Adaptive political surveys and GPT-4: Tackling the cold start problem with simulated user interactions
作者: Fynn Bachmann, Daan van der Weijden, Lucien Heitz, Cristina Sarasua, Abraham Bernstein
分类: cs.LG, cs.AI
发布日期: 2025-03-12
备注: 23 pages. Under review at PLOS One
💡 一句话要点
利用GPT-4模拟用户交互,解决自适应政治调查的冷启动问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自适应问卷调查 冷启动问题 大型语言模型 GPT-4 合成数据 政治调查 用户模拟
📋 核心要点
- 自适应问卷调查依赖大量用户交互数据进行训练,但在实际应用中,这些数据往往难以获取,导致冷启动问题。
- 本研究提出利用GPT-4生成模拟用户交互数据,用于预训练自适应问卷的统计模型,从而缓解冷启动问题。
- 实验表明,GPT-4能够准确模拟不同政治立场的用户回答,且使用合成数据预训练能显著提升问卷的预测精度和推荐准确率。
📝 摘要(中文)
自适应问卷调查能够根据参与者之前的回答动态选择下一个问题。数字化使得它成为政治学等领域传统调查的可行替代方案。然而,一个限制是它们依赖于数据来训练问题选择模型。通常,这种训练数据(即用户交互)是先验不可用的。为了解决这个问题,我们(i)测试大型语言模型(LLM)是否可以准确生成这种交互数据,以及(ii)探索这些合成数据是否可以用于预训练自适应政治调查的统计模型。为了评估这种方法,我们以两种方式利用来自瑞士投票建议应用(VAA)Smartvote的现有数据:首先,我们将LLM生成的合成数据的分布与真实分布进行比较,以评估其相似性。其次,我们将随机初始化的自适应问卷与预训练合成数据的问卷的性能进行比较,以评估它们用于训练的适用性。我们将这些结果与具有完美先验知识的“oracle”问卷进行基准测试。我们发现,现成的LLM(GPT-4)可以从不同瑞士政党的角度准确生成对Smartvote问卷的回答。此外,我们证明了使用合成数据初始化统计模型可以(i)显著减少预测用户响应的误差,以及(ii)提高VAA的候选人推荐准确性。我们的工作强调了LLM在创建训练数据以改进LLM相关领域(如政治调查)中自适应问卷的数据收集过程方面的巨大潜力。
🔬 方法详解
问题定义:自适应政治调查依赖大量真实用户交互数据来训练模型,以实现精准的问题推荐。然而,在实际应用初期,往往缺乏足够的真实数据,导致模型性能不佳,即“冷启动”问题。现有方法难以有效解决这一问题,限制了自适应问卷调查的应用范围。
核心思路:本研究的核心思路是利用大型语言模型(LLM),特别是GPT-4,来生成高质量的合成用户交互数据。这些合成数据可以作为预训练数据,用于初始化自适应问卷调查的统计模型,从而在缺乏真实数据的情况下,提升模型的初始性能,缓解冷启动问题。这样设计的目的是利用LLM强大的生成能力,弥补真实数据不足的缺陷。
