Collaborative Speculative Inference for Efficient LLM Inference Serving
作者: Luyao Gao, Jianchun Liu, Hongli Xu, Xichong Zhang, Yunming Liao, Liusheng Huang
分类: cs.DC, cs.LG
发布日期: 2025-03-13 (更新: 2025-05-15)
💡 一句话要点
提出CoSine,通过协同推测加速LLM推理服务,提升资源利用率和吞吐量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测推理 大型语言模型 LLM推理服务 协同推理 异构计算
📋 核心要点
- 现有推测推理方法存在资源利用率低和草稿接受率有限的问题,限制了其可扩展性和整体效率。
- CoSine通过解耦顺序推测解码和并行验证,实现多节点高效协作,并采用token融合机制确保高质量草稿生成。
- 实验表明,CoSine在等效资源成本下,相比基线方法,延迟降低高达23.2%,吞吐量提高32.5%。
📝 摘要(中文)
推测推理是一种很有前景的范式,它使用小型推测模型(SSM)作为起草者来生成草稿token,然后由目标大型语言模型(LLM)并行验证这些token。这种方法通过减少LLM推理延迟和成本,同时保持生成质量,来提高推理服务的效率。然而,现有的推测方法面临着关键挑战,包括资源利用率低和草稿接受率有限,这限制了它们的可扩展性和整体有效性。为了克服这些障碍,我们提出了一种新的推测推理系统CoSine,它将顺序推测解码与并行验证解耦,从而实现多个节点之间的有效协作。具体来说,CoSine根据其专业知识将推理请求路由到专门的起草者,并结合基于置信度的token融合机制来合成来自合作起草者的输出,从而确保高质量的草稿生成。此外,CoSine以流水线方式动态地编排推测解码和验证的执行,采用批量调度来选择性地对请求进行分组,并采用自适应推测控制来最大限度地减少空闲时间。通过优化异构节点协作的并行工作流程,CoSine实时平衡草稿生成和验证吞吐量,从而最大限度地提高资源利用率。实验结果表明,与最先进的推测方法相比,CoSine实现了卓越的性能。值得注意的是,在等效的资源成本下,与基线方法相比,CoSine的延迟降低了高达23.2%,吞吐量提高了32.5%。
🔬 方法详解
问题定义:现有推测推理方法在LLM推理服务中面临资源利用率低和草稿接受率有限的问题。这意味着在相同的硬件资源下,LLM的推理速度和吞吐量无法达到最优,导致服务成本增加,用户体验下降。现有方法难以充分利用异构计算资源,并且在草稿生成和验证之间存在瓶颈。
核心思路:CoSine的核心思路是将顺序推测解码与并行验证解耦,允许多个小型推测模型(SSM)并行工作,并根据各自的专长处理不同的推理请求。通过token融合机制,将多个SSM的输出进行整合,生成高质量的草稿。此外,CoSine采用流水线方式动态编排推测解码和验证,并使用批量调度和自适应推测控制来优化资源利用率。
