Implicit Contrastive Representation Learning with Guided Stop-gradient
作者: Byeongchan Lee, Sehyun Lee
分类: cs.LG, cs.AI, cs.CV
发布日期: 2025-03-12
备注: Neurips 2023
期刊: Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023
🔗 代码/项目: GITHUB
💡 一句话要点
提出引导式停止梯度方法,提升自监督对比学习的稳定性和性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 自监督学习 对比学习 表征学习 Siamese网络 停止梯度 非对称网络 引导式梯度 无负样本学习
📋 核心要点
- 自监督学习中的Siamese网络易于坍塌,对比学习虽能缓解,但依赖负样本,对负样本数量敏感。
- 论文提出引导式停止梯度方法,利用非对称网络架构,隐式地融入对比学习的思想,避免负样本依赖。
- 实验表明,该方法能稳定训练,提升SimSiam和BYOL等算法的性能,且对小批量数据友好。
📝 摘要(中文)
在自监督表征学习中,Siamese网络是一种通过拉近正样本对的表征来学习变换不变性的自然架构。但它容易坍塌到退化的解。为了解决这个问题,对比学习使用对比损失,通过推开负样本对的表征来防止坍塌。但是,已知带有负采样的算法对于负样本数量的减少并不鲁棒。因此,另一方面,存在不使用负样本对的算法。许多仅使用正样本的算法采用由源编码器和目标编码器组成的不对称网络架构,作为应对坍塌的关键因素。通过利用不对称架构,我们引入了一种隐式地结合对比学习思想的方法。作为其实现,我们提出了一种新颖的引导式停止梯度方法。我们将我们的方法应用于基准算法SimSiam和BYOL,并表明我们的方法稳定了训练并提高了性能。我们还表明,使用我们方法的算法在小批量大小下也能很好地工作,即使没有预测器也不会崩溃。代码可在https://github.com/bych-lee/gsg获得。
🔬 方法详解
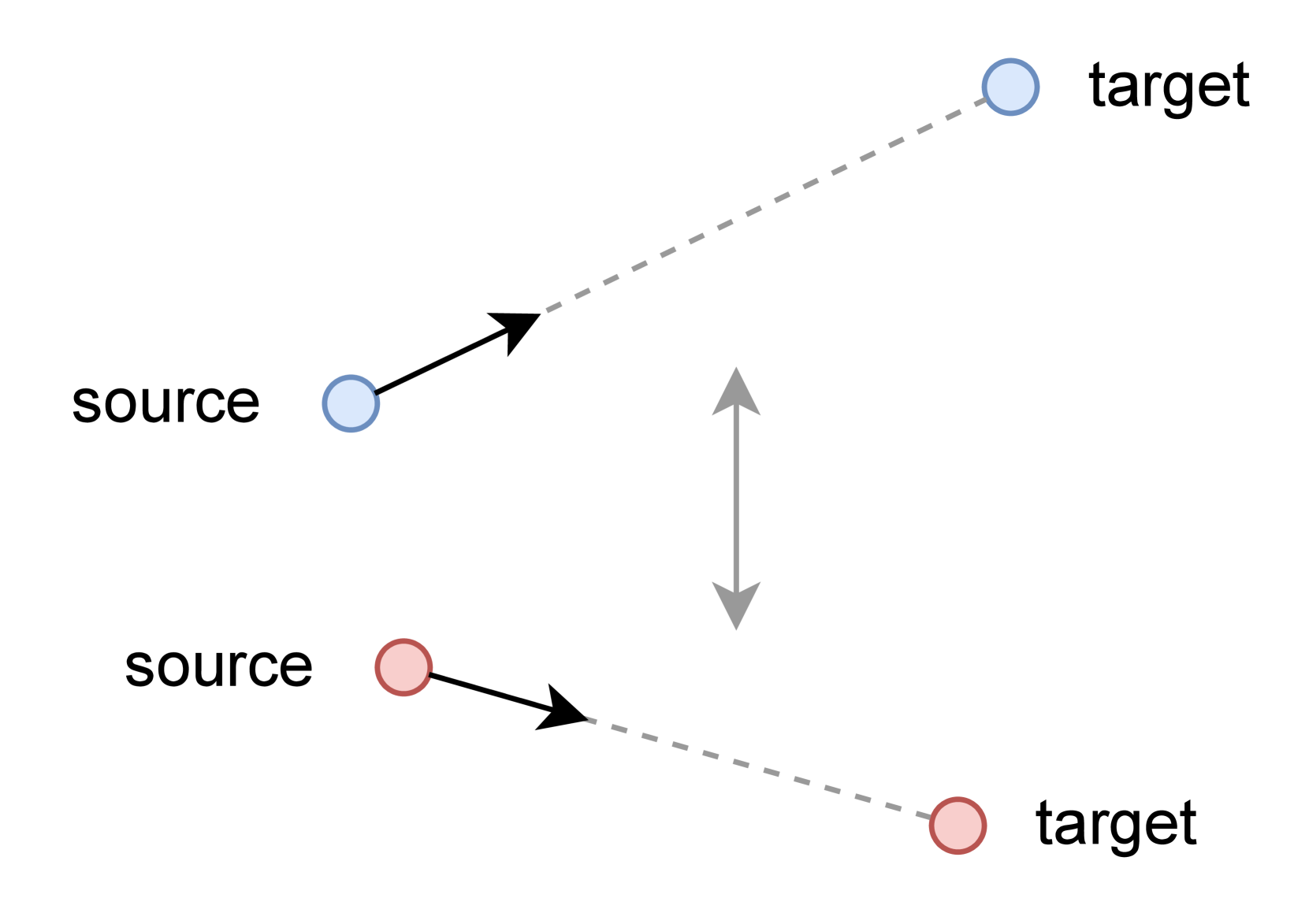
问题定义:自监督学习中的对比学习方法,特别是基于Siamese网络的架构,容易出现表征坍塌问题,即所有样本都学习到相同的表征。虽然对比损失通过引入负样本来避免坍塌,但负采样方法对负样本的数量非常敏感,当负样本数量不足时,性能会显著下降。
