Probing Latent Subspaces in LLM for AI Security: Identifying and Manipulating Adversarial States
作者: Xin Wei Chia, Swee Liang Wong, Jonathan Pan
分类: cs.LG, cs.AI, cs.CR
发布日期: 2025-03-12 (更新: 2025-07-04)
备注: 4 figures
💡 一句话要点
利用LLM隐空间探测AI安全:识别并操纵对抗状态
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 AI安全 对抗攻击 提示注入 隐空间分析
📋 核心要点
- 大型语言模型容易受到提示注入攻击,攻击者可以通过精心设计的提示绕过安全机制,生成有害内容。
- 该论文的核心思想是,通过分析LLM的隐空间,识别安全状态和越狱状态,并设计扰动向量实现状态转移。
- 实验结果表明,通过对安全状态的表示施加扰动,可以有效地将模型推向越狱状态,揭示了LLM安全性的脆弱性。
📝 摘要(中文)
大型语言模型(LLM)在各种任务中表现出卓越的能力,但仍然容易受到对抗性操纵,例如通过提示注入攻击进行越狱。这些攻击绕过安全机制以生成受限制或有害的内容。在本研究中,我们通过从LLM中提取隐藏激活来研究安全和越狱状态的潜在隐空间。受到神经科学中吸引子动力学的启发,我们假设LLM激活稳定在半稳定状态,这些状态可以被识别和扰动以诱导状态转换。使用降维技术,我们投影来自安全和越狱响应的激活,以揭示低维空间中的潜在隐空间。然后,我们推导出一个扰动向量,当应用于安全表示时,将模型推向越狱状态。我们的结果表明,这种因果干预导致一部分提示中具有统计学意义的越狱响应。接下来,我们探测这些扰动如何在模型的层中传播,测试诱导的状态变化是保持局部化还是在整个网络中级联。我们的发现表明,有针对性的扰动导致激活和模型响应的明显变化。我们的方法为潜在的主动防御铺平了道路,从传统的基于护栏的方法转变为先发制人的、模型无关的技术,从而在中和表示级别的对抗状态。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)容易受到对抗性攻击的问题,特别是通过提示注入实现的越狱攻击。现有的防御方法,如基于护栏的策略,通常依赖于检测已知的攻击模式,难以应对新型攻击。因此,需要一种更通用的、模型无关的防御方法,能够从根本上消除对抗状态。
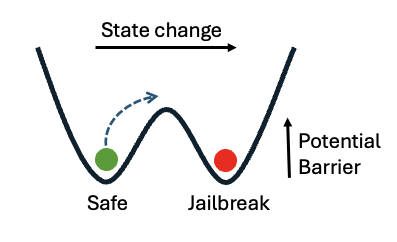
核心思路:论文的核心思路是,将LLM的激活状态视为动态系统中的吸引子。安全状态和越狱状态对应于不同的吸引子。通过分析LLM的隐空间,可以识别这些吸引子,并设计扰动向量,将模型从安全状态的吸引子推向越狱状态的吸引子。这种方法类似于神经科学中对大脑状态的操纵。
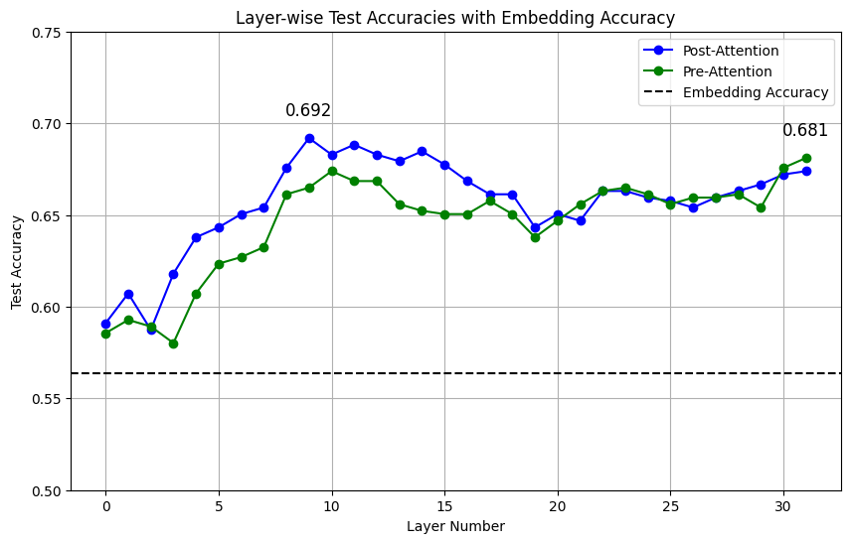
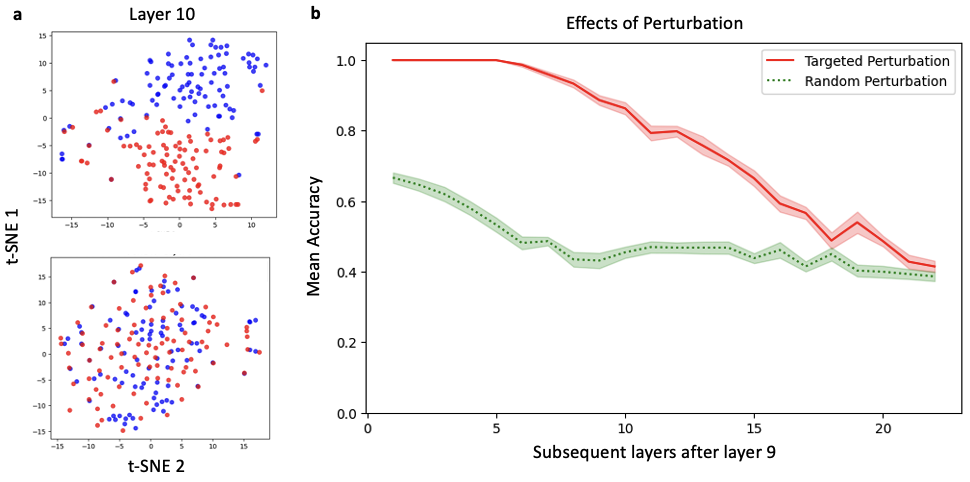
技术框架:该研究的技术框架主要包括以下几个步骤:1) 从LLM中提取安全和越狱响应的隐藏激活;2) 使用降维技术(如PCA或t-SNE)将高维激活投影到低维隐空间;3) 在低维空间中,识别安全状态和越狱状态的聚类;4) 计算从安全状态聚类到越狱状态聚类的扰动向量;5) 将扰动向量应用于安全状态的激活,观察模型是否产生越狱响应;6) 分析扰动在模型层间的传播情况。
关键创新:该论文的关键创新在于,将神经科学中的吸引子动力学概念引入到LLM的安全性研究中。通过分析LLM的隐空间,可以更深入地理解对抗攻击的本质,并设计出更有效的防御方法。此外,该方法是模型无关的,可以应用于不同的LLM。
关键设计:论文的关键设计包括:1) 如何选择合适的降维技术,以便在低维空间中清晰地呈现安全状态和越狱状态的聚类;2) 如何定义和计算扰动向量,使其能够有效地将模型从安全状态推向越狱状态;3) 如何评估扰动的效果,例如,通过统计越狱响应的比例;4) 如何分析扰动在模型层间的传播情况,以了解对抗攻击的影响范围。
