Leveraging Large Language Models to Address Data Scarcity in Machine Learning: Applications in Graphene Synthesis
作者: Devi Dutta Biswajeet, Sara Kadkhodaei
分类: physics.comp-ph, cond-mat.mtrl-sci, cs.LG
发布日期: 2025-03-06 (更新: 2025-03-10)
备注: 20 pages, 10 figures, 4 tables; Supplementary Material with 13 figures and 4 tables
💡 一句话要点
利用大语言模型解决石墨烯合成中机器学习的数据稀缺问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数据增强 机器学习 石墨烯合成 材料科学
📋 核心要点
- 材料科学机器学习面临实验数据稀缺的挑战,现有方法难以有效处理数据质量不一、格式不一致等问题。
- 论文提出利用大语言模型(LLM)进行数据增强,包括缺失值填补和复杂基底命名的编码,以提升模型性能。
- 实验结果表明,结合LLM数据增强的SVM模型在石墨烯层分类任务中,二元和三元分类准确率分别提升至65%和72%。
📝 摘要(中文)
材料科学中的机器学习面临数据有限的挑战,特别是原位实验合成数据成本高昂且耗时。从现有文献中挖掘数据会引入数据质量参差不齐、格式不一致以及实验参数报告存在差异等问题,从而使为学习算法创建一致的特征变得复杂。此外,连续特征和离散特征的组合会阻碍数据有限情况下的学习过程。本文提出了利用大型语言模型(LLM)来增强对现有文献中收集的石墨烯化学气相沉积合成的有限异构数据集进行机器学习性能的策略。这些策略包括用于推断缺失数据点的提示模态,以及利用大型语言模型嵌入来编码化学气相沉积实验中报告的复杂基底命名。所提出的策略增强了使用支持向量机(SVM)模型进行石墨烯层分类的效果,将二元分类准确率从39%提高到65%,三元分类准确率从52%提高到72%。我们比较了SVM和GPT-4模型的性能,两者都在相同的数据上进行了训练和微调。结果表明,数值分类器与LLM驱动的数据增强相结合,优于独立的LLM预测器,这表明在数据稀缺的情况下,利用LLM策略改进预测学习需要的不仅仅是在数据集上进行简单的微调。相反,它需要复杂的数据推断和特征空间同质化方法来实现最佳性能。所提出的策略强调数据增强技术,为提高稀缺、非均匀数据集上的机器学习性能提供了一个广泛适用的框架。
🔬 方法详解
问题定义:论文旨在解决石墨烯化学气相沉积合成领域中,机器学习模型训练数据稀缺且异构的问题。现有方法难以有效处理从文献中提取的数据,这些数据存在质量不一、格式不一致以及实验参数报告差异等问题,导致模型性能受限。
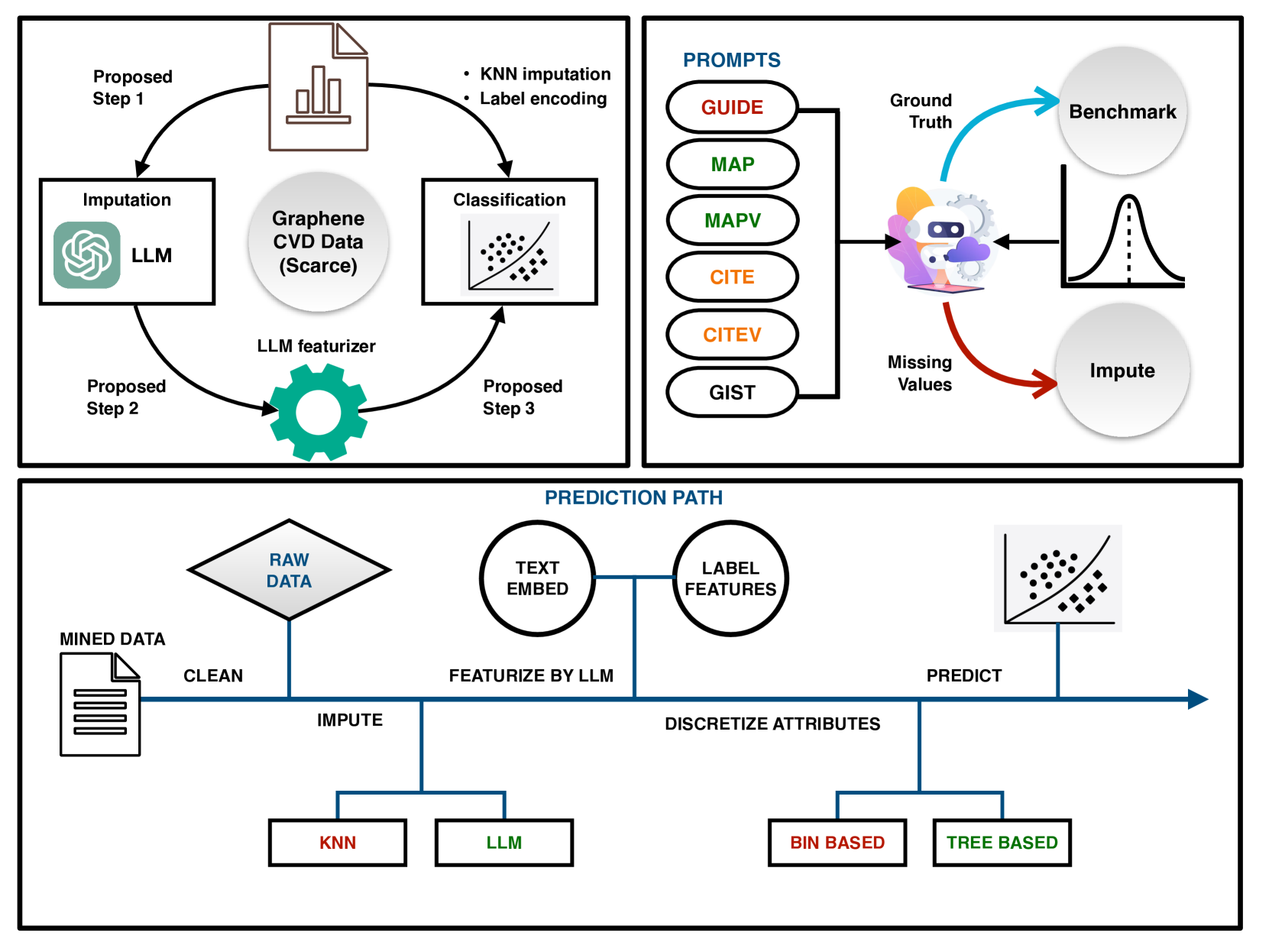
