Representation Retrieval Learning for Heterogeneous Data Integration
作者: Qi Xu, Annie Qu
分类: cs.LG, stat.ME
发布日期: 2025-03-12 (更新: 2025-12-09)
💡 一句话要点
提出表征检索学习框架R2,解决异构数据集成中的预测性能下降问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 异构数据集成 表征学习 多模态学习 稀疏学习 超额风险 选择性集成 机器学习 预测建模
📋 核心要点
- 现有监督学习算法在处理具有协变量偏移、后验漂移和分块缺失等复杂异构性的大规模数据集时,预测性能会显著下降。
- 论文提出表征检索(R2)框架,通过集成表征学习模块字典和数据源特定的稀疏模型,来应对异构数据集成中的挑战。
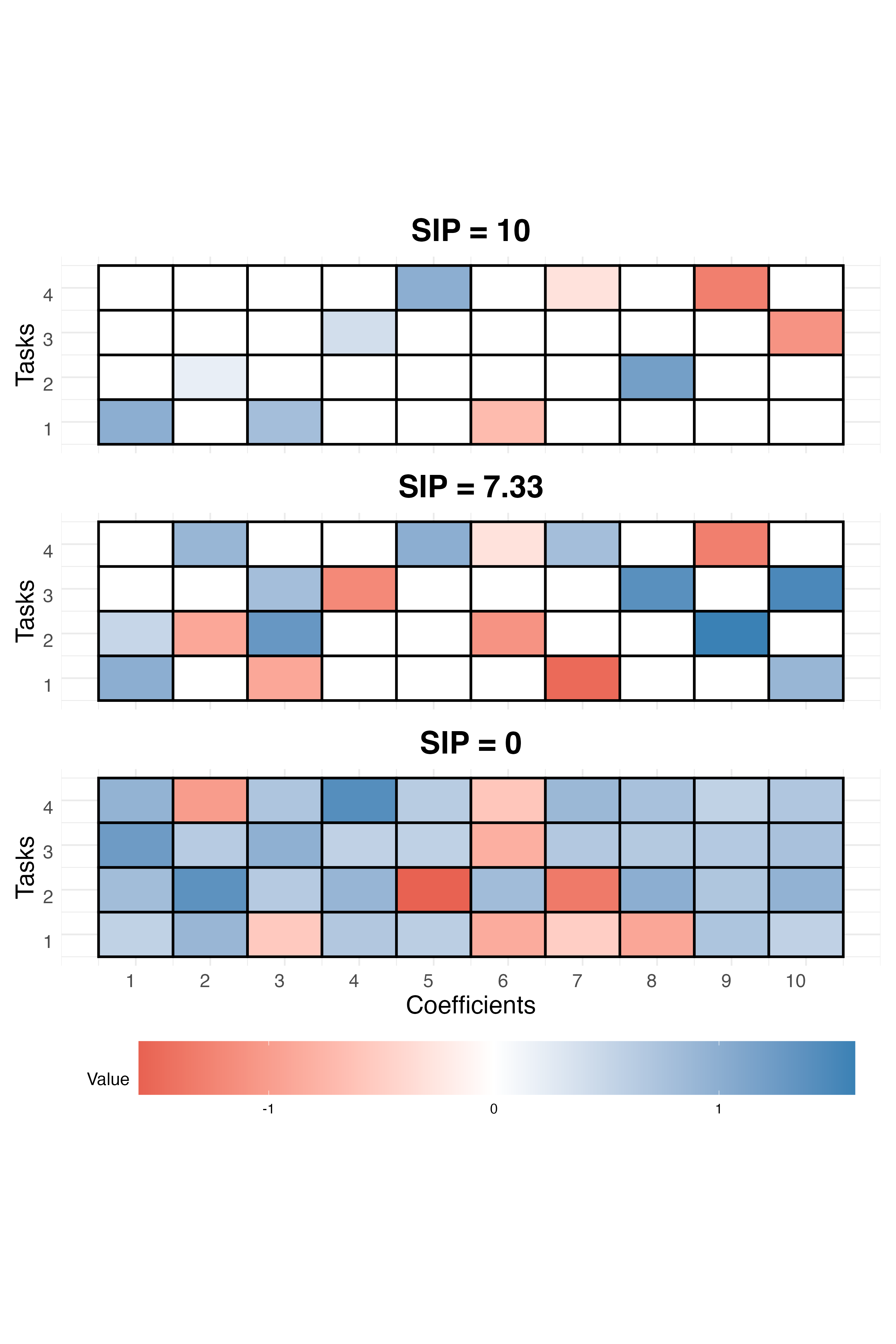
- 理论分析和实验结果表明,R2框架能够有效提高预测性能,选择性集成惩罚(SIP)能够进一步改善超额风险。
📝 摘要(中文)
在大数据时代,大规模、多源、多模态数据集日益普及,为预测建模和科学发现提供了前所未有的机会。然而,这些数据集通常表现出复杂的异构性,例如协变量偏移、后验漂移和分块缺失,这会降低现有监督学习算法的预测性能。为了同时应对这些挑战,我们提出了一种新的表征检索(R2)框架,该框架将表征学习模块字典(representer dictionary)与数据源特定的稀疏诱导机器学习模型(learners)集成在一起。在R2框架下,我们为每个representer引入了integrativeness的概念,并提出了一种新的选择性集成惩罚(SIP),以明确鼓励更具integrative的representer来提高预测性能。从理论上讲,我们证明了R2框架的超额风险界限由representer的integrativeness决定,并且SIP有效地改善了超额风险。大量的模拟研究验证了R2框架的优越性能和SIP的效果。我们进一步将我们的方法应用于两个真实世界的数据集,以证实其经验上的成功。
