Performance Comparisons of Reinforcement Learning Algorithms for Sequential Experimental Design
作者: Yasir Zubayr Barlas, Kizito Salako
分类: cs.LG, stat.ML
发布日期: 2025-03-07 (更新: 2025-08-18)
备注: 7 main pages, 19 pages of appendices - paper accepted at the 8th Workshop on Generalization in Planning at AAAI 2025
💡 一句话要点
研究强化学习算法在序贯实验设计中的性能,并探索泛化能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 序贯实验设计 强化学习 泛化能力 实验优化 智能体训练
📋 核心要点
- 现有序贯实验设计方法在面对实验底层统计属性变化时,泛化能力不足,难以保证性能。
- 利用强化学习训练智能体,使其能够自主探索设计空间,选择信息量最大的实验设计。
- 通过实验对比不同强化学习算法,发现特定算法(如dropout或集成方法)具有更好的泛化性能。
📝 摘要(中文)
序贯实验设计的最新进展旨在构建一种策略,能够高效地探索设计空间,并最大化期望的信息增益。虽然在实现可处理的实验设计策略方面已经有一些工作,但在获得能够很好地泛化的策略方面,研究相对较少,即能够在实验的底层统计属性发生变化时仍能保持良好的性能。最近,序贯实验促使人们使用强化学习,其中训练智能体来探索设计空间,以选择信息量最大的实验设计。然而,对于使用某些强化学习算法训练这些智能体的优缺点,仍然缺乏了解。本文研究了几种强化学习算法及其在序贯实验设计场景中产生能够做出信息量最大化设计决策的智能体的有效性。研究发现,智能体的性能受到用于训练的算法的影响,并且使用dropout或集成方法的特定算法,在经验上展示了有吸引力的泛化特性。
🔬 方法详解
问题定义:论文旨在解决序贯实验设计中,强化学习智能体在面对实验底层统计属性变化时泛化能力不足的问题。现有方法难以保证智能体在不同实验条件下都能做出最优的设计决策,导致实验效率降低。
核心思路:论文的核心思路是探索不同的强化学习算法,并评估它们在序贯实验设计中的泛化能力。通过对比不同算法的性能,找出能够更好地适应实验条件变化的算法,从而提高实验效率和信息增益。
技术框架:论文采用强化学习框架,将序贯实验设计过程建模为一个马尔可夫决策过程(MDP)。智能体通过与环境交互,学习选择最优的实验设计。环境根据智能体的选择,返回奖励信号,用于更新智能体的策略。整体流程包括:1. 定义实验设计空间和奖励函数;2. 选择合适的强化学习算法;3. 训练智能体;4. 评估智能体的性能和泛化能力。
关键创新:论文的关键创新在于系统性地比较了多种强化学习算法在序贯实验设计中的性能,并重点关注了算法的泛化能力。通过实验验证,发现使用dropout或集成方法的算法具有更好的泛化性能,这为未来的研究提供了重要的指导。与现有方法相比,该研究更注重算法的鲁棒性和适应性。
关键设计:论文中,强化学习算法的选择是关键设计之一。研究人员考察了多种算法,包括但不限于:Q-learning、Deep Q-Network (DQN)、Policy Gradient methods (例如,REINFORCE, Actor-Critic)。奖励函数的设计也至关重要,它需要能够准确反映实验设计的信息增益。此外,dropout和集成方法的使用,旨在提高模型的泛化能力,防止过拟合。
🖼️ 关键图片
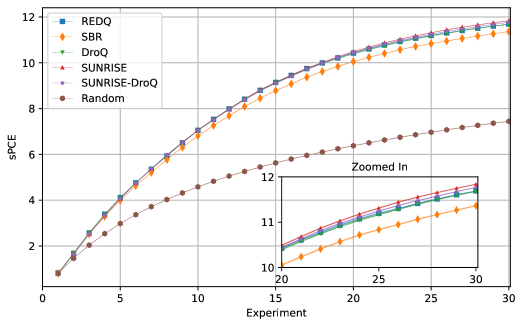
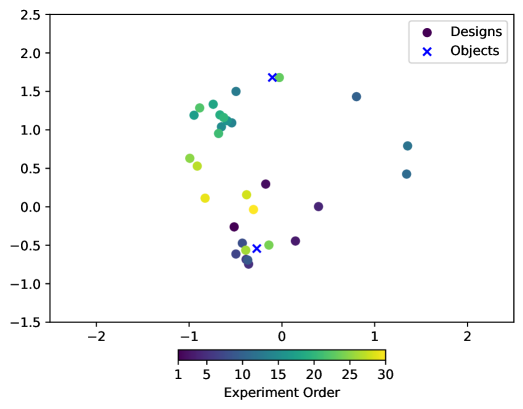
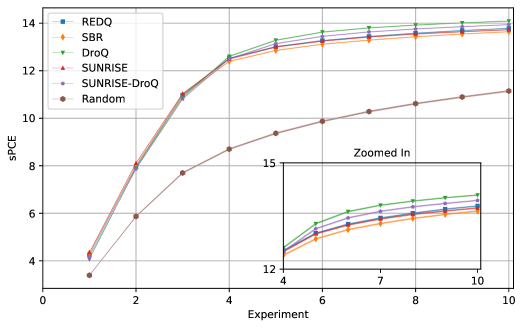
📊 实验亮点
实验结果表明,不同的强化学习算法对智能体的性能有显著影响。具体来说,使用dropout或集成方法的算法,在面对实验条件变化时,表现出更强的泛化能力。这些算法能够更好地适应新的实验环境,并保持较高的信息增益。这些发现为未来的序贯实验设计提供了重要的参考依据。
🎯 应用场景
该研究成果可应用于各种需要序贯实验设计的领域,例如新材料发现、药物研发、A/B测试等。通过选择合适的强化学习算法,可以显著提高实验效率,降低实验成本,加速科学发现和技术创新。未来,该研究可以进一步扩展到更复杂的实验设计场景,例如多目标优化、约束优化等。
📄 摘要(原文)
Recent developments in sequential experimental design look to construct a policy that can efficiently navigate the design space, in a way that maximises the expected information gain. Whilst there is work on achieving tractable policies for experimental design problems, there is significantly less work on obtaining policies that are able to generalise well - i.e. able to give good performance despite a change in the underlying statistical properties of the experiments. Conducting experiments sequentially has recently brought about the use of reinforcement learning, where an agent is trained to navigate the design space to select the most informative designs for experimentation. However, there is still a lack of understanding about the benefits and drawbacks of using certain reinforcement learning algorithms to train these agents. In our work, we investigate several reinforcement learning algorithms and their efficacy in producing agents that take maximally informative design decisions in sequential experimental design scenarios. We find that agent performance is impacted depending on the algorithm used for training, and that particular algorithms, using dropout or ensemble approaches, empirically showcase attractive generalisation properties.