Accuracy of Discretely Sampled Stochastic Policies in Continuous-time Reinforcement Learning
作者: Yanwei Jia, Du Ouyang, Yufei Zhang
分类: cs.LG, math.NA, math.OC
发布日期: 2025-03-13 (更新: 2025-10-02)
💡 一句话要点
针对连续时间强化学习,提出离散采样随机策略的精度分析框架
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 连续时间强化学习 随机策略 离散采样 收敛性分析 策略评估 策略梯度 控制理论 弱收敛
📋 核心要点
- 连续时间强化学习中,随机策略的执行和评估面临挑战,现有方法缺乏对离散采样影响的理论分析。
- 论文提出一种离散时间采样框架,将随机策略转化为分段常数控制,并分析采样间隔对策略性能的影响。
- 论文证明了当采样间隔趋近于零时,系统状态会收敛到期望状态,并给出了收敛速度的理论保证。
📝 摘要(中文)
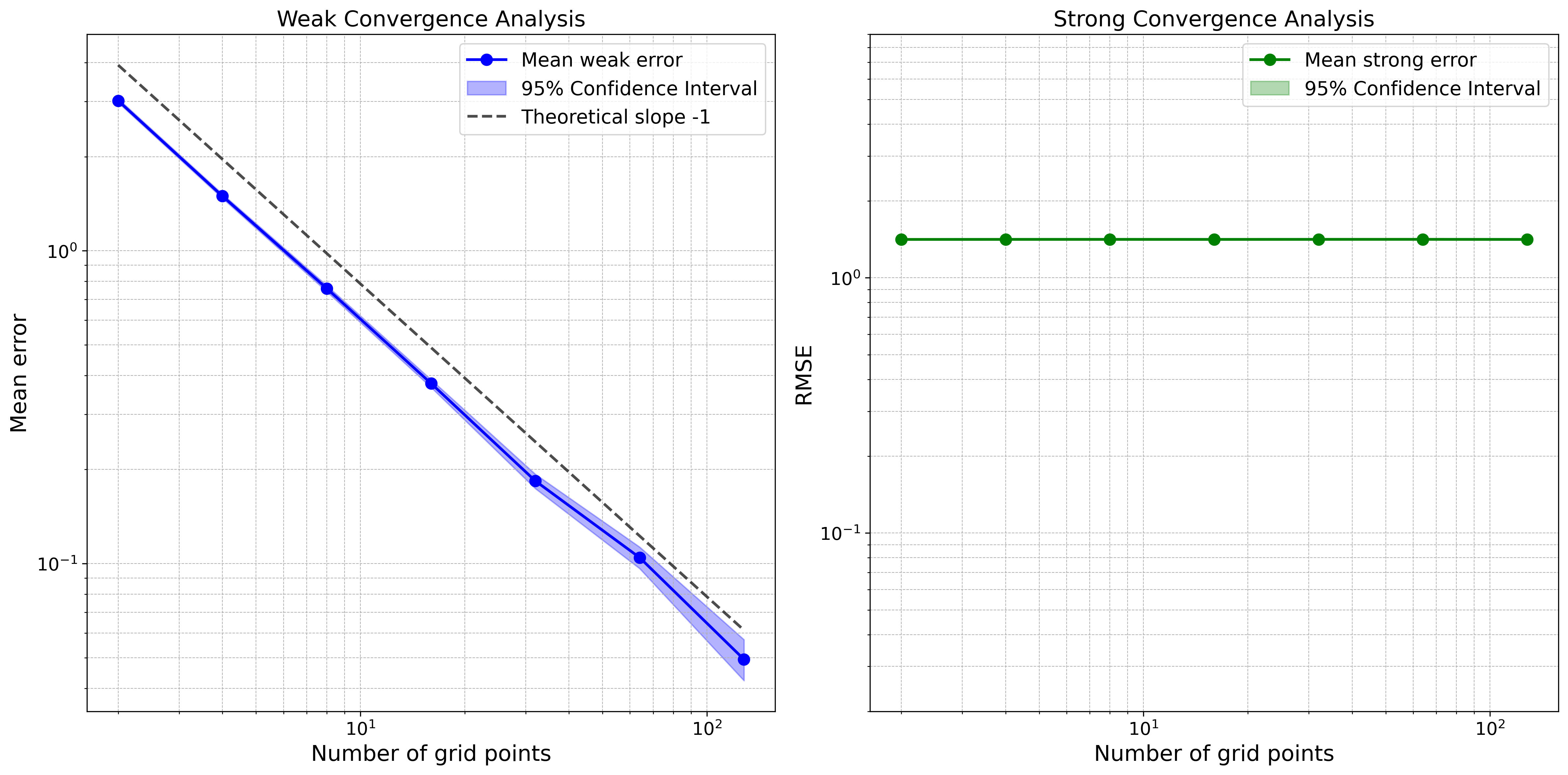
随机策略(又称松弛控制)广泛应用于连续时间强化学习算法中。然而,在连续时间环境中执行随机策略并评估其性能仍然是未解决的挑战。本文介绍并严格分析了一种策略执行框架,该框架在离散时间点从随机策略中采样动作,并将它们实现为分段常数控制。我们证明,当采样网格大小趋于零时,受控状态过程弱收敛于具有根据随机策略聚合的系数的动力学。我们基于系数的正则性显式地量化了收敛速度,并为足够正则的系数建立了最优的一阶收敛速度。此外,我们证明了一个 1/2 阶弱收敛速度,该速度以高概率在采样噪声上一致成立,并且在没有波动率控制的情况下,为系统噪声的每个实现建立了 1/2 阶路径收敛。基于这些结果,我们分析了基于离散时间观测的各种策略评估和策略梯度估计器的偏差和方差。我们的结果为[H. Wang, T. Zariphopoulou, and X.Y. Zhou, J. Mach. Learn. Res., 21 (2020), pp. 1-34]中的探索性随机控制框架提供了理论依据。
🔬 方法详解
问题定义:在连续时间强化学习中,如何有效地执行和评估随机策略是一个关键问题。直接在连续时间域执行随机策略在实际中是不可行的。现有的方法通常采用离散时间采样的方式来近似连续时间的策略,但缺乏对这种近似方法的误差分析和收敛性保证。因此,需要研究离散采样对策略性能的影响,并提供理论依据来指导实际应用。
核心思路:论文的核心思路是将连续时间的随机策略通过离散时间采样的方式进行近似,并将采样得到的动作作为分段常数控制输入到连续时间系统中。通过分析采样间隔与系统状态之间的关系,研究当采样间隔趋近于零时,系统状态的收敛性。这种方法将连续时间问题转化为离散时间问题进行分析,从而简化了问题的复杂度。
技术框架:论文的技术框架主要包括以下几个部分:1) 定义连续时间随机控制系统;2) 引入离散时间采样策略,将随机策略转化为分段常数控制;3) 分析离散时间采样对系统状态的影响,包括收敛性分析和收敛速度分析;4) 基于收敛性分析,研究策略评估和策略梯度估计器的偏差和方差。
关键创新:论文的关键创新在于对离散采样随机策略在连续时间强化学习中的精度进行了严格的理论分析。具体来说,论文证明了当采样间隔趋近于零时,系统状态会弱收敛到期望状态,并给出了收敛速度的显式表达式。此外,论文还分析了策略评估和策略梯度估计器的偏差和方差,为实际应用提供了理论指导。
关键设计:论文的关键设计包括:1) 采用分段常数控制来近似连续时间的随机策略;2) 使用弱收敛的概念来描述系统状态的收敛性;3) 基于系数的正则性来量化收敛速度;4) 分析策略评估和策略梯度估计器的偏差和方差,为实际应用提供指导。
🖼️ 关键图片

📊 实验亮点