🔬 方法详解
问题定义:论文旨在解决大规模、多源、多模态数据集中存在的复杂异构性问题,这些异构性包括协变量偏移、后验漂移和分块缺失。现有监督学习算法在处理这些异构数据时,预测性能会显著下降,无法有效利用这些数据进行预测建模和科学发现。
核心思路:论文的核心思路是构建一个表征检索(R2)框架,该框架能够从一个表征学习模块字典中选择合适的表征,并将其与数据源特定的稀疏诱导机器学习模型集成。通过这种方式,R2框架能够自适应地处理不同数据源的异构性,并提高预测性能。框架的关键在于学习到具有高“integrativeness”的表征,即能够有效整合不同数据源信息的表征。
技术框架:R2框架主要包含两个核心组件:表征学习模块字典(representer dictionary)和数据源特定的学习器(learners)。框架的流程如下:首先,利用表征学习模块字典对不同数据源的数据进行表征学习,得到一系列表征。然后,针对每个数据源,训练一个稀疏诱导机器学习模型,该模型利用学习到的表征进行预测。最后,通过选择性集成惩罚(SIP)来选择具有高integrativeness的表征,并将它们集成到最终的预测模型中。
关键创新:论文最重要的技术创新点在于提出了“integrativeness”的概念,并设计了选择性集成惩罚(SIP)来显式地鼓励选择更具integrative的表征。与现有方法不同,R2框架能够自适应地学习和选择合适的表征,而不是依赖于预定义的或固定的表征。SIP的引入使得框架能够更加有效地利用不同数据源的信息,从而提高预测性能。
关键设计:选择性集成惩罚(SIP)是R2框架的关键设计之一。SIP的目标是惩罚那些对预测性能贡献较小的表征,从而鼓励选择更具integrative的表征。SIP的具体形式可以根据具体的应用场景进行调整,例如可以使用L1范数或L2范数来诱导稀疏性。此外,表征学习模块字典的设计也至关重要,需要根据数据的特点选择合适的表征学习方法,例如可以使用自编码器、生成对抗网络或预训练的深度学习模型。