🖼️ 关键图片
📊 实验亮点
实验结果表明,通过对安全状态的表示施加扰动,可以显著增加LLM产生越狱响应的概率。具体而言,在特定提示下,施加扰动后,越狱响应的比例显著提高,表明该方法能够有效地操纵LLM的状态。此外,研究还发现,扰动在模型层间的传播具有一定的模式,这为进一步理解对抗攻击的机理提供了线索。
🎯 应用场景
该研究成果可应用于提升大型语言模型的安全性,开发主动防御机制,预防提示注入攻击。通过理解和操纵LLM的隐空间,可以设计出更鲁棒的模型,减少有害内容的生成。此外,该方法还可以用于评估不同LLM的安全性,为模型选择和部署提供参考。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks, yet they remain vulnerable to adversarial manipulations such as jailbreaking via prompt injection attacks. These attacks bypass safety mechanisms to generate restricted or harmful content. In this study, we investigated the underlying latent subspaces of safe and jailbroken states by extracting hidden activations from a LLM. Inspired by attractor dynamics in neuroscience, we hypothesized that LLM activations settle into semi stable states that can be identified and perturbed to induce state transitions. Using dimensionality reduction techniques, we projected activations from safe and jailbroken responses to reveal latent subspaces in lower dimensional spaces. We then derived a perturbation vector that when applied to safe representations, shifted the model towards a jailbreak state. Our results demonstrate that this causal intervention results in statistically significant jailbreak responses in a subset of prompts. Next, we probed how these perturbations propagate through the model's layers, testing whether the induced state change remains localized or cascades throughout the network. Our findings indicate that targeted perturbations induced distinct shifts in activations and model responses. Our approach paves the way for potential proactive defenses, shifting from traditional guardrail based methods to preemptive, model agnostic techniques that neutralize adversarial states at the representation level.