Impoola: The Power of Average Pooling for Image-Based Deep Reinforcement Learning
作者: Raphael Trumpp, Ansgar Schäfftlein, Mirco Theile, Marco Caccamo
分类: cs.LG, cs.AI
发布日期: 2025-03-07 (更新: 2025-09-03)
备注: Reinforcement Learning Conference 2025
🔗 代码/项目: GITHUB
💡 一句话要点
Impoola-CNN:利用平均池化提升图像深度强化学习性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 图像编码器 全局平均池化 泛化能力 Procgen基准
📋 核心要点
- 现有基于图像的深度强化学习模型依赖增大模型规模来提升性能,但缺乏对网络设计的深入探索。
- 论文提出Impoola-CNN,用全局平均池化代替Impala-CNN中的特征图扁平化,降低网络的平移敏感性。
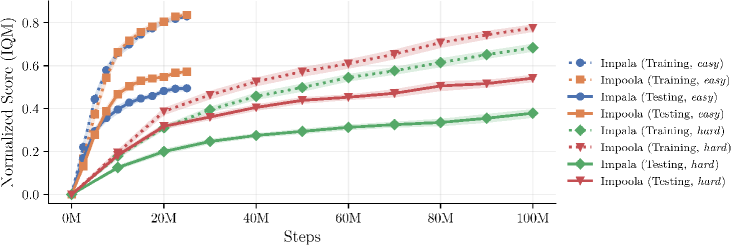
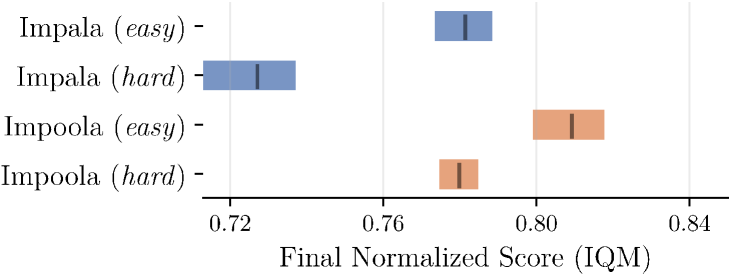
- 实验表明,Impoola-CNN在Procgen基准测试中优于更大更复杂的模型,尤其在泛化能力上表现突出。
📝 摘要(中文)
随着基于图像的深度强化学习处理更具挑战性的任务,增大模型规模已成为提高性能的重要因素。最近的研究通过关注缩放网络的参数效率来实现这一点,通常使用Impala-CNN(一个15层ResNet风格的网络)作为图像编码器。然而,虽然Impala-CNN明显优于较旧的CNN架构,但深度强化学习专用图像编码器的网络设计的潜在改进在很大程度上仍未被探索。我们发现,用全局平均池化代替Impala-CNN中输出特征图的扁平化处理,可以显著提高性能。这种方法在Procgen基准测试中优于更大更复杂的模型,尤其是在泛化方面。我们将我们提出的编码器模型称为Impoola-CNN。网络平移敏感性的降低可能是这种改进的核心,因为我们观察到在没有以智能体为中心的观察的游戏中收益最为显著。我们的结果表明,网络缩放不仅仅是增加模型大小,高效的网络设计也是一个重要因素。我们的代码可在https://github.com/raphajaner/impoola上找到。
🔬 方法详解
问题定义:论文旨在解决基于图像的深度强化学习中,现有模型过度依赖模型规模,而忽略网络设计效率的问题。现有方法,如直接使用Impala-CNN,虽然有效,但可能存在冗余,且对图像的微小平移过于敏感,影响泛化能力。
核心思路:论文的核心思路是用全局平均池化(Global Average Pooling, GAP)代替Impala-CNN中将特征图扁平化的操作。GAP能够提取特征图的全局信息,降低模型对图像平移的敏感性,从而提高模型的泛化能力。
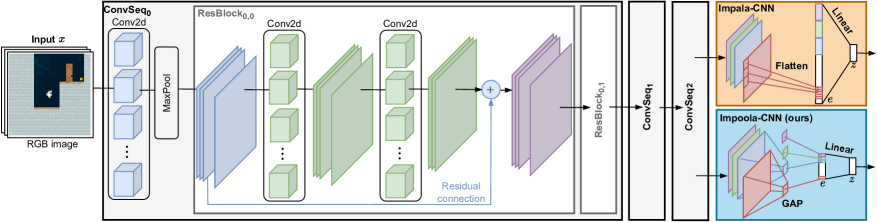
技术框架:整体框架与标准的深度强化学习流程一致,主要改进在于图像编码器部分。首先,原始图像输入到Impoola-CNN编码器中。Impoola-CNN的结构与Impala-CNN类似,但关键区别在于最后一层卷积层后,不再进行扁平化操作,而是使用全局平均池化。池化后的特征向量被送入后续的策略网络和价值网络,用于决策和价值评估。
关键创新:最重要的技术创新点是用全局平均池化代替了特征图的扁平化。与直接扁平化相比,GAP能够更好地保留空间信息,并降低模型对图像平移的敏感性。这使得模型能够学习到更鲁棒的特征表示,从而提高泛化能力。
关键设计:Impoola-CNN的网络结构基本沿用了Impala-CNN,主要修改在于将最后一层卷积层的输出进行全局平均池化,得到一个特征向量。没有特别提到损失函数或参数设置上的修改,重点在于网络结构的改进。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Impoola-CNN在Procgen基准测试中优于Impala-CNN以及其他更大的模型,尤其在泛化能力方面有显著提升。在没有智能体中心观测的游戏中,性能提升最为明显,验证了全局平均池化降低平移敏感性的有效性。代码已开源,方便复现和进一步研究。
🎯 应用场景
该研究成果可应用于各种基于图像的深度强化学习任务,例如游戏AI、机器人导航、自动驾驶等。通过提高模型的泛化能力,可以使智能体在更复杂、更真实的环境中表现更好。该方法具有实际应用价值,可以降低模型对训练数据的依赖,提高模型的鲁棒性。
📄 摘要(原文)
As image-based deep reinforcement learning tackles more challenging tasks, increasing model size has become an important factor in improving performance. Recent studies achieved this by focusing on the parameter efficiency of scaled networks, typically using Impala-CNN, a 15-layer ResNet-inspired network, as the image encoder. However, while Impala-CNN evidently outperforms older CNN architectures, potential advancements in network design for deep reinforcement learning-specific image encoders remain largely unexplored. We find that replacing the flattening of output feature maps in Impala-CNN with global average pooling leads to a notable performance improvement. This approach outperforms larger and more complex models in the Procgen Benchmark, particularly in terms of generalization. We call our proposed encoder model Impoola-CNN. A decrease in the network's translation sensitivity may be central to this improvement, as we observe the most significant gains in games without agent-centered observations. Our results demonstrate that network scaling is not just about increasing model size - efficient network design is also an essential factor. We make our code available at https://github.com/raphajaner/impoola.