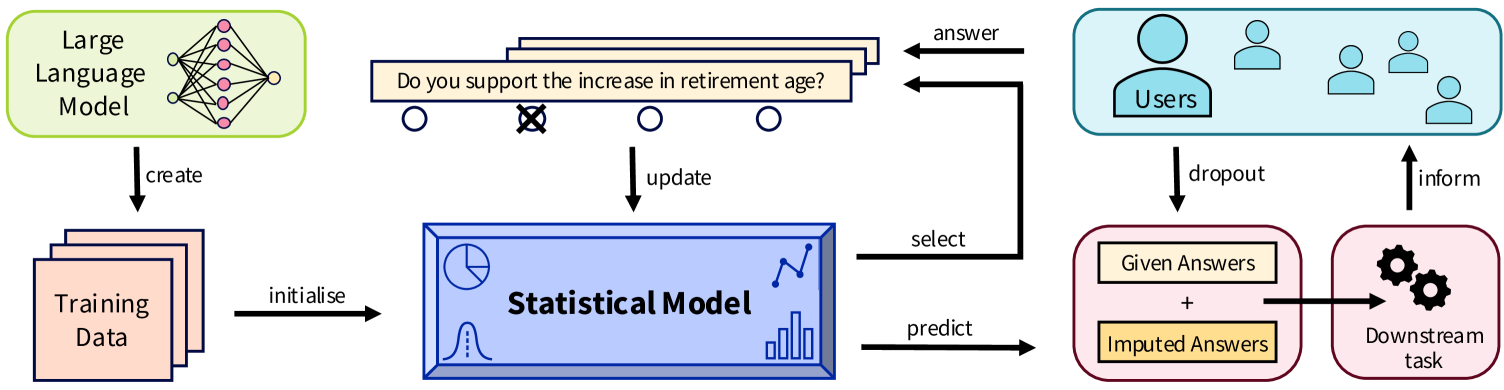
技术框架:整体框架包括以下几个主要阶段:1) 使用GPT-4生成模拟用户对政治问卷的回答,模拟不同政治立场的用户;2) 使用生成的合成数据预训练自适应问卷调查的统计模型;3) 使用真实用户数据对预训练模型进行微调;4) 评估预训练模型在真实数据上的性能,包括预测用户回答的准确性和候选人推荐的准确性。
关键创新:本研究的关键创新在于将大型语言模型应用于生成自适应问卷调查的训练数据。与传统的数据增强方法不同,本研究利用LLM的语义理解和生成能力,生成更具语义一致性和多样性的合成数据,从而更有效地提升模型的泛化能力。这是首次尝试利用LLM解决自适应问卷调查的冷启动问题。
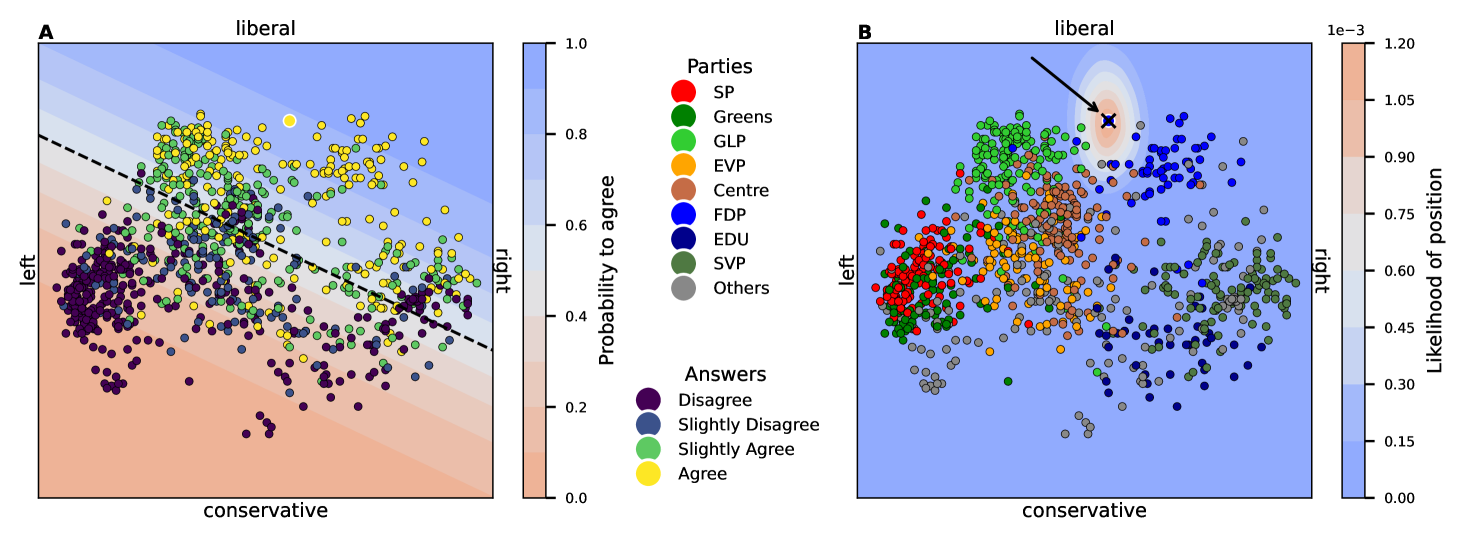
关键设计:研究中,GPT-4被用于模拟不同瑞士政党的选民对Smartvote问卷的回答。研究人员设计了合适的prompt,引导GPT-4生成符合特定政治立场的回答。统计模型采用常见的自适应问卷调查模型,例如基于项目反应理论(IRT)的模型。评估指标包括预测用户回答的均方误差(MSE)和候选人推荐的准确率。
🖼️ 关键图片
📊 实验亮点
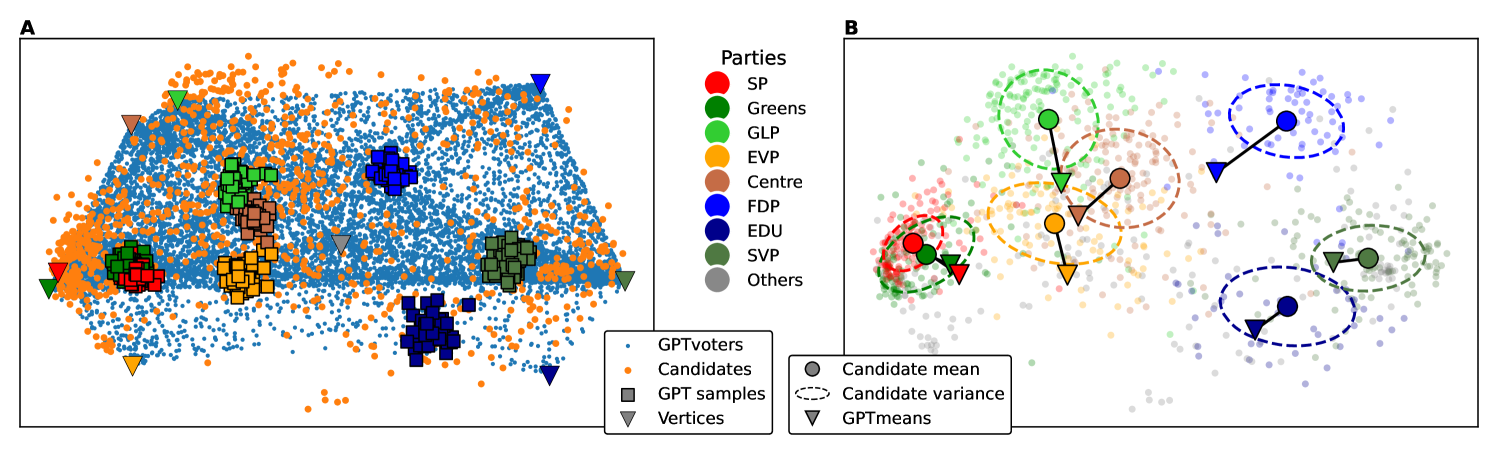
实验结果表明,GPT-4能够准确生成符合不同瑞士政党立场的问卷回答。使用合成数据预训练的自适应问卷模型,在预测用户回答的均方误差(MSE)方面,相比随机初始化模型显著降低,并且候选人推荐的准确率也得到了提升。这证明了利用LLM生成合成数据预训练自适应问卷模型的有效性。
🎯 应用场景
该研究成果可广泛应用于各类自适应问卷调查领域,例如政治倾向分析、产品偏好调查、个性化教育评估等。通过利用LLM生成合成数据,可以有效降低数据收集成本,加速模型训练,并提升用户体验。未来,该方法有望推广到其他数据稀缺的机器学习任务中,例如罕见疾病诊断、小样本学习等。
📄 摘要(原文)
Adaptive questionnaires dynamically select the next question for a survey participant based on their previous answers. Due to digitalisation, they have become a viable alternative to traditional surveys in application areas such as political science. One limitation, however, is their dependency on data to train the model for question selection. Often, such training data (i.e., user interactions) are unavailable a priori. To address this problem, we (i) test whether Large Language Models (LLM) can accurately generate such interaction data and (ii) explore if these synthetic data can be used to pre-train the statistical model of an adaptive political survey. To evaluate this approach, we utilise existing data from the Swiss Voting Advice Application (VAA) Smartvote in two ways: First, we compare the distribution of LLM-generated synthetic data to the real distribution to assess its similarity. Second, we compare the performance of an adaptive questionnaire that is randomly initialised with one pre-trained on synthetic data to assess their suitability for training. We benchmark these results against an "oracle" questionnaire with perfect prior knowledge. We find that an off-the-shelf LLM (GPT-4) accurately generates answers to the Smartvote questionnaire from the perspective of different Swiss parties. Furthermore, we demonstrate that initialising the statistical model with synthetic data can (i) significantly reduce the error in predicting user responses and (ii) increase the candidate recommendation accuracy of the VAA. Our work emphasises the considerable potential of LLMs to create training data to improve the data collection process in adaptive questionnaires in LLM-affine areas such as political surveys.