Enhance Exploration in Safe Reinforcement Learning with Contrastive Representation Learning
作者: Duc Kien Doan, Bang Giang Le, Viet Cuong Ta
分类: cs.LG, cs.AI
发布日期: 2025-03-13
备注: Accepted at ACIIDS 2025
DOI: 10.1007/978-981-96-5887-9_1
💡 一句话要点
提出基于对比表示学习的安全强化学习探索增强方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 安全强化学习 对比学习 状态表示 探索增强 稀疏奖励
📋 核心要点
- 安全强化学习需要在探索和安全之间权衡,现有领域迁移方法易产生大量误报,限制了探索。
- 论文提出一种基于对比表示学习的方法,区分安全和不安全状态,指导智能体更有效地探索。
- 实验表明,该方法在MiniGrid环境中能够提升探索效率,同时保持良好的安全性。
📝 摘要(中文)
在安全强化学习中,智能体需要在探索行为和安全约束之间取得平衡。领域迁移方法通过从相关环境中学习先验Q函数来避免不安全行为。然而,由于大量的误报,一些安全的行为从未被执行,导致在稀疏奖励环境中探索不足。本文旨在学习一种有效的状态表示,以平衡稀疏奖励环境中的探索和安全优先行为。首先,通过自编码器将图像输入映射到潜在表示。然后,采用对比学习目标来区分安全和不安全状态。在学习阶段,潜在距离用于构建额外的安全检查,允许智能体在访问不安全状态时偏向探索。实验在三个基于导航的MiniGrid环境中进行,结果表明该方法能够更好地探索环境,同时保持安全性和效率之间的良好平衡。
🔬 方法详解
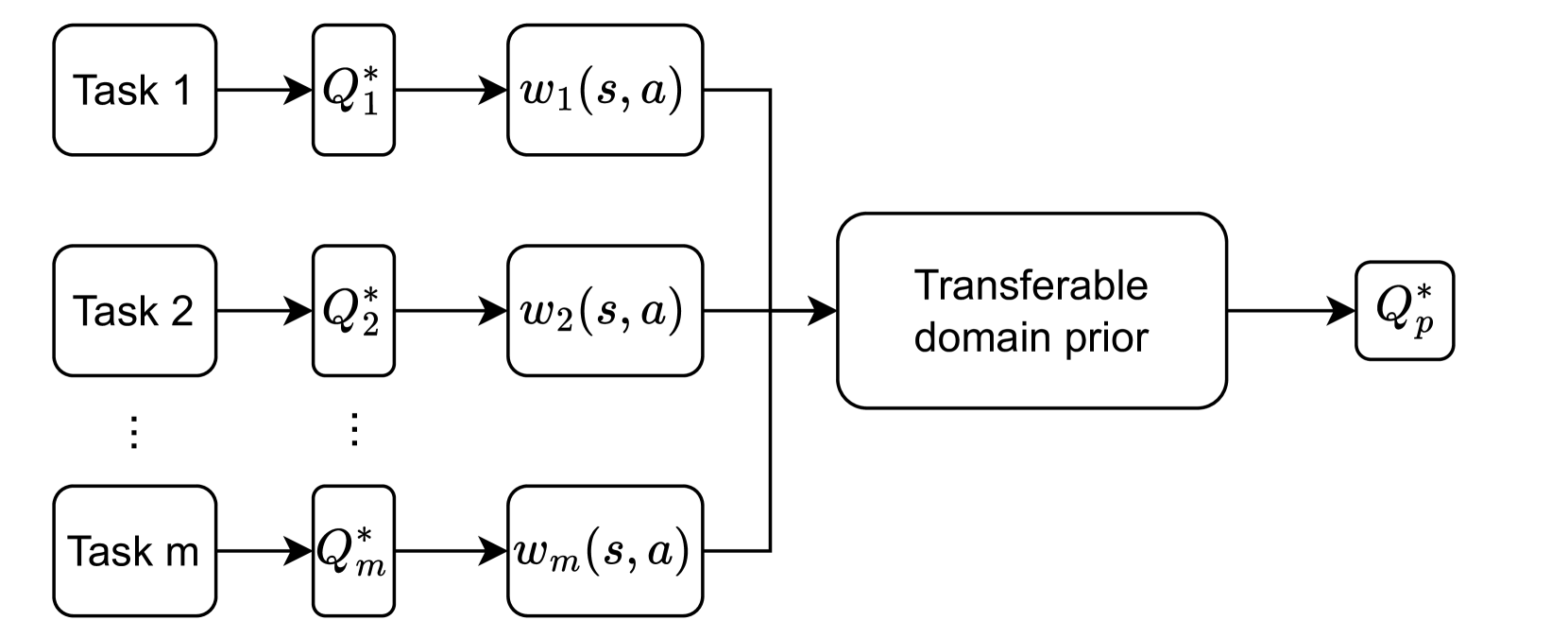
问题定义:安全强化学习需要在探索新策略和遵守安全约束之间找到平衡。现有的领域迁移方法虽然可以利用相关环境的知识来指导探索,但容易产生大量的“假阳性”安全警告,即错误地将安全状态识别为不安全状态,从而限制了智能体的探索行为,尤其是在奖励稀疏的环境中,智能体可能因为过于保守而无法发现最优策略。
