Efficient Federated Fine-Tuning of Large Language Models with Layer Dropout
作者: Shilong Wang, Jianchun Liu, Hongli Xu, Jiaming Yan, Xianjun Gao
分类: cs.LG, cs.AI, cs.DC
发布日期: 2025-03-13
备注: 13 pages
💡 一句话要点
提出DropPEFT,通过层Dropout高效联邦微调大型语言模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大型语言模型 参数高效微调 层Dropout 资源受限设备
📋 核心要点
- 现有联邦微调方法在大型语言模型上效率低,计算和内存负担大,难以在资源受限的终端设备上部署。
- DropPEFT通过随机Transformer层dropout,使设备在训练时停用部分LLM层,从而降低计算负载和内存占用。
- DropPEFT采用探索-利用策略,自适应地为设备分配最佳dropout比率,实验表明能显著加速收敛并减少内存占用。
📝 摘要(中文)
微调在使预训练的大型语言模型(LLM)从通用语言理解发展到特定任务专业知识方面起着至关重要的作用。为了保护用户数据隐私,联邦微调经常被采用,并且已经成为事实上的范例。然而,由于LLM的复杂性和终端设备的资源约束之间的矛盾,联邦微调的效率非常低,导致难以承受的微调开销。现有文献主要利用参数高效微调技术来降低通信成本,但计算和内存负担仍然对开发者构成重大挑战。本文提出了DropPEFT,这是一个创新的联邦PEFT框架,它采用了一种新颖的随机Transformer层dropout方法,使设备能够在训练期间停用很大一部分LLM层,从而消除相关的计算负载和内存占用。在DropPEFT中,一个关键的挑战是正确配置层的dropout比率,因为开销和训练性能对此设置高度敏感。为了解决这个挑战,我们通过探索-利用策略自适应地为设备分配最佳dropout比率配置,从而实现高效且有效的微调。大量实验表明,与最先进的方法相比,DropPEFT可以在模型收敛方面实现1.3-6.3倍的加速,并在内存占用方面减少40%-67%。
🔬 方法详解
问题定义:论文旨在解决联邦环境下,大型语言模型(LLM)微调时计算和内存开销过大的问题。现有的参数高效微调方法(PEFT)虽然降低了通信成本,但设备端的计算和内存负担仍然很高,限制了LLM在资源受限设备上的应用。
核心思路:论文的核心思路是通过在Transformer层上引入随机dropout机制,使得设备在训练过程中可以动态地选择性地关闭部分层,从而减少计算量和内存占用。这种方法允许在保持模型性能的同时,显著降低设备端的资源需求。
技术框架:DropPEFT框架主要包含以下几个阶段:1)初始化:所有设备共享一个预训练的LLM;2)层Dropout:每个设备根据分配的dropout比率随机关闭部分Transformer层;3)本地训练:设备仅在激活的层上进行本地微调;4)参数聚合:服务器收集并聚合来自各个设备的参数更新;5)模型更新:服务器将聚合后的更新应用到全局模型。
关键创新:DropPEFT的关键创新在于:1)引入了随机Transformer层dropout机制,允许设备动态地调整计算负载;2)提出了基于探索-利用策略的自适应dropout比率分配方法,能够根据设备的资源状况和训练进度,动态地调整每个设备的dropout比率,从而实现高效的微调。
关键设计:在DropPEFT中,dropout比率的配置至关重要。论文采用了一种探索-利用策略来优化dropout比率。具体来说,每个设备在训练初期会随机探索不同的dropout比率配置,并根据训练效果进行评估。随着训练的进行,设备会逐渐倾向于选择表现更好的dropout比率配置,从而实现对最优dropout比率的自适应调整。损失函数采用标准的交叉熵损失函数,并对激活的层进行梯度更新。
🖼️ 关键图片
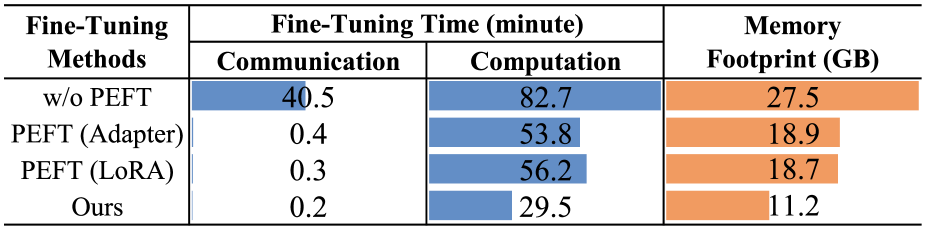
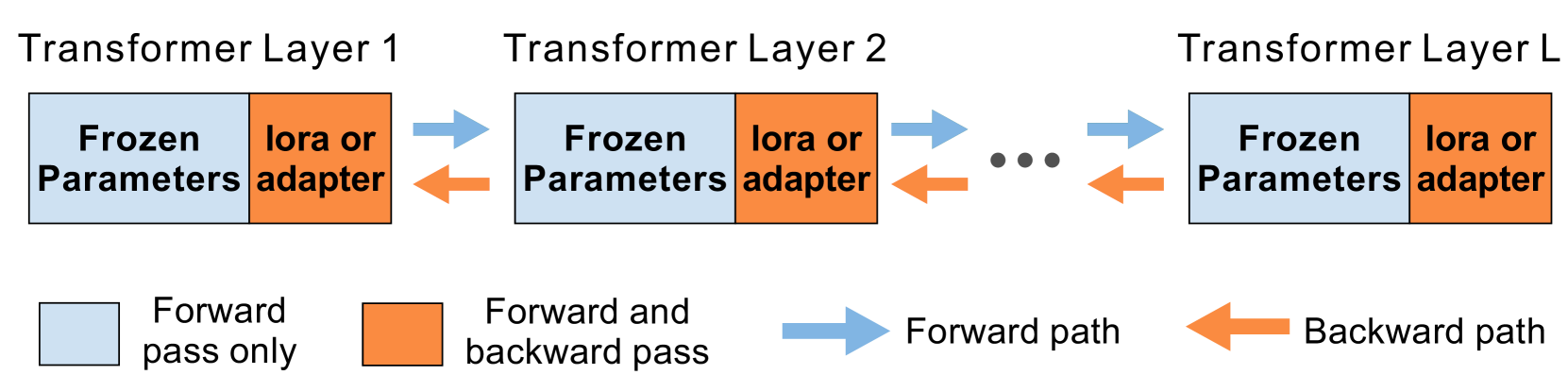
