Robust Multi-Objective Controlled Decoding of Large Language Models
作者: Seongho Son, William Bankes, Sangwoong Yoon, Shyam Sundhar Ramesh, Xiaohang Tang, Ilija Bogunovic
分类: cs.LG, cs.AI
发布日期: 2025-03-11
备注: 24 pages, 9 figures
💡 一句话要点
提出鲁棒多目标控制解码以解决大语言模型对人类偏好的对齐问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 多目标解码 鲁棒优化 博弈论 智能对话系统
📋 核心要点
- 现有方法在对多个目标进行对齐时,往往依赖于预定义权重,导致目标之间的不平衡。
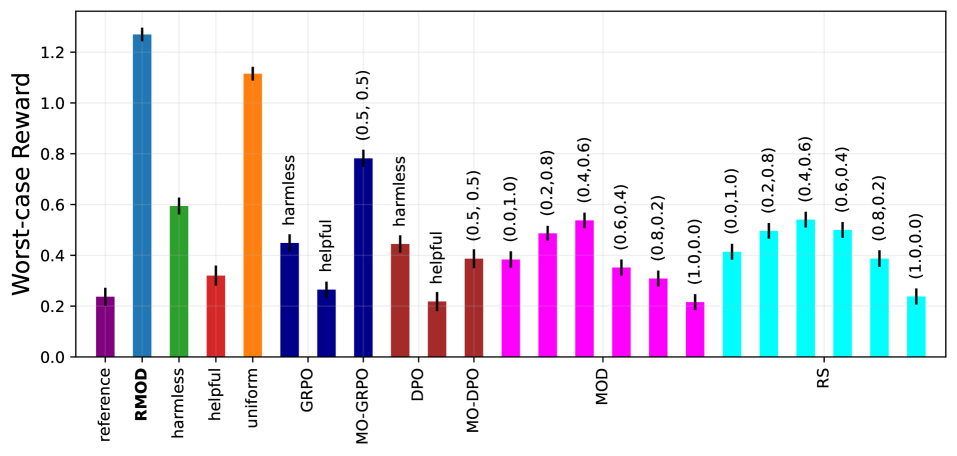
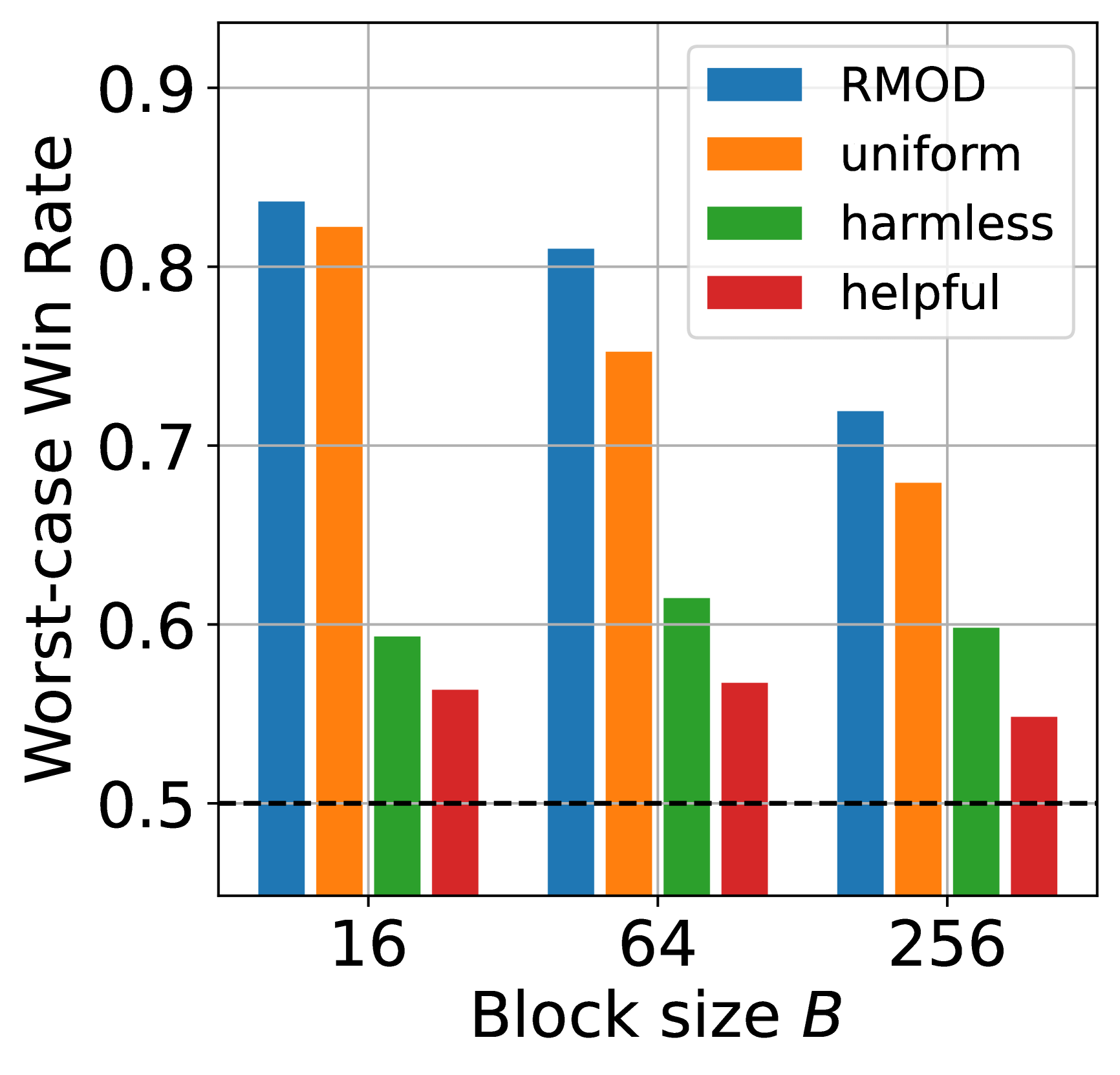
- 论文提出鲁棒多目标解码(RMOD),通过优化最坏情况奖励来实现目标对齐,避免了权重预定义的问题。
- 实验结果表明,RMOD在生成响应时能够公平地对齐多种目标,性能相比基线提升高达20%。
📝 摘要(中文)
在测试时对大语言模型(LLMs)进行人类偏好的对齐,提供了一种灵活的方式来生成符合多种目标的响应,而无需对LLMs进行广泛的再训练。现有方法通过优化相应的奖励函数来实现对多个目标的同时对齐,但往往依赖于预定义的权重或优化平均值,导致一个目标的牺牲换取另一个目标,结果不平衡。为了解决这个问题,我们提出了鲁棒多目标解码(RMOD),一种新颖的推理时算法,旨在优化最坏情况奖励。RMOD将鲁棒解码问题形式化为奖励权重与采样策略之间的最大最小双人博弈,求解纳什均衡。我们展示了该博弈简化为一个凸优化问题,以找到最坏情况权重,而最佳响应策略可以通过解析计算。我们还介绍了一种实用的RMOD变体,旨在与当代LLMs高效解码,相较于非鲁棒多目标解码(MOD)方法,计算开销最小。
🔬 方法详解
问题定义:本论文旨在解决现有多目标对齐方法在权重预定义和目标不平衡方面的不足。现有方法往往牺牲某一目标以优化其他目标,导致生成结果不理想。
核心思路:论文的核心思路是通过鲁棒多目标解码(RMOD)优化最坏情况奖励,形式化为奖励权重与采样策略之间的博弈,从而实现多目标的均衡对齐。
技术框架:RMOD的整体架构包括两个主要模块:一是通过凸优化求解最坏情况权重,二是通过解析方法计算最佳响应策略。该框架确保了在多目标对齐中能够有效处理最坏情况。
关键创新:RMOD的主要创新在于将鲁棒解码问题转化为最大最小博弈,求解纳什均衡,从而在多目标对齐中实现了更高的公平性和有效性。这一方法与传统的基于平均值的优化方法本质上不同。
关键设计:在设计中,RMOD采用了特定的损失函数来优化最坏情况奖励,并通过解析方法高效计算最佳响应策略,确保了在实际应用中的低计算开销。
🖼️ 关键图片

📊 实验亮点
实验结果显示,RMOD在生成响应时能够公平地对齐多种目标,相比基线方法提升高达20%。这一显著的性能提升表明RMOD在实际应用中的有效性和优越性。
🎯 应用场景