🖼️ 关键图片
📊 实验亮点
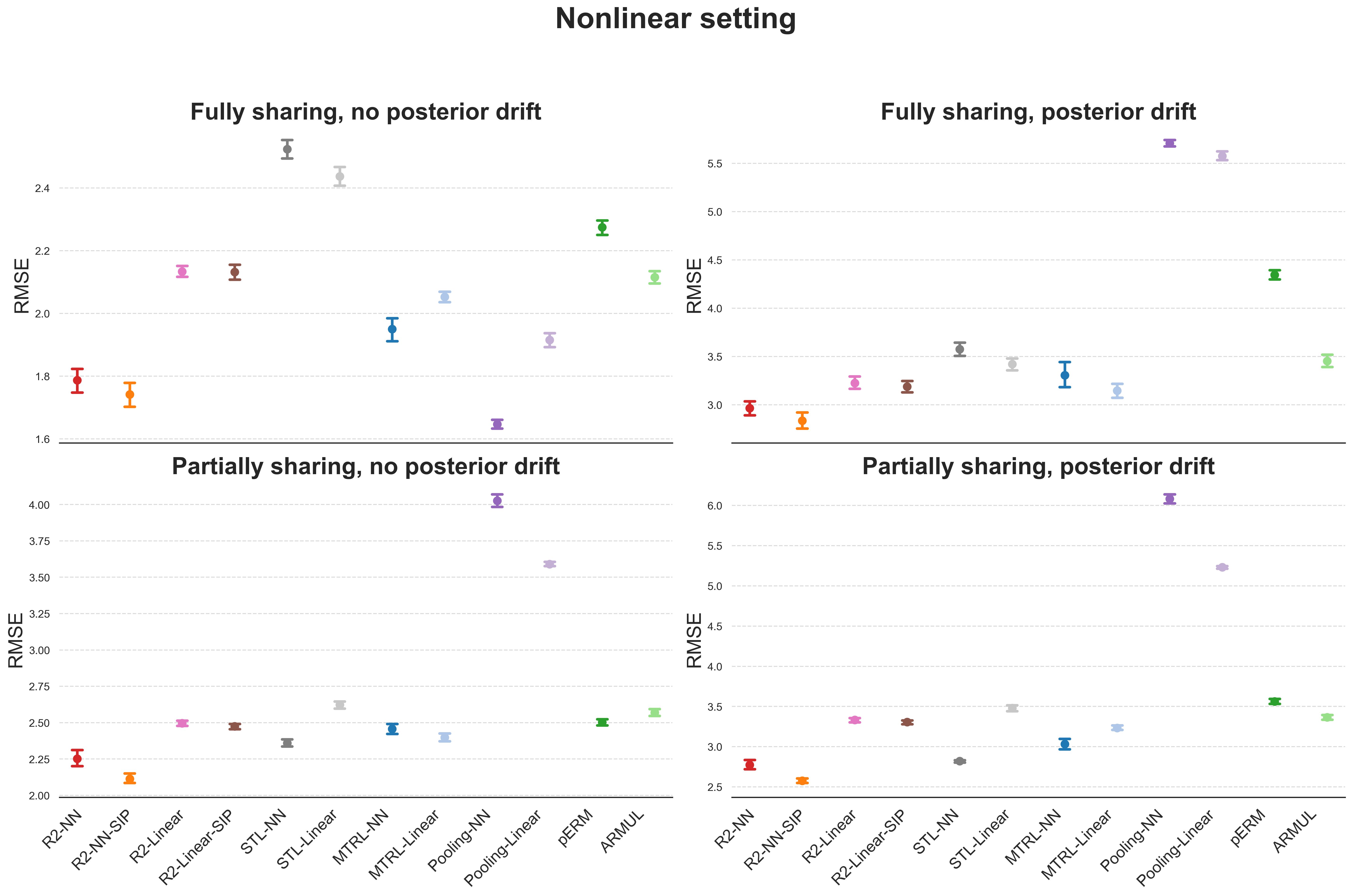
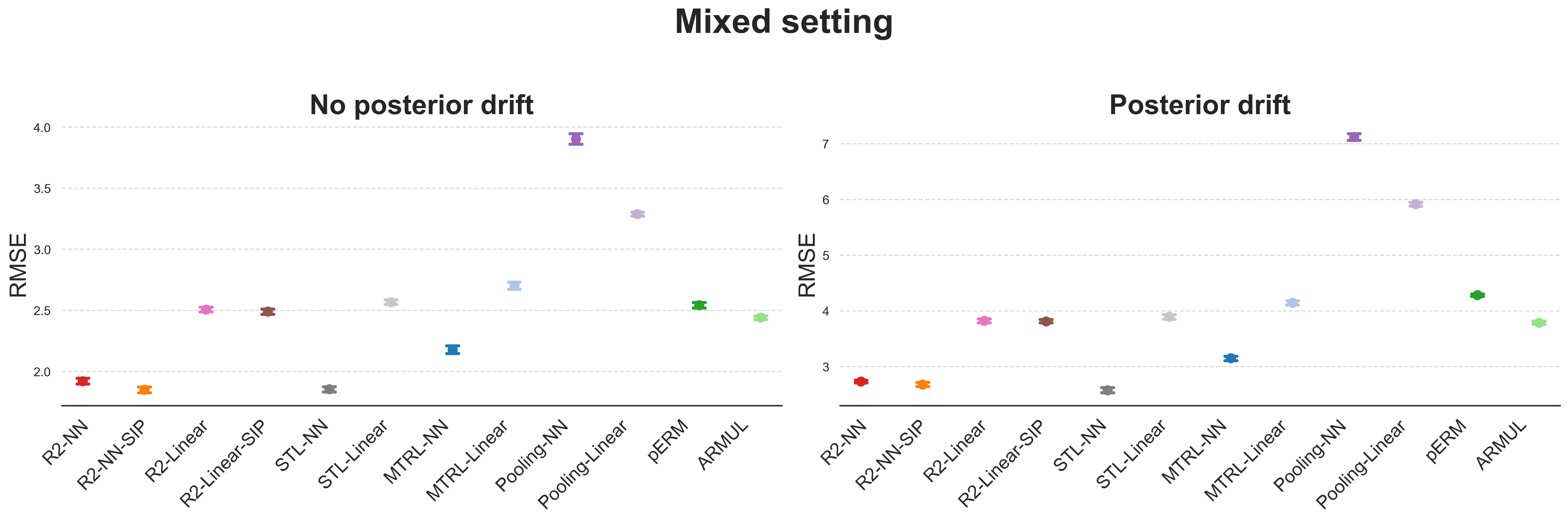
论文通过大量的模拟研究验证了R2框架的优越性能和SIP的效果。实验结果表明,R2框架在处理具有复杂异构性的数据集时,能够显著提高预测性能,优于现有的监督学习算法。此外,论文还将R2框架应用于两个真实世界的数据集,进一步证实了其经验上的成功。具体的性能提升数据未知。
🎯 应用场景
该研究成果可广泛应用于涉及异构数据集成的领域,例如医疗健康、金融风控、推荐系统等。在医疗健康领域,可以整合基因组数据、临床数据和影像数据,提高疾病预测的准确性。在金融风控领域,可以整合交易数据、社交数据和信用数据,提高欺诈检测的效率。未来,该方法可以进一步扩展到更多模态的数据集成,例如文本、图像和语音等。
📄 摘要(原文)
In the era of big data, large-scale, multi-source, multi-modality datasets are increasingly ubiquitous, offering unprecedented opportunities for predictive modeling and scientific discovery. However, these datasets often exhibit complex heterogeneity, such as covariates shift, posterior drift, and blockwise missingness, which worsen predictive performance of existing supervised learning algorithms. To address these challenges simultaneously, we propose a novel Representation Retrieval (R2) framework, which integrates a dictionary of representation learning modules (representer dictionary) with data source-specific sparsity-induced machine learning model (learners). Under the R2 framework, we introduce the notion of integrativeness for each representer, and propose a novel Selective Integration Penalty (SIP) to explicitly encourage more integrative representers to improve predictive performance. Theoretically, we show that the excess risk bound of the R2 framework is characterized by the integrativeness of representers, and SIP effectively improves the excess risk. Extensive simulation studies validate the superior performance of R2 framework and the effect of SIP. We further apply our method to two real-world datasets to confirm its empirical success.