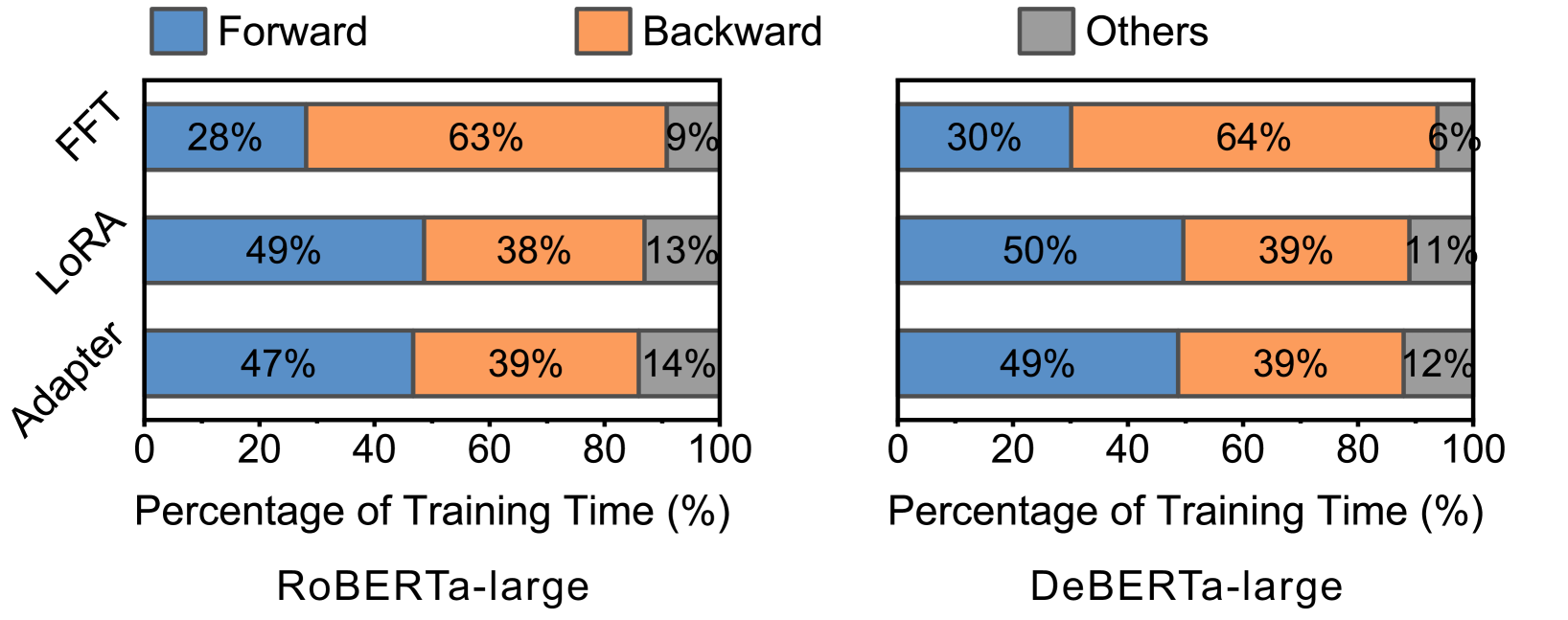
📊 实验亮点
实验结果表明,DropPEFT在模型收敛速度上比现有方法快1.3-6.3倍,并且能够减少40%-67%的内存占用。这些结果表明,DropPEFT能够在显著降低计算和内存开销的同时,保持甚至提高模型的性能,具有很强的实用价值。
🎯 应用场景
DropPEFT适用于各种需要联邦学习的场景,尤其是在终端设备资源受限的情况下,例如移动设备上的个性化语言模型微调、边缘计算环境下的智能助手训练等。该研究有助于推动大型语言模型在隐私保护和资源受限环境下的应用,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
Fine-tuning plays a crucial role in enabling pre-trained LLMs to evolve from general language comprehension to task-specific expertise. To preserve user data privacy, federated fine-tuning is often employed and has emerged as the de facto paradigm. However, federated fine-tuning is prohibitively inefficient due to the tension between LLM complexity and the resource constraint of end devices, incurring unaffordable fine-tuning overhead. Existing literature primarily utilizes parameter-efficient fine-tuning techniques to mitigate communication costs, yet computational and memory burdens continue to pose significant challenges for developers. This work proposes DropPEFT, an innovative federated PEFT framework that employs a novel stochastic transformer layer dropout method, enabling devices to deactivate a considerable fraction of LLMs layers during training, thereby eliminating the associated computational load and memory footprint. In DropPEFT, a key challenge is the proper configuration of dropout ratios for layers, as overhead and training performance are highly sensitive to this setting. To address this challenge, we adaptively assign optimal dropout-ratio configurations to devices through an exploration-exploitation strategy, achieving efficient and effective fine-tuning. Extensive experiments show that DropPEFT can achieve a 1.3-6.3\times speedup in model convergence and a 40%-67% reduction in memory footprint compared to state-of-the-art methods.