该研究的潜在应用领域包括智能对话系统、个性化推荐和自动内容生成等。通过实现多目标的公平对齐,RMOD能够提升用户体验,满足不同用户的需求,具有重要的实际价值和未来影响。
📄 摘要(原文)
Test-time alignment of Large Language Models (LLMs) to human preferences offers a flexible way to generate responses aligned to diverse objectives without extensive retraining of LLMs. Existing methods achieve alignment to multiple objectives simultaneously (e.g., instruction-following, helpfulness, conciseness) by optimizing their corresponding reward functions. However, they often rely on predefined weights or optimize for averages, sacrificing one objective for another and leading to unbalanced outcomes. To address this, we introduce Robust Multi-Objective Decoding (RMOD), a novel inference-time algorithm that optimizes for improving worst-case rewards. RMOD formalizes the robust decoding problem as a maximin two-player game between reward weights and the sampling policy, solving for the Nash equilibrium. We show that the game reduces to a convex optimization problem to find the worst-case weights, while the best response policy can be computed analytically. We also introduce a practical RMOD variant designed for efficient decoding with contemporary LLMs, incurring minimal computational overhead compared to non-robust Multi-Objective Decoding (MOD) methods. Our experimental results showcase the effectiveness of RMOD in generating responses equitably aligned with diverse objectives, outperforming baselines up to 20%.