PluralLLM: Pluralistic Alignment in LLMs via Federated Learning
作者: Mahmoud Srewa, Tianyu Zhao, Salma Elmalaki
分类: cs.LG, cs.CL
发布日期: 2025-03-13
💡 一句话要点
PluralLLM:通过联邦学习实现LLM中的多元化对齐
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大型语言模型 偏好对齐 隐私保护 多元化 Transformer FedAvg
📋 核心要点
- 现有LLM对齐方法依赖集中式数据,面临计算成本高昂和隐私泄露的挑战。
- PluralLLM利用联邦学习,允许多个用户组在不共享数据的情况下协作训练偏好预测器。
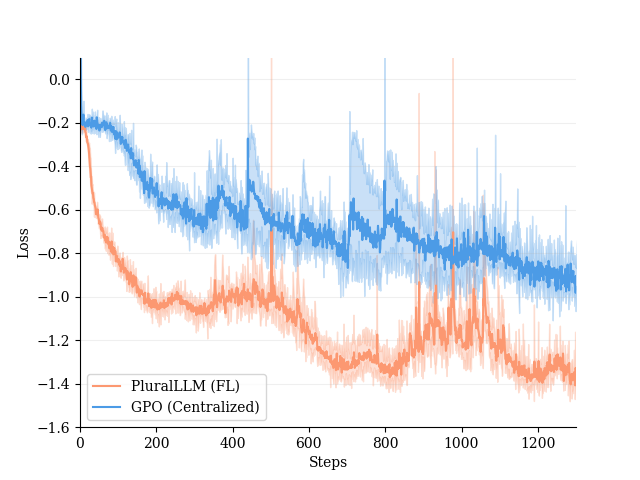
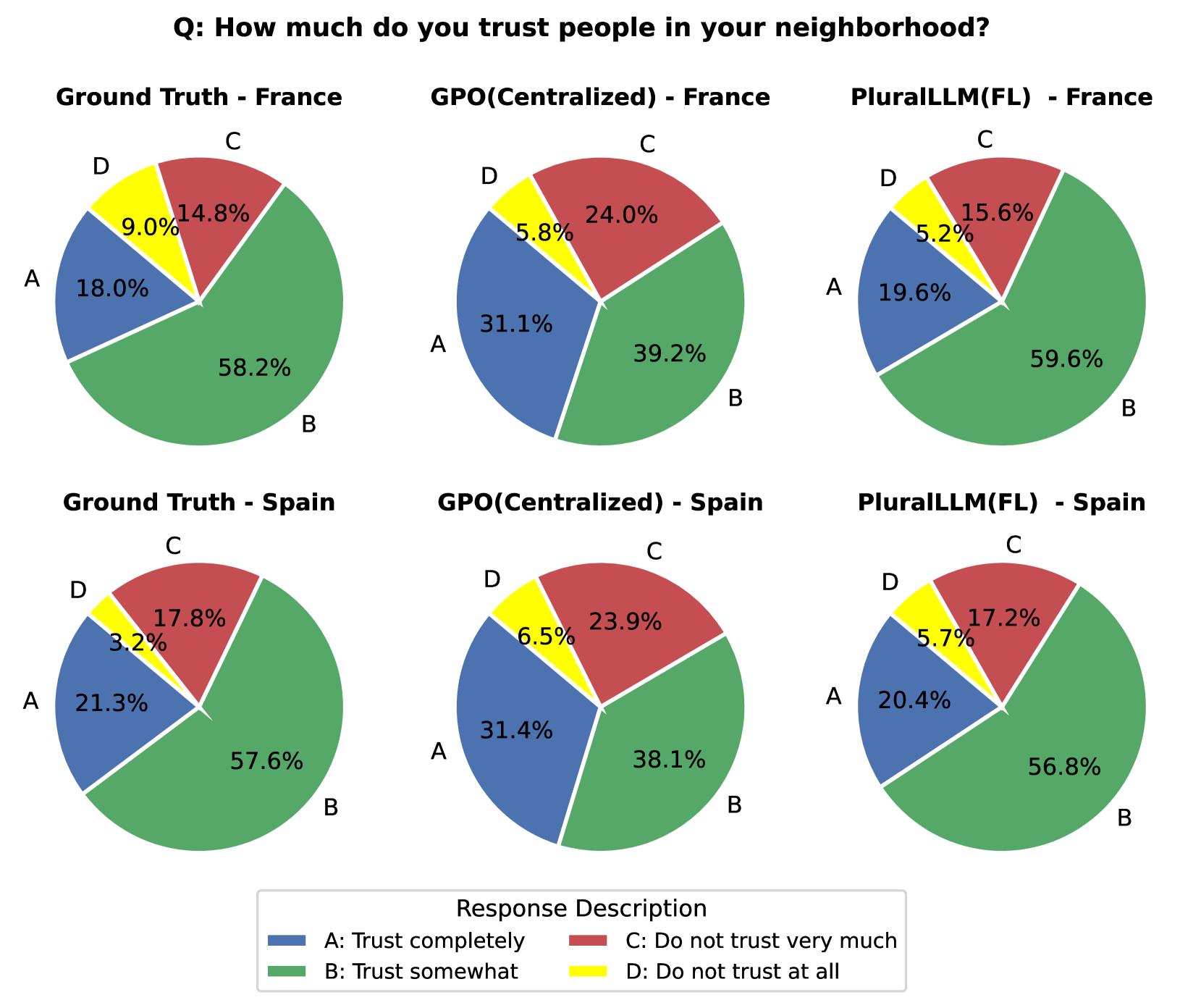
- 实验表明,PluralLLM在收敛速度、对齐分数和群体公平性方面均优于集中式方法。
📝 摘要(中文)
确保大型语言模型(LLM)与多样化的人类偏好对齐,同时保护隐私和公平性仍然是一个挑战。现有的方法,如基于人类反馈的强化学习(RLHF),依赖于集中式数据收集,这使得它们在计算上昂贵且侵犯隐私。我们引入了PluralLLM,一种基于联邦学习的方法,它使多个用户组能够协作训练基于Transformer的偏好预测器,而无需共享敏感数据,该预测器也可以作为对齐LLM的奖励模型。我们的方法利用联邦平均(FedAvg)来有效地聚合偏好更新,实现了46%的更快收敛速度,4%的对齐分数提升,以及与集中式训练几乎相同的群体公平性指标。在Q/A偏好对齐任务上的评估表明,PluralLLM提供了一种可扩展且保护隐私的替代方案,用于将LLM与多样化的人类价值观对齐。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)与不同人群的偏好对齐问题。现有方法,如RLHF,通常需要集中收集用户数据,这不仅带来了隐私风险,也限制了模型对不同价值观的适应性。此外,集中式训练的计算成本也很高,难以扩展到大规模用户群体。
