Fairness-Aware Low-Rank Adaptation Under Demographic Privacy Constraints
作者: Parameswaran Kamalaruban, Mark Anderson, Stuart Burrell, Maeve Madigan, Piotr Skalski, David Sutton
分类: cs.LG, cs.CV
发布日期: 2025-03-07
💡 一句话要点
提出基于LoRA的公平性感知微调方法,解决人口隐私约束下的模型偏见问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 公平性感知学习 低秩适应 人口隐私 分布式训练 对抗训练 正交性损失 敏感信息遗忘
📋 核心要点
- 现有公平性微调方法依赖敏感属性访问,但实际中受隐私限制难以获取,阻碍公平模型开发。
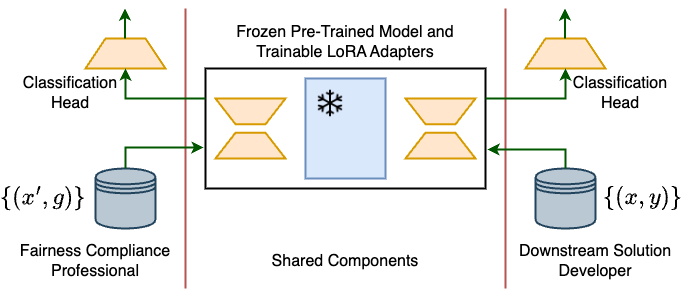
- 提出基于LoRA的分布式微调方法,模型开发者和审计员协作,无需共享敏感属性或预测器。
- 实验表明,正交性损失能有效降低偏差并保持模型效用,对抗训练在特定情况下改善公平性指标。
📝 摘要(中文)
预训练的基模型可以通过低秩适应(LoRA)进行特定任务的适配。然而,这些适配后的分类器的公平性尚未得到充分研究。现有的公平性感知微调方法依赖于对敏感属性或其预测器的直接访问,但在实践中,这些敏感属性通常受到严格的消费者隐私控制,模型开发者无法获得这些属性或其预测器,从而阻碍了公平模型的开发。为了解决这个问题,我们提出了一组基于LoRA的微调方法,这些方法可以以分布式方式进行训练,模型开发者和公平性审计员可以在不共享敏感属性或预测器的情况下进行协作。本文在CelebA和UTK-Face数据集上,使用ImageNet预训练的ViT-Base模型,评估了三种这样的方法——敏感信息遗忘、对抗训练和正交性损失——并与一个公平性无关的基线进行比较。我们发现,正交性损失始终如一地降低了偏差,同时保持或提高了效用,而对抗训练在某些情况下改善了假阳性率均等性和人口均等性,而敏感信息遗忘没有提供明显的好处。在存在显著偏差的任务中,分布式公平性感知微调方法可以有效地消除偏差,而不会损害消费者隐私,并且在大多数情况下,可以提高模型效用。
🔬 方法详解
问题定义:论文旨在解决在人口隐私约束下,如何对预训练模型进行公平性感知的低秩适应(LoRA)微调问题。现有方法通常需要直接访问敏感属性或其预测器,这在实际应用中由于隐私保护的限制往往不可行。因此,如何在不访问敏感信息的情况下,降低模型对特定人口群体的偏见,同时保持模型在目标任务上的性能,是本研究要解决的核心问题。
核心思路:论文的核心思路是利用分布式训练框架,让模型开发者和公平性审计员在不共享敏感属性的前提下协同工作。通过设计特定的损失函数或训练策略,例如敏感信息遗忘、对抗训练和正交性损失,来引导模型学习公平的表示,从而降低模型偏差。LoRA的使用降低了微调的计算成本,使其更易于应用到大型预训练模型上。
技术框架:整体框架包含两个主要参与者:模型开发者和公平性审计员。模型开发者负责模型的训练和微调,而公平性审计员负责评估模型的公平性。双方通过一个安全的多方计算(MPC)协议进行通信,以确保敏感属性不会被泄露。具体流程如下:1) 模型开发者使用LoRA对预训练模型进行微调,并将其发送给公平性审计员。2) 公平性审计员在本地使用敏感属性评估模型的公平性指标。3) 根据评估结果,公平性审计员向模型开发者提供反馈,例如调整损失函数的权重或采用不同的训练策略。4) 模型开发者根据反馈调整模型,并重复上述过程,直到模型达到预期的公平性水平。
关键创新:论文的关键创新在于提出了一套基于LoRA的分布式公平性感知微调方法,可以在不访问敏感属性的情况下,有效地降低模型偏差。这种方法解决了现有公平性微调方法对敏感数据依赖的局限性,使其更适用于实际应用场景。此外,论文还对三种不同的公平性干预策略(敏感信息遗忘、对抗训练和正交性损失)进行了比较,并分析了它们在不同数据集上的表现。
关键设计:论文中涉及的关键设计包括:1) 使用LoRA进行低秩适应,降低微调的计算成本。2) 设计了三种不同的公平性干预策略:a) 敏感信息遗忘:通过最小化模型对敏感属性的预测能力来消除偏差。b) 对抗训练:通过训练一个对抗网络来识别和消除模型中的偏差。c) 正交性损失:通过鼓励模型学习与敏感属性正交的表示来降低偏差。3) 使用安全的多方计算(MPC)协议来保护敏感属性的隐私。4) 实验中,ViT-Base模型在CelebA和UTK-Face数据集上进行微调,并使用人口均等性和假阳性率均等性等指标来评估模型的公平性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,正交性损失在降低模型偏差的同时,能够保持甚至提高模型在CelebA和UTK-Face数据集上的性能。对抗训练在某些情况下可以改善假阳性率均等性和人口均等性。相比之下,敏感信息遗忘没有表现出明显的优势。这些结果表明,分布式公平性感知微调方法可以在不损害消费者隐私的情况下,有效地消除模型偏差,并提高模型的整体效用。
🎯 应用场景
该研究成果可应用于各种需要公平性和隐私保护的场景,例如人脸识别、信用评分、医疗诊断等。通过在分布式环境中进行公平性感知的微调,可以在不泄露用户敏感信息的前提下,构建更加公平和可靠的AI系统。未来,该方法可以进一步扩展到其他类型的模型和任务中,并与其他隐私保护技术相结合,以实现更高级别的公平性和隐私保护。
📄 摘要(原文)
Pre-trained foundation models can be adapted for specific tasks using Low-Rank Adaptation (LoRA). However, the fairness properties of these adapted classifiers remain underexplored. Existing fairness-aware fine-tuning methods rely on direct access to sensitive attributes or their predictors, but in practice, these sensitive attributes are often held under strict consumer privacy controls, and neither the attributes nor their predictors are available to model developers, hampering the development of fair models. To address this issue, we introduce a set of LoRA-based fine-tuning methods that can be trained in a distributed fashion, where model developers and fairness auditors collaborate without sharing sensitive attributes or predictors. In this paper, we evaluate three such methods - sensitive unlearning, adversarial training, and orthogonality loss - against a fairness-unaware baseline, using experiments on the CelebA and UTK-Face datasets with an ImageNet pre-trained ViT-Base model. We find that orthogonality loss consistently reduces bias while maintaining or improving utility, whereas adversarial training improves False Positive Rate Parity and Demographic Parity in some cases, and sensitive unlearning provides no clear benefit. In tasks where significant biases are present, distributed fairness-aware fine-tuning methods can effectively eliminate bias without compromising consumer privacy and, in most cases, improve model utility.