Interpreting the Repeated Token Phenomenon in Large Language Models
作者: Itay Yona, Ilia Shumailov, Jamie Hayes, Federico Barbero, Yossi Gandelsman
分类: cs.LG, cs.AI, cs.CL, cs.CR
发布日期: 2025-03-11
💡 一句话要点
揭示大语言模型重复Token现象:通过干预Attention Sinks提升模型可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 重复Token 注意力陷阱 神经回路 模型安全
📋 核心要点
- 大型语言模型在重复token时表现出的非预期行为,揭示了其潜在的脆弱性,可能被恶意利用。
- 论文通过分析“注意力陷阱”现象,揭示了重复token失败的神经回路机制,并提出了针对性的修复方案。
- 实验证明,该修复方案能够有效解决重复token问题,同时保持模型整体性能,提升了模型的可靠性。
📝 摘要(中文)
大型语言模型(LLMs)虽然能力强大,但在被提示重复单个词时,经常无法准确执行,反而输出无关文本。这种无法解释的失效模式构成了一种漏洞,甚至允许最终用户使模型偏离其预期行为。本文旨在解释这种现象的原因,并将其与“注意力陷阱(attention sinks)”的概念联系起来,这是一种对流畅性至关重要的LLM涌现行为,其中初始token获得不成比例的高注意力分数。我们的研究确定了负责注意力陷阱的神经回路,并展示了长重复如何扰乱该回路。我们将这一发现扩展到表现出类似回路中断的其他非重复序列。为了解决这个问题,我们提出了一种有针对性的补丁,可以有效地解决该问题,而不会对模型的整体性能产生负面影响。这项研究为LLM漏洞提供了一种机制解释,展示了解释性如何诊断和解决问题,并为更安全、更可靠的模型铺平了道路。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在被要求重复单个token时,经常无法准确重复,而是生成无关文本的问题。这种现象表明LLM存在一种未知的脆弱性,可能被用于对抗攻击或降低模型性能。现有方法缺乏对该现象的深入理解和有效的解决方案。
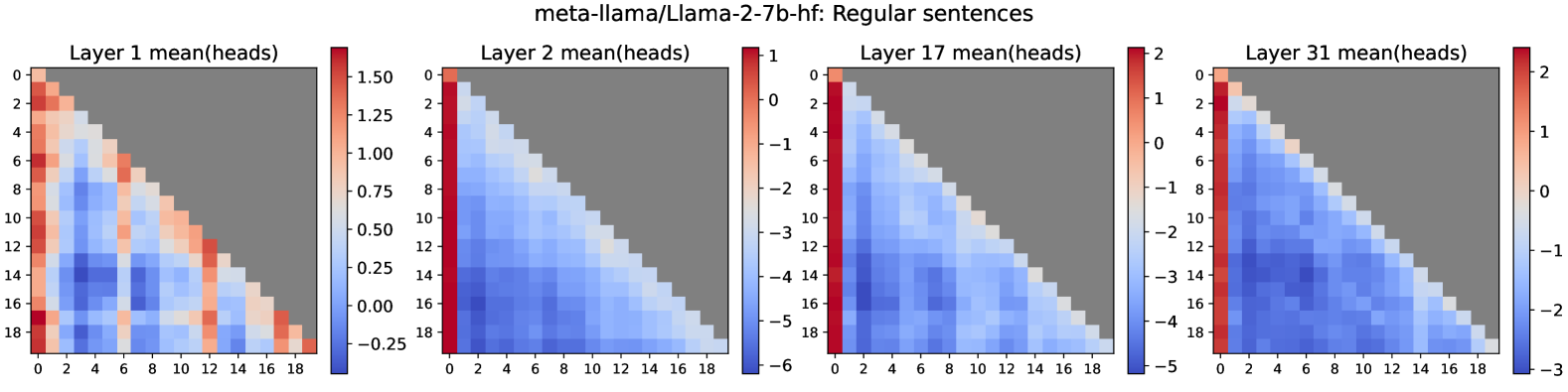
