I Predict Therefore I Am: Is Next Token Prediction Enough to Learn Human-Interpretable Concepts from Data?
作者: Yuhang Liu, Dong Gong, Yichao Cai, Erdun Gao, Zhen Zhang, Biwei Huang, Mingming Gong, Anton van den Hengel, Javen Qinfeng Shi
分类: cs.LG, cs.CL
发布日期: 2025-03-12 (更新: 2025-05-12)
💡 一句话要点
提出基于隐变量生成模型的理论框架,揭示LLM学习人类可解释概念的内在机制。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可解释性 隐变量模型 next-token预测 稀疏自编码器
📋 核心要点
- 现有对LLM能力的解释存在争议,是真正智能还是简单的数据操作,缺乏理论支撑。
- 论文提出基于隐变量的生成模型,将LLM的学习过程建模为对人类可解释概念的后验概率估计。
- 实验验证了理论结果,并基于此提出了结构化稀疏自编码器,提升了概念提取的性能。
📝 摘要(中文)
大型语言模型(LLM)的卓越成就引发了关于其是否展现出某种形式智能的讨论,而非仅仅是对海量数据进行简单操作的能力。为了区分这两种解释,我们引入了一种新的生成模型,该模型基于人类可解释的概念(表示为潜在离散变量)生成tokens。在温和条件下,即使从潜在空间到观察空间的映射不可逆,我们也建立了一个可辨识性结果,即LLM通过next-token预测学习到的表示可以近似地建模为给定输入上下文的这些潜在离散概念的后验概率的对数,直到一个可逆线性变换。这一理论发现不仅提供了LLM捕获底层生成因素的证据,而且为理解线性表示假设提供了一个统一的视角。更进一步,我们的发现激发了一种可靠的稀疏自编码器评估方法,将监督概念提取器的性能视为上限。更进一步,它启发了一种结构变体,除了促进稀疏性之外,还强制执行潜在概念之间的依赖关系。在经验上,我们通过对模拟数据以及Pythia、Llama和DeepSeek模型系列的评估来验证我们的理论结果,并证明了我们的结构化稀疏自编码器的有效性。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的能力解释存在争议。一种观点认为LLM展现了某种形式的智能,而另一种观点则认为LLM仅仅是对海量数据进行简单操作。缺乏一个理论框架来解释LLM如何从数据中学习到人类可解释的概念,以及next-token预测是否足以让LLM捕获这些概念。
核心思路:论文的核心思路是将LLM的学习过程建模为一个生成模型,该模型基于人类可解释的概念(表示为潜在离散变量)生成tokens。通过建立潜在空间到观察空间的映射关系,并证明在一定条件下这种映射是可辨识的,从而说明LLM通过next-token预测学习到的表示可以近似地建模为给定输入上下文的这些潜在离散概念的后验概率的对数。
技术框架:论文构建了一个包含潜在离散变量的生成模型。该模型首先从潜在空间中采样得到人类可解释的概念,然后根据这些概念生成tokens。LLM通过next-token预测来学习这个生成模型的参数,从而学习到潜在概念的表示。论文还提出了一种结构化稀疏自编码器,用于从LLM中提取这些潜在概念。
关键创新:论文的关键创新在于提出了一个基于隐变量的生成模型,并证明了LLM通过next-token预测可以学习到这些隐变量的表示。这一理论结果为理解LLM的能力提供了一个新的视角,并为评估和改进LLM的学习过程提供了新的方法。此外,结构化稀疏自编码器的设计也考虑了潜在概念之间的依赖关系,进一步提升了概念提取的性能。
关键设计:论文的关键设计包括:1) 潜在离散变量的表示方式;2) 从潜在空间到观察空间的映射函数;3) next-token预测的目标函数;4) 结构化稀疏自编码器的网络结构和损失函数,包括稀疏性约束和概念间依赖关系的建模。
🖼️ 关键图片

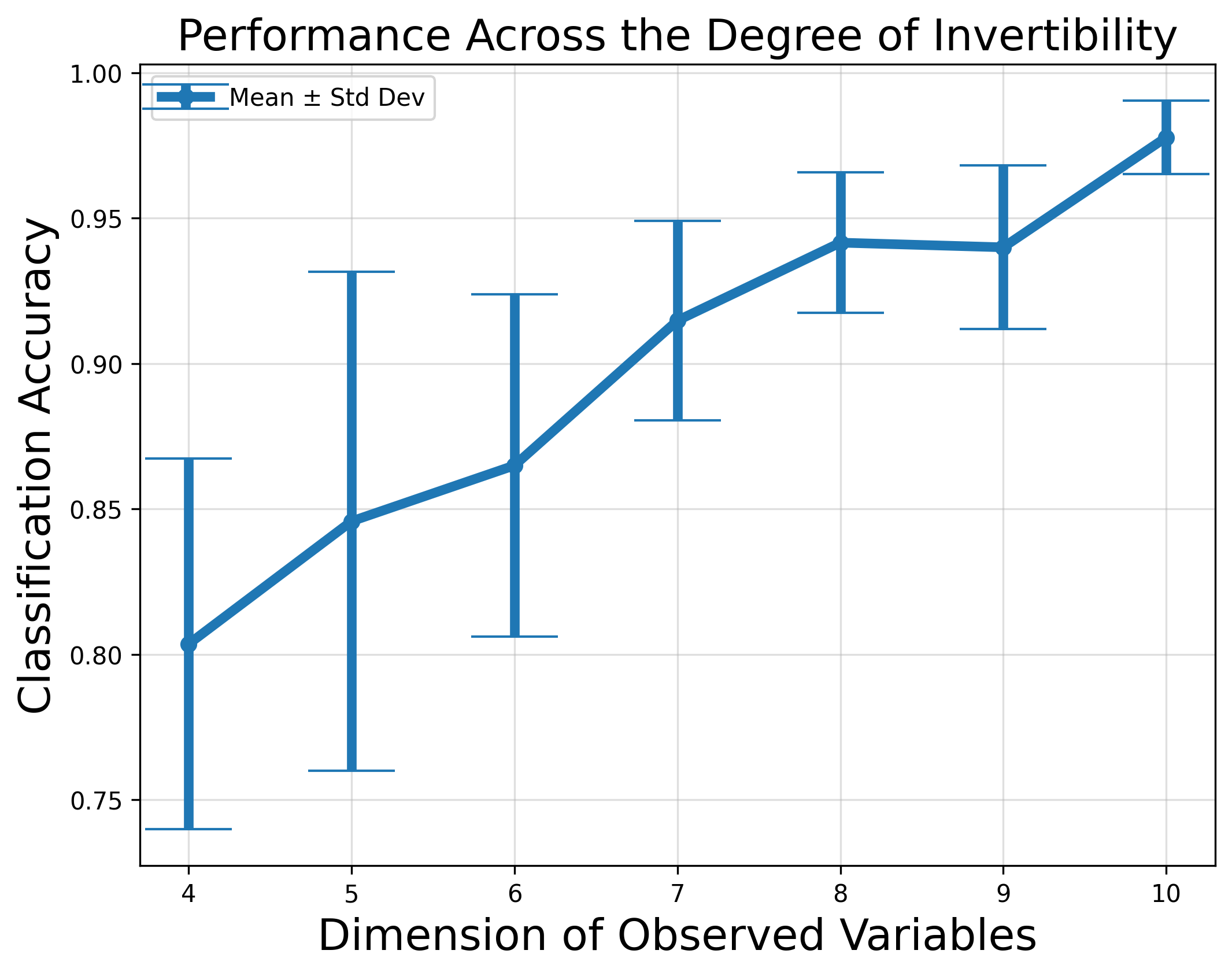

📊 实验亮点
