A Multi-Fidelity Control Variate Approach for Policy Gradient Estimation
作者: Xinjie Liu, Cyrus Neary, Kushagra Gupta, Wesley A. Suttle, Christian Ellis, Ufuk Topcu, David Fridovich-Keil
分类: cs.LG, cs.AI, cs.RO
发布日期: 2025-03-07 (更新: 2025-10-02)
💡 一句话要点
提出多置信度控制变量策略梯度方法,提升强化学习在计算密集型任务中的效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 多置信度学习 控制变量 策略梯度 Sim-to-Real 机器人控制 方差减少
📋 核心要点
- 现有强化学习算法在计算密集型任务中数据需求大,限制了其应用。
- 提出多置信度策略梯度方法,利用低置信度数据作为控制变量,减少方差。
- 实验表明,该方法在机器人任务中提升了性能,并对动力学差距具有鲁棒性。
📝 摘要(中文)
许多强化学习(RL)算法需要大量数据,这使得它们在实际系统部署或使用计算成本高昂的高置信度仿真进行训练时变得不切实际。低置信度仿真器(如降阶模型、启发式奖励或生成世界模型)可以廉价地为RL训练提供有用的数据,即使它们对于零样本迁移来说过于粗糙。我们提出了多置信度策略梯度(MFPGs),这是一个RL框架,它将来自目标环境的少量数据与来自大量低置信度仿真数据的控制变量混合,从而为on-policy策略梯度构建一个无偏、方差减少的估计器。我们使用经典REINFORCE算法的多置信度变体来实例化该框架。我们表明,在标准假设下,MFPG估计器保证REINFORCE算法渐近收敛到目标环境中的局部最优策略,并且与仅使用高置信度数据进行训练相比,实现了更快的有限样本收敛速度。在实验中,我们在一套模拟机器人基准任务中评估了MFPG算法,这些任务具有有限的高置信度数据但丰富的非动力学、低置信度数据。在轻度到中度的动力学差距下,MFPG可靠地提高了相对于仅使用高置信度数据的基线的性能中位数,匹配了领先的多置信度基线的性能,尽管它很简单且调整开销最小。在较大的动力学差距下,MFPG在评估的多置信度方法中表现出最强的鲁棒性。一项额外的实验表明,即使在低置信度奖励错误指定的情况下,MFPG仍然有效。因此,MFPG不仅为高效的sim-to-real迁移提供了一种新的范例,而且还为管理策略性能和数据收集成本之间的权衡提供了一种原则性方法。
🔬 方法详解
问题定义:论文旨在解决强化学习算法在实际应用中,由于高置信度仿真或真实环境数据获取成本高昂,导致训练效率低下的问题。现有方法要么完全依赖高成本数据,要么直接使用低置信度数据进行训练,前者效率低,后者难以保证策略在真实环境中的性能。
核心思路:论文的核心思路是利用低置信度数据作为控制变量,来减少高置信度策略梯度估计的方差。通过将低置信度数据与少量高置信度数据相结合,构建一个无偏且方差更小的策略梯度估计器。这样可以在保证策略性能的同时,显著降低数据获取成本。
技术框架:MFPG框架主要包含以下几个阶段:1) 使用低置信度仿真器生成大量数据;2) 使用这些数据训练一个低置信度策略;3) 使用少量高置信度数据,并利用低置信度策略作为控制变量,估计高置信度策略梯度;4) 使用估计的策略梯度更新高置信度策略。整体流程旨在利用廉价的低置信度数据来加速高置信度策略的训练。
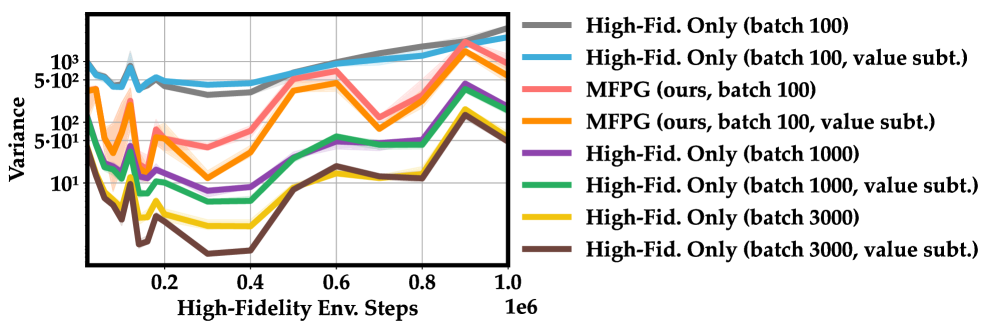
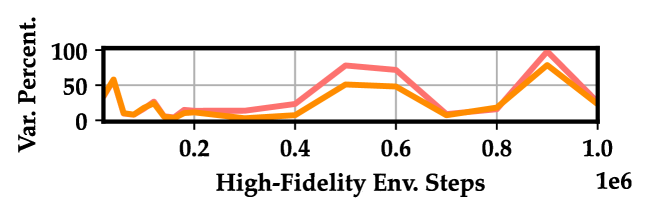
关键创新:最重要的技术创新点在于提出了多置信度控制变量策略梯度估计器。与传统的单置信度方法相比,该方法能够有效地利用低置信度数据来减少方差,从而提高训练效率。与直接使用低置信度数据进行训练的方法相比,该方法能够保证策略在真实环境中的性能。
关键设计:论文使用REINFORCE算法作为基础策略梯度算法,并在此基础上构建了多置信度变体。关键设计包括:1) 如何选择合适的低置信度仿真器;2) 如何确定高低置信度数据的比例;3) 如何构建有效的控制变量,以最大程度地减少方差。论文中对这些关键设计进行了详细的讨论和实验验证。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在具有轻度到中度动力学差距的机器人任务中,MFPG算法能够可靠地提高相对于仅使用高置信度数据的基线的性能中位数,并匹配领先的多置信度基线的性能。在较大的动力学差距下,MFPG表现出最强的鲁棒性。此外,即使在低置信度奖励错误指定的情况下,MFPG仍然有效。
🎯 应用场景