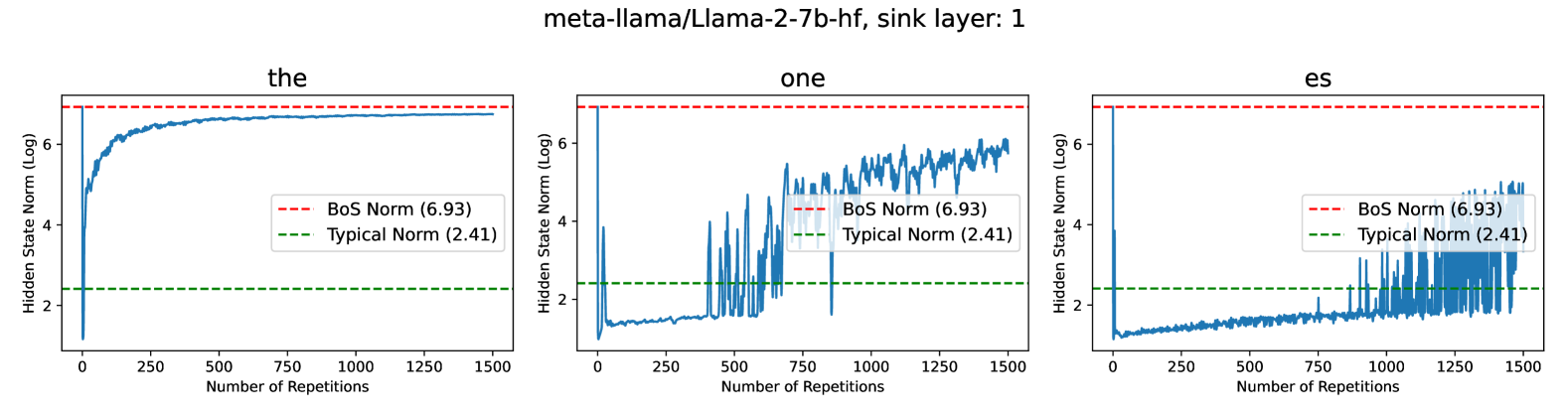
核心思路:论文的核心思路是将这种重复token失败的现象与“注意力陷阱(attention sinks)”联系起来。注意力陷阱是指LLM中初始token获得不成比例的高注意力分数,这对于模型的流畅性至关重要。论文认为,长重复序列会扰乱负责注意力陷阱的神经回路,导致模型无法正确重复token。
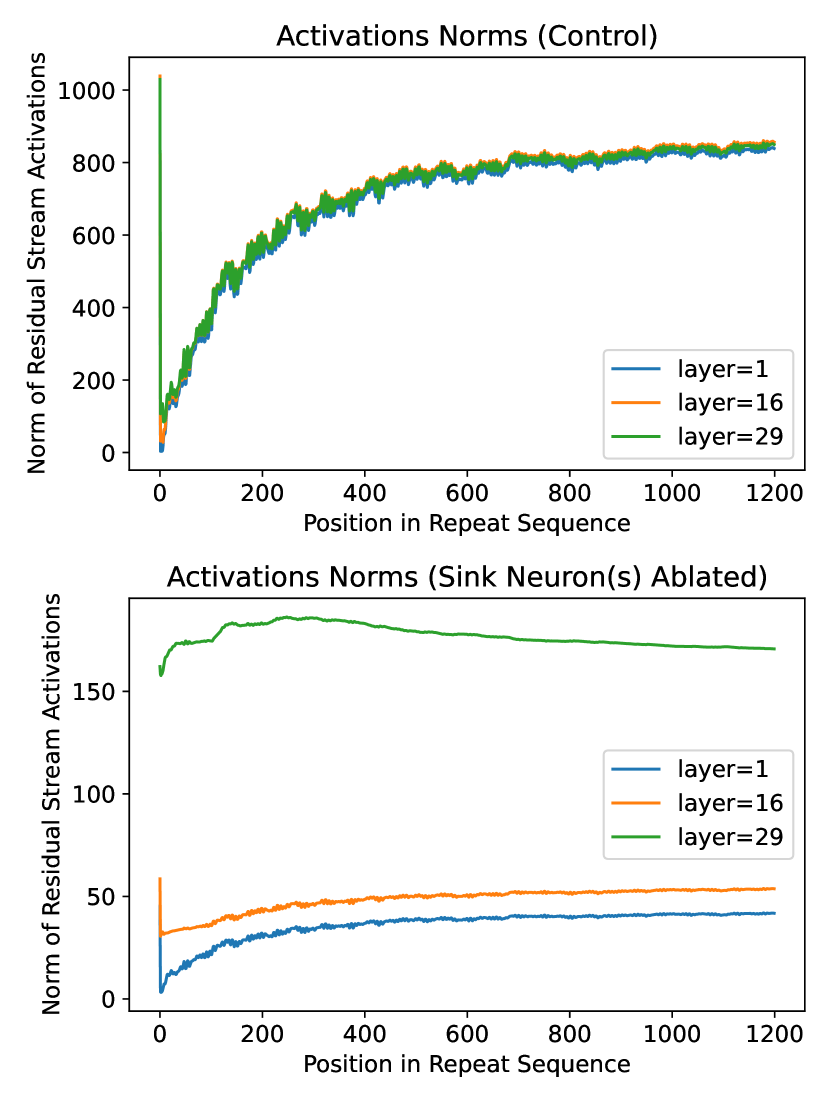
技术框架:论文首先通过实验观察和分析,确定了负责注意力陷阱的神经回路。然后,研究了长重复序列如何影响该回路的活动。接着,设计了一种有针对性的补丁,用于修复被扰乱的神经回路。最后,通过实验验证了该补丁的有效性,并评估了其对模型整体性能的影响。
关键创新:论文的关键创新在于:1) 将重复token失败现象与注意力陷阱联系起来,提出了新的解释框架;2) 确定了负责注意力陷阱的神经回路,为理解LLM内部机制提供了新的视角;3) 设计了一种有针对性的补丁,能够有效解决重复token问题,同时保持模型整体性能。
关键设计:论文提出的补丁的具体实现细节未知,摘要中只提到是“有针对性的补丁”,用于修复被扰乱的神经回路。具体的技术细节,例如如何识别和修复神经回路,以及补丁的具体参数设置等,需要在论文正文中查找。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了提出的补丁能够有效解决重复token问题,并且不会对模型的整体性能产生负面影响。具体的性能数据和对比基线未知,需要在论文正文中查找。但总体而言,该研究为解决LLM的脆弱性问题提供了一种可行的解决方案。
🎯 应用场景
该研究成果可应用于提升大型语言模型的安全性和可靠性,防止模型被恶意利用或产生意外行为。通过修复重复token问题,可以提高模型在各种任务中的性能,例如文本生成、对话系统等。此外,该研究提出的神经回路分析方法,为理解和改进LLM提供了新的思路,有助于开发更强大、更可控的AI系统。
📄 摘要(原文)
Large Language Models (LLMs), despite their impressive capabilities, often fail to accurately repeat a single word when prompted to, and instead output unrelated text. This unexplained failure mode represents a vulnerability, allowing even end-users to diverge models away from their intended behavior. We aim to explain the causes for this phenomenon and link it to the concept of ``attention sinks'', an emergent LLM behavior crucial for fluency, in which the initial token receives disproportionately high attention scores. Our investigation identifies the neural circuit responsible for attention sinks and shows how long repetitions disrupt this circuit. We extend this finding to other non-repeating sequences that exhibit similar circuit disruptions. To address this, we propose a targeted patch that effectively resolves the issue without negatively impacting the model's overall performance. This study provides a mechanistic explanation for an LLM vulnerability, demonstrating how interpretability can diagnose and address issues, and offering insights that pave the way for more secure and reliable models.