核心思路:本文的核心思路是通过学习一种能够有效区分安全状态和不安全状态的潜在表示,来指导智能体的探索行为。具体来说,通过对比学习,使得相似的安全状态在潜在空间中彼此靠近,而与不安全状态远离。这样,智能体就可以利用这种潜在表示来判断当前状态的安全性,并在必要时调整探索策略。
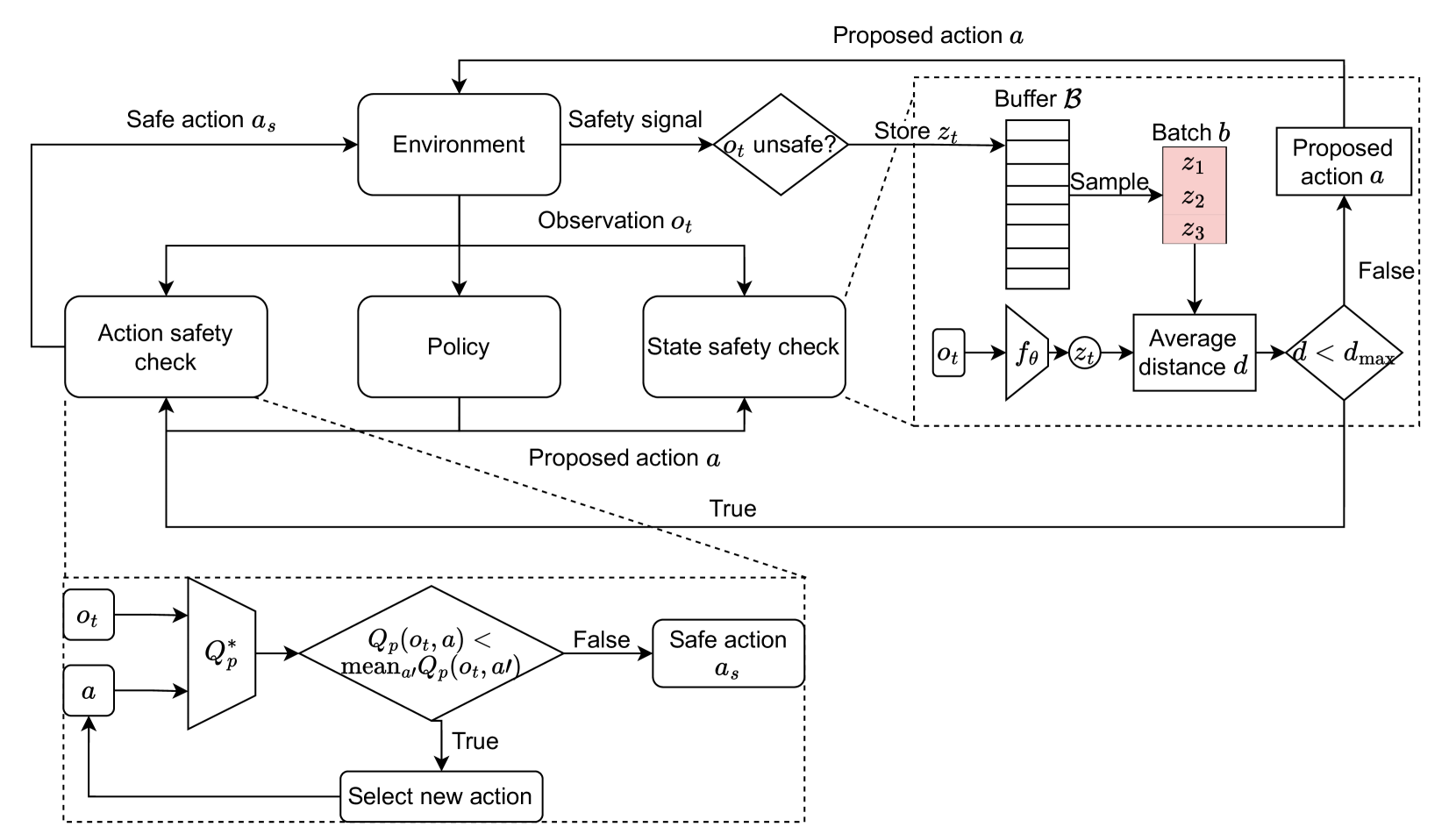
技术框架:该方法的技术框架主要包括以下几个模块:1) 自编码器:用于将图像输入映射到低维的潜在表示;2) 对比学习模块:用于学习区分安全状态和不安全状态的潜在表示;3) 安全检查模块:利用学习到的潜在表示,判断当前状态的安全性,并根据判断结果调整探索策略;4) 强化学习智能体:利用调整后的探索策略与环境交互,学习最优策略。
关键创新:该方法最重要的技术创新点在于将对比学习引入到安全强化学习中,用于学习状态的安全表示。与传统的安全强化学习方法相比,该方法能够更有效地区分安全状态和不安全状态,从而避免了过多的“假阳性”安全警告,提高了探索效率。
关键设计:在对比学习模块中,使用了InfoNCE损失函数来最大化安全状态之间的相似性,并最小化安全状态与不安全状态之间的相似性。安全检查模块使用潜在空间中的距离作为安全指标,如果当前状态的潜在表示与已知安全状态的潜在表示的距离超过一定阈值,则认为该状态是不安全的,并调整探索策略。具体的阈值需要根据实验进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在三个MiniGrid导航环境中均取得了显著的性能提升。与基线方法相比,该方法能够在保持安全性的前提下,更快地找到目标,并获得更高的平均奖励。具体来说,该方法能够减少不必要的安全约束,从而允许智能体更自由地探索环境,发现更优的策略。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、医疗决策等需要在安全约束下进行探索的领域。例如,在机器人导航中,可以利用该方法学习安全区域的表示,引导机器人在安全区域内进行探索,避免进入危险区域。在自动驾驶中,可以学习安全驾驶行为的表示,引导车辆进行安全驾驶,避免发生交通事故。
📄 摘要(原文)
In safe reinforcement learning, agent needs to balance between exploration actions and safety constraints. Following this paradigm, domain transfer approaches learn a prior Q-function from the related environments to prevent unsafe actions. However, because of the large number of false positives, some safe actions are never executed, leading to inadequate exploration in sparse-reward environments. In this work, we aim to learn an efficient state representation to balance the exploration and safety-prefer action in a sparse-reward environment. Firstly, the image input is mapped to latent representation by an auto-encoder. A further contrastive learning objective is employed to distinguish safe and unsafe states. In the learning phase, the latent distance is used to construct an additional safety check, which allows the agent to bias the exploration if it visits an unsafe state. To verify the effectiveness of our method, the experiment is carried out in three navigation-based MiniGrid environments. The result highlights that our method can explore the environment better while maintaining a good balance between safety and efficiency.