论文证明了当采样网格大小趋于零时,受控状态过程弱收敛于具有根据随机策略聚合的系数的动力学,并建立了最优的一阶收敛速度。此外,论文还证明了一个 1/2 阶弱收敛速度,该速度以高概率在采样噪声上一致成立,并且在没有波动率控制的情况下,为系统噪声的每个实现建立了 1/2 阶路径收敛。
🎯 应用场景
该研究成果可应用于机器人控制、金融工程、最优控制等领域。通过对离散采样随机策略的精度分析,可以更好地设计连续时间强化学习算法,提高算法的性能和稳定性。例如,在机器人控制中,可以利用该理论来设计更加精确的控制策略,从而提高机器人的运动精度和效率。
📄 摘要(原文)
Stochastic policies (also known as relaxed controls) are widely used in continuous-time reinforcement learning algorithms. However, executing a stochastic policy and evaluating its performance in a continuous-time environment remain open challenges. This work introduces and rigorously analyzes a policy execution framework that samples actions from a stochastic policy at discrete time points and implements them as piecewise constant controls. We prove that as the sampling mesh size tends to zero, the controlled state process converges weakly to the dynamics with coefficients aggregated according to the stochastic policy. We explicitly quantify the convergence rate based on the regularity of the coefficients and establish an optimal first-order convergence rate for sufficiently regular coefficients. Additionally, we prove a $1/2$-order weak convergence rate that holds uniformly over the sampling noise with high probability, and establish a $1/2$-order pathwise convergence for each realization of the system noise in the absence of volatility control. Building on these results, we analyze the bias and variance of various policy evaluation and policy gradient estimators based on discrete-time observations. Our results provide theoretical justification for the exploratory stochastic control framework in [H. Wang, T. Zariphopoulou, and X.Y. Zhou, J. Mach. Learn. Res., 21 (2020), pp. 1-34].