该研究成果可广泛应用于机器人控制、自动驾驶、游戏AI等领域,尤其是在仿真到真实(Sim-to-Real)迁移学习中具有重要价值。通过降低对高置信度数据的依赖,可以显著降低训练成本,加速算法的部署和应用。未来,该方法有望推动强化学习在更多实际场景中的应用。
📄 摘要(原文)
Many reinforcement learning (RL) algorithms are impractical for deployment in operational systems or for training with computationally expensive high-fidelity simulations, as they require large amounts of data. Meanwhile, low-fidelity simulators -- such as reduced-order models, heuristic rewards, or generative world models -- can cheaply provide useful data for RL training, even if they are too coarse for zero-shot transfer. We propose multi-fidelity policy gradients (MFPGs), an RL framework that mixes a small amount of data from the target environment with a control variate formed from a large volume of low-fidelity simulation data to construct an unbiased, variance-reduced estimator for on-policy policy gradients. We instantiate the framework with a multi-fidelity variant of the classical REINFORCE algorithm. We show that under standard assumptions, the MFPG estimator guarantees asymptotic convergence of REINFORCE to locally optimal policies in the target environment, and achieves faster finite-sample convergence rates compared to training with high-fidelity data alone. Empirically, we evaluate the MFPG algorithm across a suite of simulated robotics benchmark tasks with limited high-fidelity data but abundant off-dynamics, low-fidelity data. With mild-moderate dynamics gaps, MFPG reliably improves the median performance over a high-fidelity-only baseline, matching the performance of leading multi-fidelity baselines despite its simplicity and minimal tuning overhead. Under large dynamics gaps, MFPG demonstrates the strongest robustness among the evaluated multi-fidelity approaches. An additional experiment shows that MFPG can remain effective even under low-fidelity reward misspecification. Thus, MFPG not only offers a novel paradigm for efficient sim-to-real transfer but also provides a principled approach to managing the trade-off between policy performance and data collection costs.