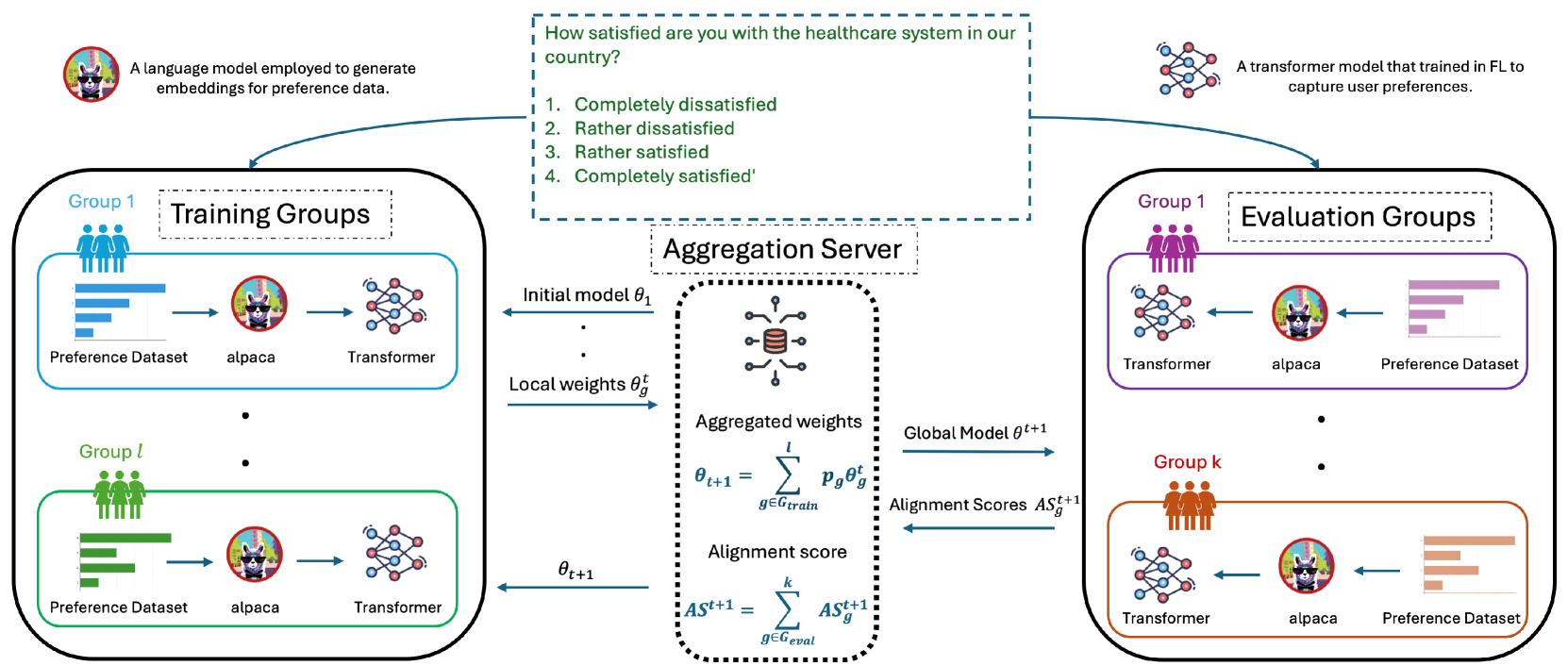
核心思路:PluralLLM的核心思路是利用联邦学习,让不同的用户群体在本地训练偏好预测模型,然后通过联邦平均(FedAvg)算法将这些本地模型聚合起来,得到一个全局的偏好预测模型。这样既能保护用户隐私,又能使模型学习到不同群体的偏好,实现多元化对齐。
技术框架:PluralLLM的整体框架包括以下几个主要步骤:1) 各个用户组在本地使用自己的数据训练偏好预测模型(基于Transformer);2) 各个用户组将训练好的模型参数上传到中央服务器;3) 中央服务器使用FedAvg算法对各个用户组的模型参数进行聚合,得到全局模型;4) 中央服务器将全局模型分发给各个用户组;5) 各个用户组使用全局模型作为奖励模型,对本地的LLM进行微调,使其与本地用户的偏好对齐。
关键创新:PluralLLM的关键创新在于将联邦学习应用于LLM的偏好对齐。与传统的集中式训练方法相比,PluralLLM能够在保护用户隐私的前提下,学习到不同群体的偏好,实现多元化对齐。此外,PluralLLM还通过FedAvg算法实现了高效的模型聚合,降低了计算成本。
关键设计:PluralLLM的关键设计包括:1) 使用Transformer作为偏好预测模型的基础架构;2) 使用FedAvg算法进行模型聚合,具体参数设置未知;3) 使用偏好预测模型的输出作为奖励信号,对LLM进行微调,损失函数未知;4) 针对Q/A偏好对齐任务设计了特定的评估指标,具体指标未知。
🖼️ 关键图片
📊 实验亮点
PluralLLM在Q/A偏好对齐任务上取得了显著的实验结果。与集中式训练相比,PluralLLM实现了46%的更快收敛速度和4%的对齐分数提升。此外,PluralLLM在群体公平性方面也与集中式训练相当,表明该方法能够在保护隐私的同时,实现良好的性能和公平性。
🎯 应用场景
PluralLLM可应用于各种需要个性化和隐私保护的LLM应用场景,例如:智能客服、个性化推荐、教育辅导等。通过学习不同用户群体的偏好,LLM可以提供更符合用户需求的服务,同时保护用户隐私。该研究有助于推动LLM在更广泛的领域得到应用,并促进人工智能技术的公平性和包容性。
📄 摘要(原文)
Ensuring Large Language Models (LLMs) align with diverse human preferences while preserving privacy and fairness remains a challenge. Existing methods, such as Reinforcement Learning from Human Feedback (RLHF), rely on centralized data collection, making them computationally expensive and privacy-invasive. We introduce PluralLLM a federated learning-based approach that enables multiple user groups to collaboratively train a transformer-based preference predictor without sharing sensitive data, which can also serve as a reward model for aligning LLMs. Our method leverages Federated Averaging (FedAvg) to aggregate preference updates efficiently, achieving 46% faster convergence, a 4% improvement in alignment scores, and nearly the same group fairness measure as in centralized training. Evaluated on a Q/A preference alignment task, PluralLLM demonstrates that federated preference learning offers a scalable and privacy-preserving alternative for aligning LLMs with diverse human values.