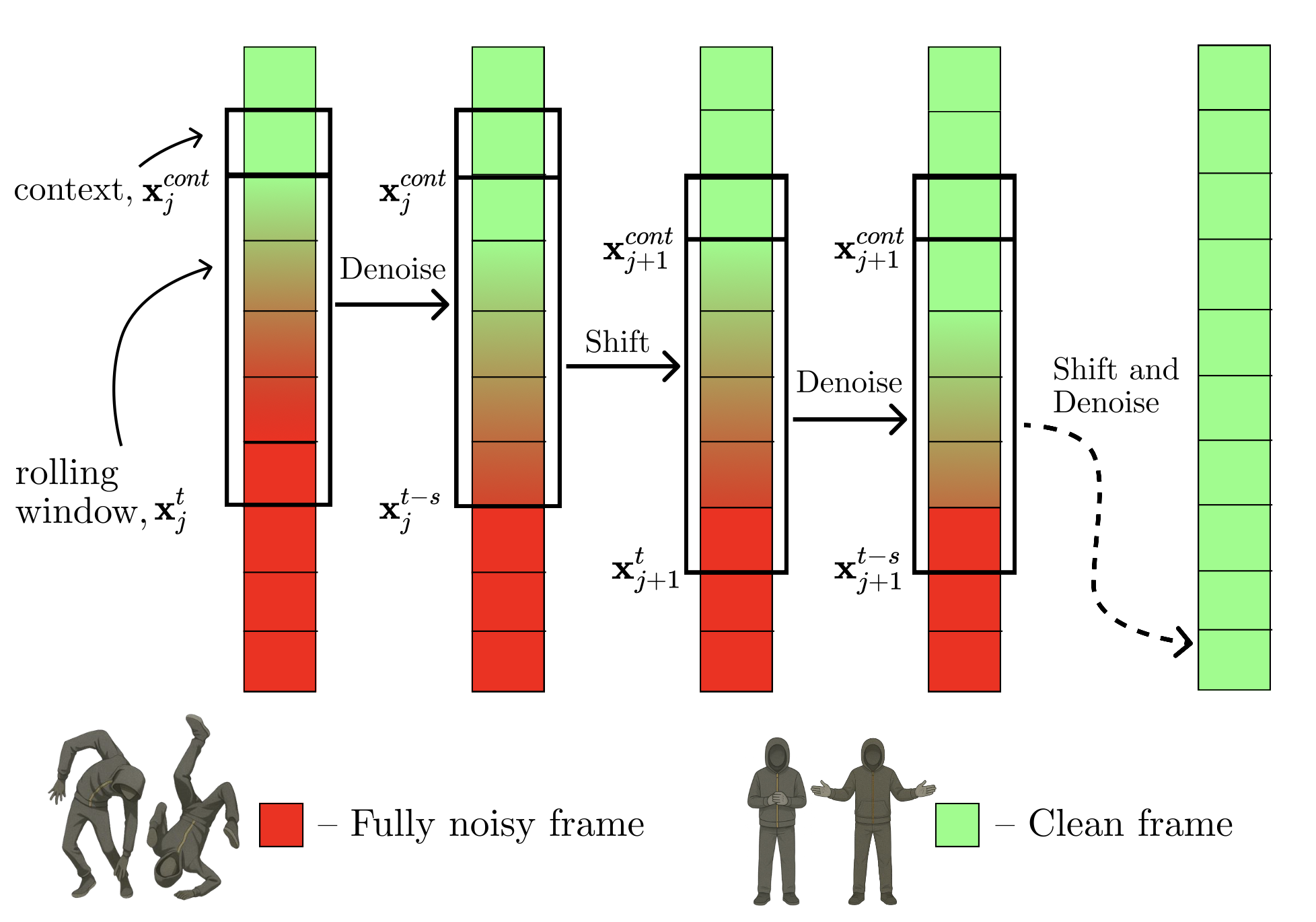
核心思路:论文的核心思路是利用滚动扩散模型,并引入结构化的渐进噪声调度策略,使得模型能够在生成手势的同时,保持时间上的连贯性,并提高采样效率。通过这种方式,模型可以实现实时的流式手势生成,而无需额外的后处理。
技术框架:整体框架基于扩散模型,主要包含以下几个模块:1) 音频特征提取模块,用于提取音频的特征表示;2) 手势生成模块,基于滚动扩散模型,根据音频特征生成手势序列;3) 噪声调度模块,采用结构化的渐进噪声调度策略,控制扩散过程中的噪声水平;4) 加速模块(RDLA),采用阶梯式噪声调度,并行处理多个帧。
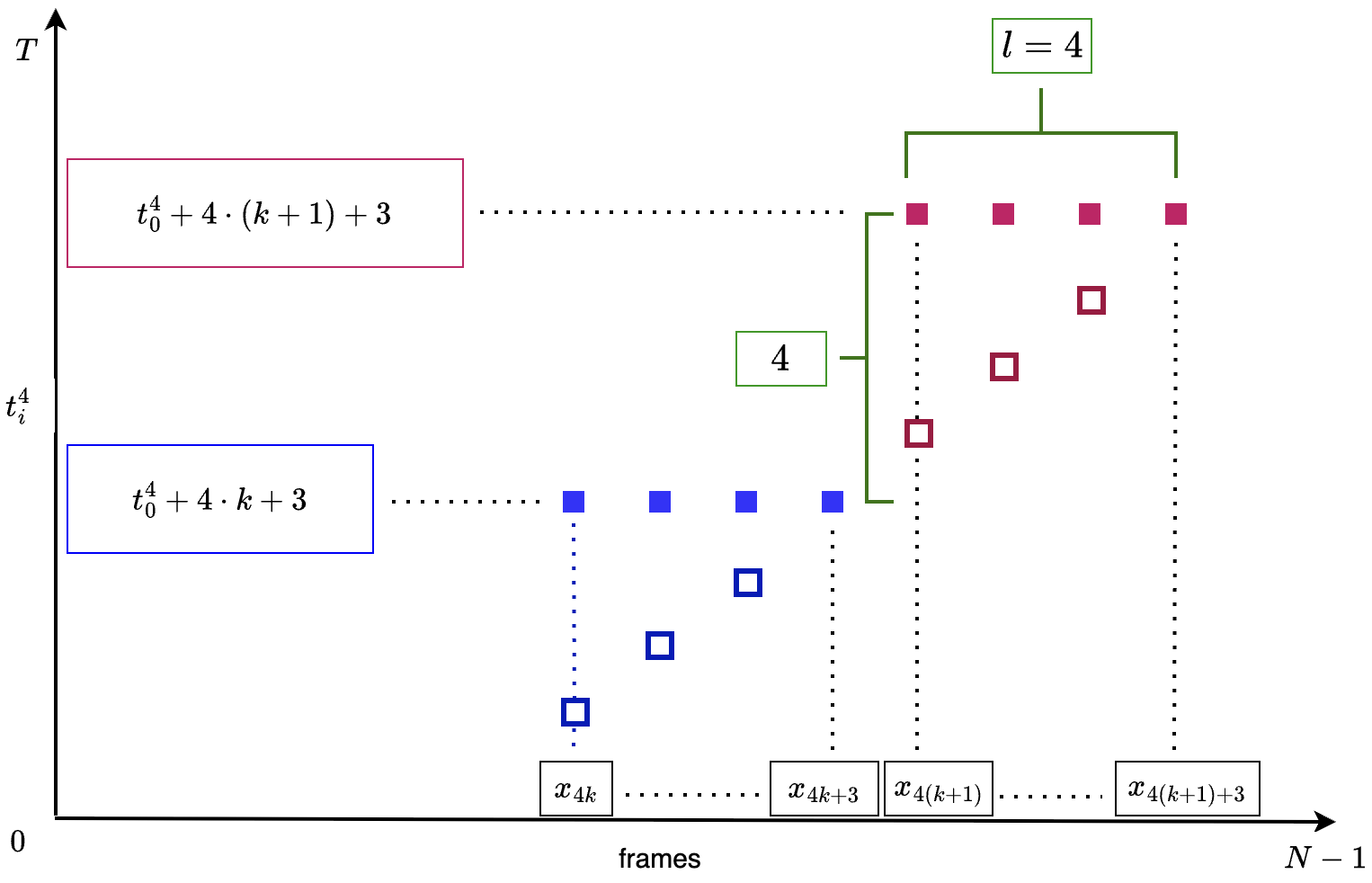
关键创新:论文的关键创新在于提出了加速滚动扩散框架,并引入了结构化的渐进噪声调度策略和滚动扩散阶梯加速(RDLA)方法。结构化的噪声调度使得模型能够更好地控制生成过程中的时间连贯性,而RDLA方法则通过并行处理多个帧,显著提高了采样效率。
关键设计:论文中,噪声调度策略采用了一种阶梯式的结构,使得模型能够同时处理多个帧,从而提高采样效率。损失函数方面,采用了标准的扩散模型损失函数,并可能结合了额外的正则化项,以保证生成手势的自然性和多样性。具体的网络结构细节未知,但可以推测使用了Transformer或类似的序列建模结构。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该框架在ZEGGS和BEAT数据集上均优于现有的最先进方法。通过引入滚动扩散阶梯加速(RDLA)方法,实现了高达4倍的加速,同时保持了较高的视觉保真度和时间连贯性。用户研究也验证了该框架生成的手势与音频输入具有良好的同步性和自然性。
🎯 应用场景
该研究成果可应用于虚拟助手、游戏、人机交互等领域。通过实时生成与语音同步的手势,可以显著提升用户体验,使交互更加自然和生动。未来,该技术有望应用于更广泛的机器人和虚拟现实场景,实现更智能、更人性化的交互。
📄 摘要(原文)
Generating co-speech gestures in real time requires both temporal coherence and efficient sampling. We introduce a novel framework for streaming gesture generation that extends Rolling Diffusion models with structured progressive noise scheduling, enabling seamless long-sequence motion synthesis while preserving realism and diversity. Our framework is universally compatible with existing diffusion-based gesture generation model, transforming them into streaming methods capable of continuous generation without requiring post-processing. We evaluate our framework on ZEGGS and BEAT, strong benchmarks for real-world applicability. Applied to state-of-the-art baselines on both datasets, it consistently outperforms them, demonstrating its effectiveness as a generalizable and efficient solution for real-time co-speech gesture synthesis. We further propose Rolling Diffusion Ladder Acceleration (RDLA), a new approach that employs a ladder-based noise scheduling strategy to simultaneously denoise multiple frames. This significantly improves sampling efficiency while maintaining motion consistency, achieving up to a 4x speedup with high visual fidelity and temporal coherence in our experiments. Comprehensive user studies further validate our framework ability to generate realistic, diverse gestures closely synchronized with the audio input.