核心思路:论文的核心思路是利用非对称的网络结构(如BYOL和SimSiam中使用的源编码器和目标编码器),并结合一种新颖的“引导式停止梯度”机制,来隐式地实现对比学习的效果,而无需显式地依赖负样本。通过巧妙地控制梯度流,使得网络在学习正样本对的同时,也能避免表征坍塌。
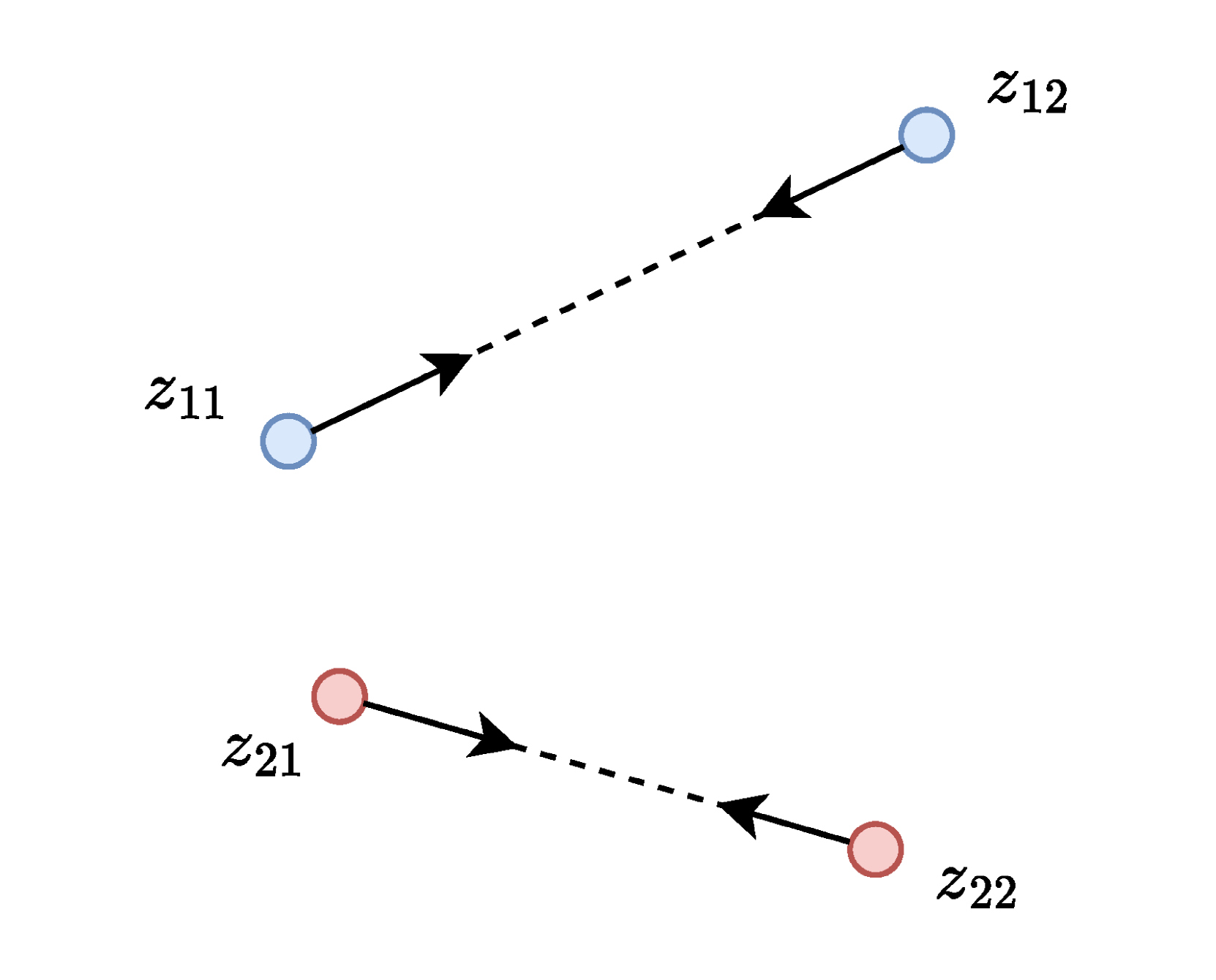
技术框架:整体框架基于非对称的Siamese网络,包含一个源编码器和一个目标编码器。源编码器的输出经过一个预测器(predictor,可选),然后与目标编码器的输出进行比较。关键在于“引导式停止梯度”模块,它作用于源编码器和目标编码器之间的梯度传递过程中,有选择性地阻止某些梯度分量的传播。
关键创新:最重要的创新点在于“引导式停止梯度”(Guided Stop-gradient, GSG)机制。传统的stop-gradient操作会完全阻止梯度传播,而GSG允许部分梯度信息通过,从而在避免表征坍塌的同时,保持模型的学习能力。GSG的具体实现方式未知,但其核心思想是根据某种策略(guided)来选择性地停止梯度。
关键设计:论文的关键设计在于如何实现和应用“引导式停止梯度”。具体的实现细节(例如,如何选择性地停止梯度,使用什么样的引导策略)在摘要中没有详细描述,需要参考论文全文。此外,预测器的存在与否,以及批量大小的选择,也是影响算法性能的关键因素。
🖼️ 关键图片

📊 实验亮点
论文将提出的引导式停止梯度方法应用于SimSiam和BYOL等基准算法,实验结果表明,该方法能够稳定训练过程,并显著提升性能。此外,该方法在小批量大小下也能有效工作,并且即使没有预测器也不会发生模型坍塌,这表明该方法具有很强的鲁棒性和适应性。
🎯 应用场景
该研究成果可广泛应用于计算机视觉领域的自监督表征学习任务,例如图像分类、目标检测、图像分割等。其无需负样本的特性,使得该方法在计算资源受限或负样本难以获取的场景下具有优势。该方法能够提升模型的泛化能力和鲁棒性,具有重要的实际应用价值。
📄 摘要(原文)
In self-supervised representation learning, Siamese networks are a natural architecture for learning transformation-invariance by bringing representations of positive pairs closer together. But it is prone to collapse into a degenerate solution. To address the issue, in contrastive learning, a contrastive loss is used to prevent collapse by moving representations of negative pairs away from each other. But it is known that algorithms with negative sampling are not robust to a reduction in the number of negative samples. So, on the other hand, there are algorithms that do not use negative pairs. Many positive-only algorithms adopt asymmetric network architecture consisting of source and target encoders as a key factor in coping with collapse. By exploiting the asymmetric architecture, we introduce a methodology to implicitly incorporate the idea of contrastive learning. As its implementation, we present a novel method guided stop-gradient. We apply our method to benchmark algorithms SimSiam and BYOL and show that our method stabilizes training and boosts performance. We also show that the algorithms with our method work well with small batch sizes and do not collapse even when there is no predictor. The code is available at https://github.com/bych-lee/gsg.