Continual Pre-training of MoEs: How robust is your router?
作者: Benjamin Thérien, Charles-Étienne Joseph, Zain Sarwar, Ashwinee Panda, Anirban Das, Shi-Xiong Zhang, Stephen Rawls, Sambit Sahu, Eugene Belilovsky, Irina Rish
分类: cs.LG, cs.AI, cs.CL
发布日期: 2025-03-06 (更新: 2025-11-10)
💡 一句话要点
研究MoE模型持续预训练的鲁棒性,揭示路由算法对性能的影响
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 持续预训练 路由算法 语言模型 鲁棒性
📋 核心要点
- MoE模型在持续预训练中面临路由算法带来的挑战,例如灾难性遗忘和负载不均衡。
- 研究探索了Sinkhorn平衡和Z-and-Aux-loss平衡等路由算法在MoE模型持续预训练中的鲁棒性。
- 实验结果表明,即使没有重放,MoE模型在持续预训练中也表现出对分布偏移的鲁棒性,并保持了样本效率。
📝 摘要(中文)
稀疏激活的混合专家(MoE) Transformer是构建基础模型的有前景的架构。与每个前向传播需要相同浮点运算(FLOPs)的稠密Transformer相比,MoE在训练时具有更高的样本效率,并能实现更强的性能。许多闭源和开源的前沿语言模型都采用了MoE架构。因此,从业者自然希望使用大量新收集的数据来扩展这些模型的能力,而无需完全重新训练它们。先前的工作表明,简单的重放、学习率重热和重衰减的组合可以实现稠密解码器Transformer的持续预训练(CPT),与完全重新训练相比,性能下降最小。然而,对于解码器MoE Transformer,尚不清楚路由算法将如何影响持续预训练的性能:1)相对于稠密模型,MoE Transformer的路由器是否会加剧遗忘?2)CPT后,路由器是否在先前的分布上保持平衡的负载?3)应用于稠密模型的相同策略是否足以持续预训练MoE LLM?在下文中,我们进行了一项大规模研究,训练了一个5亿参数的稠密Transformer和四个5亿激活/20亿总参数的MoE Transformer。每个模型都训练了6000亿个token。我们的结果表明,对于使用Sinkhorn平衡和Z-and-Aux-loss平衡路由算法的MoE,即使在没有重放的情况下持续预训练的MoE中,也具有令人惊讶的分布偏移鲁棒性。此外,我们表明,MoE LLM在CPT期间保持其样本效率(相对于FLOP匹配的稠密模型),并且它们可以以一小部分成本匹配完全重新训练的MoE的性能。
🔬 方法详解
问题定义:论文旨在研究MoE(Mixture of Experts)模型在持续预训练(Continual Pre-training, CPT)场景下的性能表现,特别是关注路由算法对模型性能的影响。现有方法在稠密模型上取得了较好的CPT效果,但在MoE模型上,路由器的存在可能导致灾难性遗忘、负载不均衡等问题,使得CPT的性能难以保证。
核心思路:论文的核心思路是通过大规模实验,对比不同路由算法(Sinkhorn平衡和Z-and-Aux-loss平衡)在MoE模型CPT中的表现,并与稠密模型进行对比。通过分析实验结果,评估MoE模型在CPT中的鲁棒性、样本效率以及是否需要额外的策略来缓解潜在的问题。
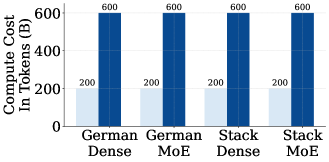
技术框架:论文采用的模型包括一个5亿参数的稠密Transformer和四个5亿激活/20亿总参数的MoE Transformer。所有模型均在6000亿token的数据集上进行训练。CPT过程涉及使用新的数据集对预训练模型进行进一步训练。实验主要关注模型在CPT后的性能表现,以及路由器的负载均衡情况。
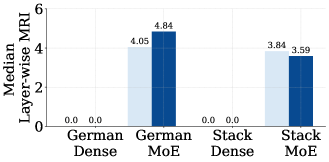
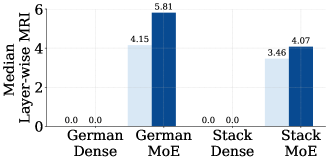
关键创新:论文的关键创新在于系统性地研究了MoE模型在CPT中的性能,并揭示了路由算法对CPT效果的影响。实验结果表明,MoE模型在CPT中具有较强的鲁棒性,即使在没有重放的情况下也能保持较好的性能。这与之前的认知有所不同,表明MoE模型在CPT方面具有潜力。
关键设计:论文的关键设计包括:1)选择Sinkhorn平衡和Z-and-Aux-loss平衡作为代表性的路由算法;2)使用大规模数据集进行训练,以保证实验结果的可靠性;3)对比MoE模型和稠密模型在CPT中的性能,以评估MoE模型的优势和劣势;4)分析路由器的负载均衡情况,以了解路由算法对模型性能的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用Sinkhorn平衡和Z-and-Aux-loss平衡路由算法的MoE模型,即使在没有重放的情况下进行持续预训练,也表现出对分布偏移的鲁棒性。MoE LLM在CPT期间保持了其样本效率,并且可以以较低的成本达到完全重新训练的MoE模型的性能。
🎯 应用场景
该研究成果可应用于大规模语言模型的持续学习和知识更新。通过持续预训练,可以使MoE模型适应新的数据分布和任务需求,而无需从头开始训练,从而降低训练成本和时间。这对于快速迭代和部署大型语言模型具有重要意义。
📄 摘要(原文)
Sparsely-activated Mixture of Experts (MoE) transformers are promising architectures for foundation models. Compared to dense transformers that require the same amount of floating-point operations (FLOPs) per forward pass, MoEs benefit from improved sample efficiency at training time and achieve much stronger performance. Many closed-source and open-source frontier language models have thus adopted an MoE architecture. Naturally, practitioners will want to extend the capabilities of these models with large amounts of newly collected data without completely re-training them. Prior work has shown that a simple combination of replay, learning rate re-warming, and re-decaying can enable the continual pre-training (CPT) of dense decoder-only transformers with minimal performance degradation compared to full re-training. In the case of decoder-only MoE transformers, however, it is unclear how the routing algorithm will impact continual pre-training performance: 1) do the MoE transformer's routers exacerbate forgetting relative to a dense model?; 2) do the routers maintain a balanced load on previous distributions after CPT?; 3) are the same strategies applied to dense models sufficient to continually pre-train MoE LLMs? In what follows, we conduct a large-scale study training a 500M parameter dense transformer and four 500M-active/2B-total parameter MoE transformers. Each model is trained for 600B tokens. Our results establish a surprising robustness to distribution shifts for MoEs using both Sinkhorn-Balanced and Z-and-Aux-loss-balanced routing algorithms, even in MoEs continually pre-trained without replay. Moreover, we show that MoE LLMs maintain their sample efficiency (relative to a FLOP-matched dense model) during CPT and that they can match the performance of a fully re-trained MoE at a fraction of the cost.