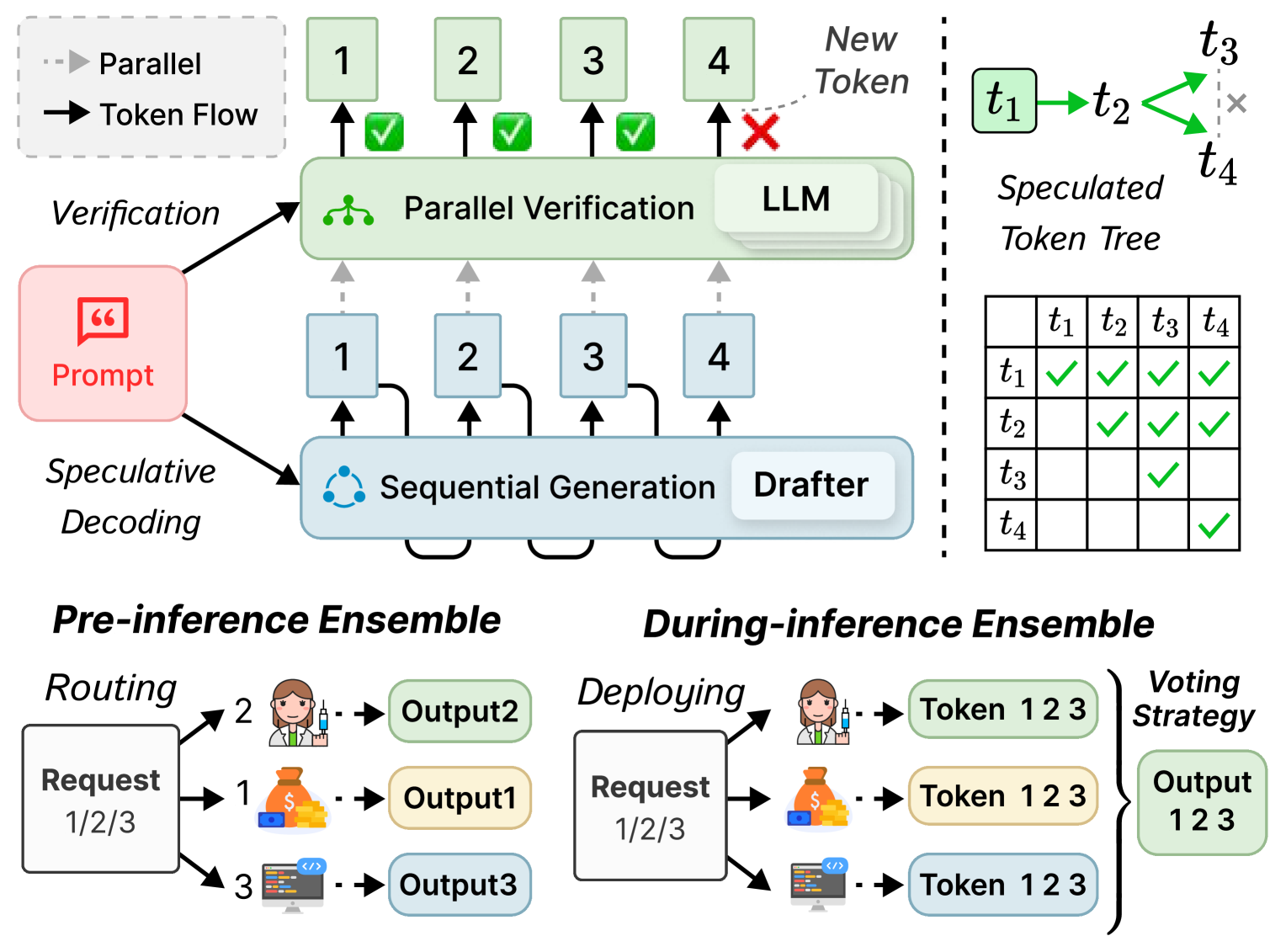
技术框架:CoSine系统包含以下主要模块:1) 请求路由模块:根据请求的特性将其分配给合适的SSM。2) 推测解码模块:多个SSM并行生成草稿token。3) Token融合模块:将多个SSM生成的token进行融合,生成最终的草稿。4) 并行验证模块:LLM并行验证草稿token。5) 调度模块:动态编排推测解码和验证的执行,并进行批量调度和自适应推测控制。
关键创新:CoSine的关键创新在于其协同推测推理机制,允许多个异构的SSM并行工作,并根据各自的专长处理不同的推理请求。这种方法打破了传统推测推理中单个SSM的限制,提高了资源利用率和草稿接受率。此外,CoSine的token融合机制能够有效地整合多个SSM的输出,生成高质量的草稿。
关键设计:CoSine的关键设计包括:1) 基于置信度的Token融合:根据SSM对每个token的置信度,加权融合多个SSM的输出。2) 自适应推测控制:根据LLM的验证结果,动态调整SSM的推测深度。3) 批量调度:将多个推理请求进行批量处理,提高GPU利用率。4) 请求路由策略:根据请求的长度、主题等特征,将其路由到最合适的SSM。
🖼️ 关键图片

📊 实验亮点
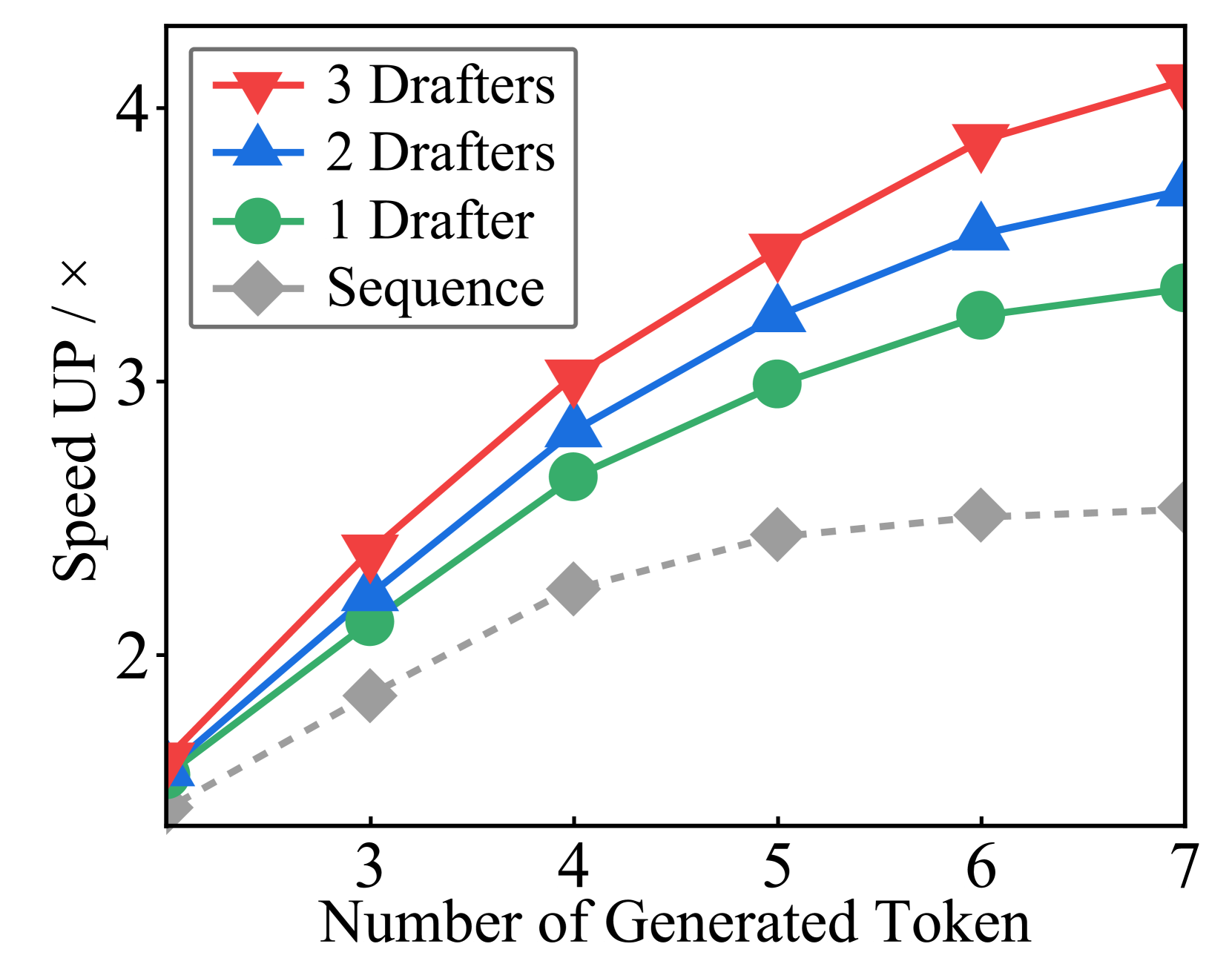
实验结果表明,CoSine在等效资源成本下,相比于现有的推测推理方法,延迟降低了高达23.2%,吞吐量提高了32.5%。这些结果表明CoSine能够有效地提高LLM推理服务的效率,并具有很强的实用价值。此外,实验还验证了CoSine的各个模块的有效性,例如token融合机制和自适应推测控制。
🎯 应用场景
CoSine可应用于各种需要高效LLM推理服务的场景,例如在线问答系统、对话机器人、文本生成应用等。通过降低推理延迟和提高吞吐量,CoSine可以显著提升用户体验,并降低服务成本。此外,CoSine的协同推测推理机制也为未来LLM推理服务的发展提供了新的思路,例如可以利用更多的异构计算资源来进一步提高推理效率。
📄 摘要(原文)
Speculative inference is a promising paradigm employing small speculative models (SSMs) as drafters to generate draft tokens, which are subsequently verified in parallel by the target large language model (LLM). This approach enhances the efficiency of inference serving by reducing LLM inference latency and costs while preserving generation quality. However, existing speculative methods face critical challenges, including inefficient resource utilization and limited draft acceptance, which constrain their scalability and overall effectiveness. To overcome these obstacles, we present CoSine, a novel speculative inference system that decouples sequential speculative decoding from parallel verification, enabling efficient collaboration among multiple nodes. Specifically, CoSine routes inference requests to specialized drafters based on their expertise and incorporates a confidence-based token fusion mechanism to synthesize outputs from cooperating drafters, ensuring high-quality draft generation. Additionally, CoSine dynamically orchestrates the execution of speculative decoding and verification in a pipelined manner, employing batch scheduling to selectively group requests and adaptive speculation control to minimize idle periods. By optimizing parallel workflows through heterogeneous node collaboration, CoSine balances draft generation and verification throughput in real-time, thereby maximizing resource utilization. Experimental results demonstrate that CoSine achieves superior performance compared to state-of-the-art speculative approaches. Notably, with equivalent resource costs, CoSine achieves up to a 23.2% decrease in latency and a 32.5% increase in throughput compared to baseline methods.