SplitQuantV2: Enhancing Low-Bit Quantization of LLMs Without GPUs
作者: Jaewoo Song, Fangzhen Lin
分类: cs.LG, cs.AI
发布日期: 2025-03-07
💡 一句话要点
SplitQuantV2:无需GPU加速,提升LLM低比特量化精度
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型量化 低比特量化 模型压缩 边缘计算 无GPU加速
📋 核心要点
- 现有高级量化算法依赖GPU,框架受限,需校准数据,不适用于资源受限的边缘设备和多种框架。
- SplitQuantV2通过拆分线性层和卷积层,构建量化友好的模型结构,实现高效的低比特量化。
- 在Llama 3.2 1B模型上,SplitQuantV2使INT4量化精度提升11.76%p,媲美浮点模型,且仅需CPU。
📝 摘要(中文)
大语言模型(LLM)的量化对于将其部署在计算资源受限的设备上至关重要。虽然高级量化算法相比基本的线性量化提供了更好的性能,但它们通常需要高端图形处理器(GPU),并且常常局限于特定的深度神经网络(DNN)框架,还需要校准数据集。这种限制给在各种神经处理单元(NPU)和边缘AI设备上使用这些算法带来了挑战,因为这些设备具有不同的模型格式和框架。本文展示了SplitQuantV2,一种旨在增强LLM低比特线性量化的创新算法,可以达到与高级算法相当的结果。SplitQuantV2通过将线性层和卷积层拆分为功能等效的、量化友好的结构来预处理模型。该算法具有平台无关性、简洁性和高效性,无需GPU即可实现。我们在使用AI2的推理挑战(ARC)数据集的Llama 3.2 1B Instruct模型上的评估表明,SplitQuantV2将INT4量化模型的准确率提高了11.76%p,与原始浮点模型的性能相匹配。值得注意的是,SplitQuantV2仅用2分6秒即可使用Apple M4 CPU预处理1B模型并执行线性INT4量化。SplitQuantV2为LLM上的低比特量化提供了一种实用的解决方案,尤其是在由于硬件限制或框架不兼容而无法使用复杂的、计算密集型算法时。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)在资源受限设备上的低比特量化问题。现有高级量化算法通常需要GPU加速,并且依赖特定的深度学习框架和校准数据集,这限制了它们在边缘设备和各种NPU上的应用。因此,需要一种无需GPU、平台无关且高效的低比特量化方法。
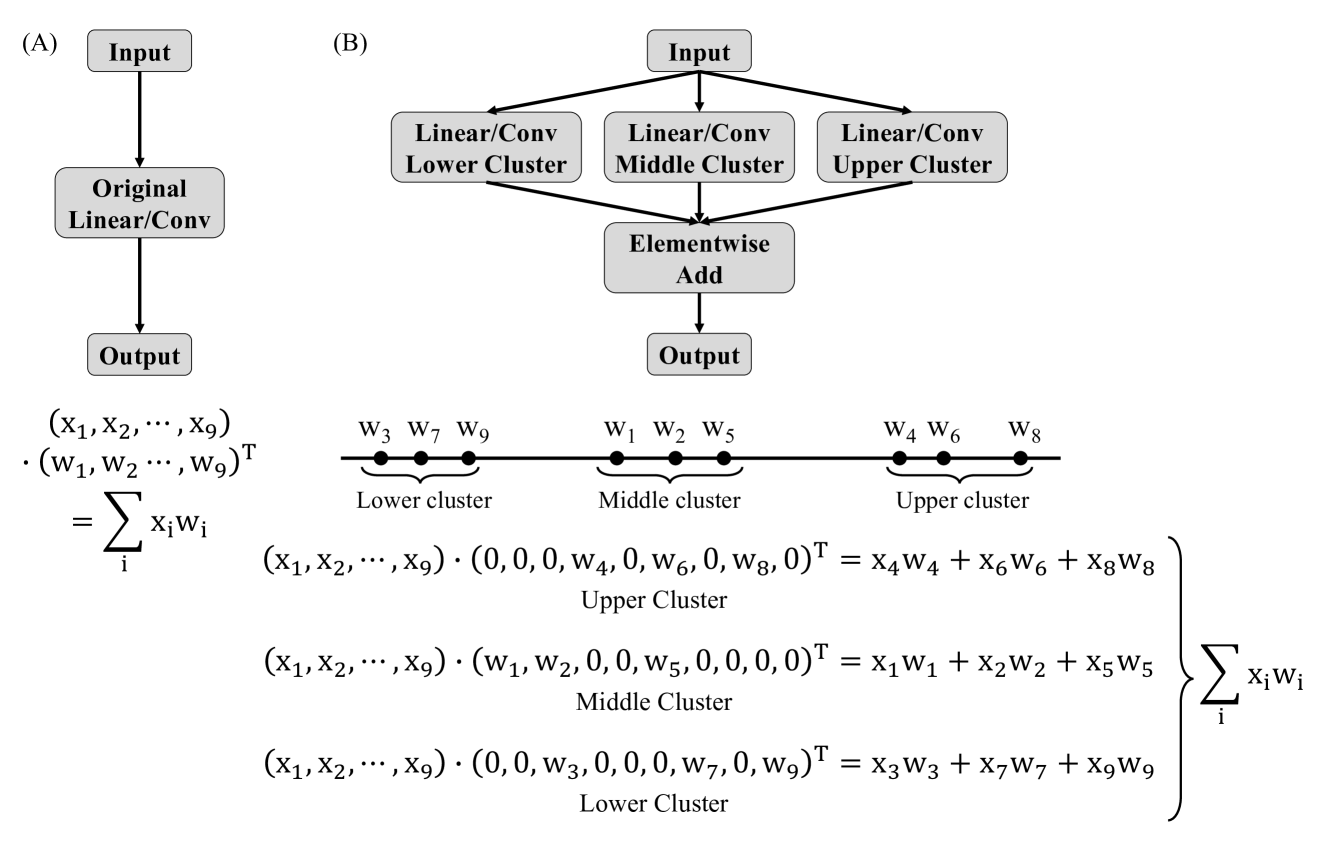
核心思路:SplitQuantV2的核心思路是通过预处理模型,将其中的线性层和卷积层分解为功能等效但更易于量化的结构。这种分解使得模型在低比特量化时能够更好地保持精度,从而避免了对GPU和大量校准数据的依赖。通过这种方式,SplitQuantV2旨在弥合线性量化和高级量化算法之间的性能差距。
技术框架:SplitQuantV2的整体流程包括模型预处理和线性量化两个主要阶段。在模型预处理阶段,算法将线性层和卷积层分解为量化友好的结构。然后,使用标准的线性量化方法对预处理后的模型进行量化。该框架的关键在于其预处理步骤,它使得后续的线性量化能够达到更高的精度。
关键创新:SplitQuantV2的关键创新在于其模型预处理方法,该方法通过分解线性层和卷积层,创建更适合低比特量化的模型结构。与传统的线性量化相比,SplitQuantV2的预处理步骤显著提高了量化模型的精度,使其能够与需要GPU加速和大量校准数据的高级量化算法相媲美。这种预处理方法的平台无关性是另一个重要的创新点。
关键设计:SplitQuantV2的关键设计在于如何将线性层和卷积层分解为量化友好的结构。具体的分解方法(例如,如何选择分解的维度和参数)以及如何保证分解后的结构与原始结构在功能上等效是该算法的关键技术细节。论文中可能包含关于这些分解方法的具体数学公式和实现细节,但摘要中未明确说明。
🖼️ 关键图片
📊 实验亮点
SplitQuantV2在Llama 3.2 1B Instruct模型上进行了评估,使用AI2的推理挑战(ARC)数据集。实验结果表明,SplitQuantV2将INT4量化模型的准确率提高了11.76%p,使其性能与原始浮点模型相匹配。更重要的是,整个过程仅使用Apple M4 CPU,耗时2分6秒,展示了其高效性和实用性。