论文通过在模拟数据以及Pythia、Llama和DeepSeek模型系列上的实验验证了理论结果。实验结果表明,LLM确实可以学习到人类可解释的概念,并且结构化稀疏自编码器可以有效地从LLM中提取这些概念。此外,结构化稀疏自编码器在概念提取任务上取得了优于传统稀疏自编码器的性能。
🎯 应用场景
该研究成果可应用于提升LLM的可解释性和可控性,例如,通过提取LLM学习到的潜在概念,可以更好地理解LLM的决策过程,并对其进行干预。此外,该研究还可以用于开发更高效的LLM训练方法,例如,通过显式地建模人类可解释的概念,可以减少LLM对海量数据的依赖。
📄 摘要(原文)
The remarkable achievements of large language models (LLMs) have led many to conclude that they exhibit a form of intelligence. This is as opposed to explanations of their capabilities based on their ability to perform relatively simple manipulations of vast volumes of data. To illuminate the distinction between these explanations, we introduce a novel generative model that generates tokens on the basis of human-interpretable concepts represented as latent discrete variables. Under mild conditions, even when the mapping from the latent space to the observed space is non-invertible, we establish an identifiability result, i.e., the representations learned by LLMs through next-token prediction can be approximately modeled as the logarithm of the posterior probabilities of these latent discrete concepts given input context, up to an invertible linear transformation. This theoretical finding not only provides evidence that LLMs capture underlying generative factors, but also provide a unified prospective for understanding of the linear representation hypothesis. Taking this a step further, our finding motivates a reliable evaluation of sparse autoencoders by treating the performance of supervised concept extractors as an upper bound. Pushing this idea even further, it inspires a structural variant that enforces dependence among latent concepts in addition to promoting sparsity. Empirically, we validate our theoretical results through evaluations on both simulation data and the Pythia, Llama, and DeepSeek model families, and demonstrate the effectiveness of our structured sparse autoencoder.