🎯 应用场景
SplitQuantV2适用于资源受限的边缘设备和各种神经处理单元(NPU),例如移动设备、嵌入式系统和物联网设备。它能够帮助开发者在这些设备上部署大型语言模型,从而实现本地化的AI推理,提高响应速度和数据安全性。该技术还有助于降低AI应用的能耗和成本,促进AI技术的普及。
📄 摘要(原文)
The quantization of large language models (LLMs) is crucial for deploying them on devices with limited computational resources. While advanced quantization algorithms offer improved performance compared to the basic linear quantization, they typically require high-end graphics processing units (GPUs), are often restricted to specific deep neural network (DNN) frameworks, and require calibration datasets. This limitation poses challenges for using such algorithms on various neural processing units (NPUs) and edge AI devices, which have diverse model formats and frameworks. In this paper, we show SplitQuantV2, an innovative algorithm designed to enhance low-bit linear quantization of LLMs, can achieve results comparable to those of advanced algorithms. SplitQuantV2 preprocesses models by splitting linear and convolution layers into functionally equivalent, quantization-friendly structures. The algorithm's platform-agnostic, concise, and efficient nature allows for implementation without the need for GPUs. Our evaluation on the Llama 3.2 1B Instruct model using the AI2's Reasoning Challenge (ARC) dataset demonstrates that SplitQuantV2 improves the accuracy of the INT4 quantization model by 11.76%p, matching the performance of the original floating-point model. Remarkably, SplitQuantV2 took only 2 minutes 6 seconds to preprocess the 1B model and perform linear INT4 quantization using only an Apple M4 CPU. SplitQuantV2 provides a practical solution for low-bit quantization on LLMs, especially when complex, computation-intensive algorithms are inaccessible due to hardware limitations or framework incompatibilities.