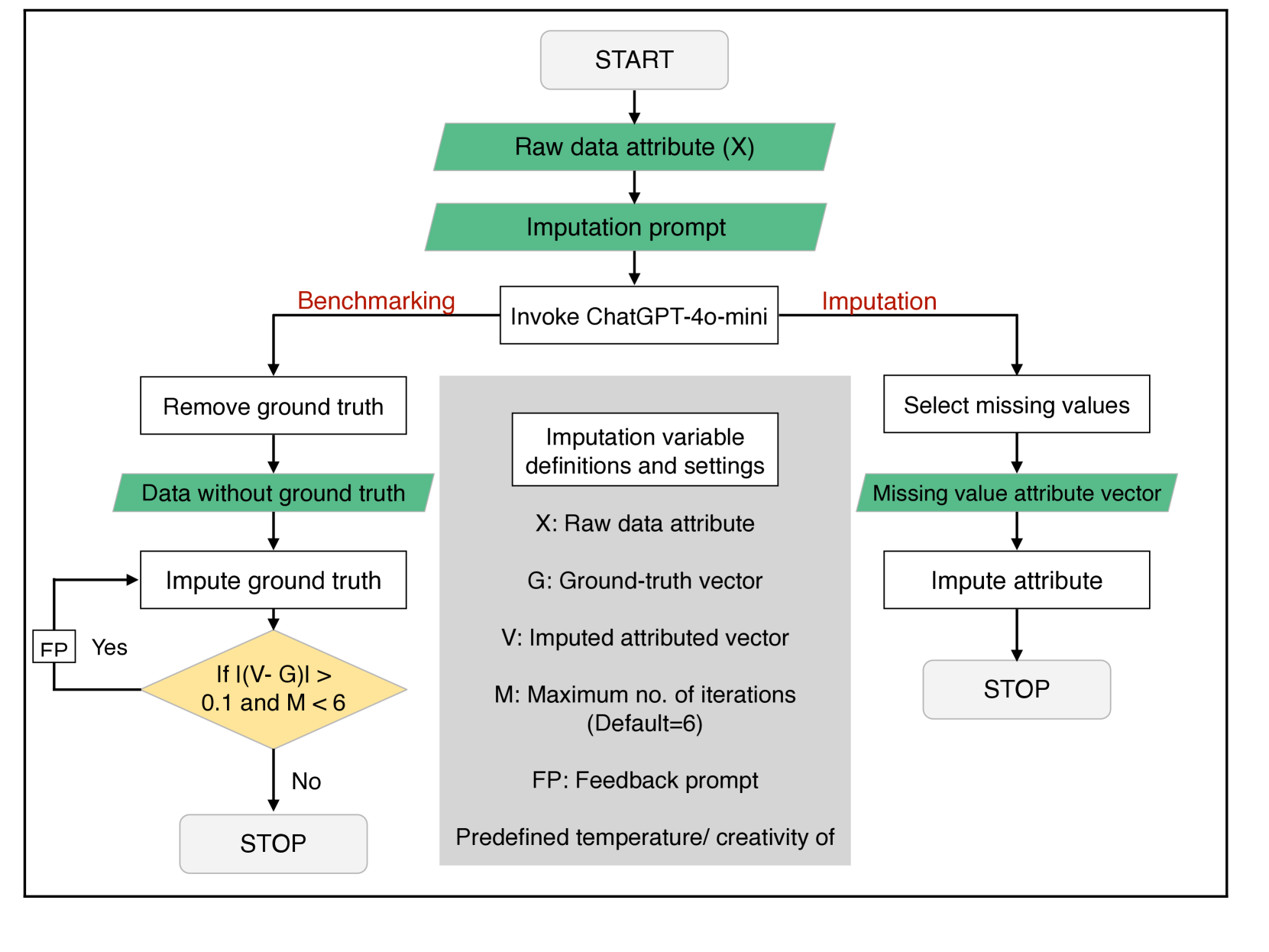
核心思路:论文的核心思路是利用大语言模型(LLM)的强大能力进行数据增强,从而提升机器学习模型在数据稀缺场景下的性能。通过LLM,可以实现缺失数据的填补和复杂特征的编码,从而提高数据的质量和一致性。
技术框架:论文提出的技术框架主要包含以下几个阶段:1) 数据收集:从现有文献中收集石墨烯化学气相沉积合成数据。2) 数据预处理:对收集到的数据进行清洗和整理,识别缺失值和不一致的特征。3) LLM数据增强:利用LLM进行缺失值填补和复杂基底命名的编码。4) 模型训练与评估:使用增强后的数据训练支持向量机(SVM)模型,并评估其在石墨烯层分类任务上的性能。同时,与直接在原始数据上微调的GPT-4模型进行对比。
关键创新:论文的关键创新在于将大语言模型应用于材料科学领域的数据增强,并证明了在数据稀缺场景下,相比于直接微调LLM,利用LLM进行数据增强能够取得更好的效果。这种方法强调了数据质量的重要性,并提供了一种通用的数据增强框架。
关键设计:论文的关键设计包括:1) 针对缺失值填补,设计合适的prompt模态,引导LLM生成合理的数值。2) 利用LLM的embedding能力,将复杂的基底命名编码成向量表示,从而实现特征空间的同质化。3) 使用支持向量机(SVM)作为数值分类器,并与GPT-4模型进行对比,验证数据增强的有效性。
🖼️ 关键图片
📊 实验亮点
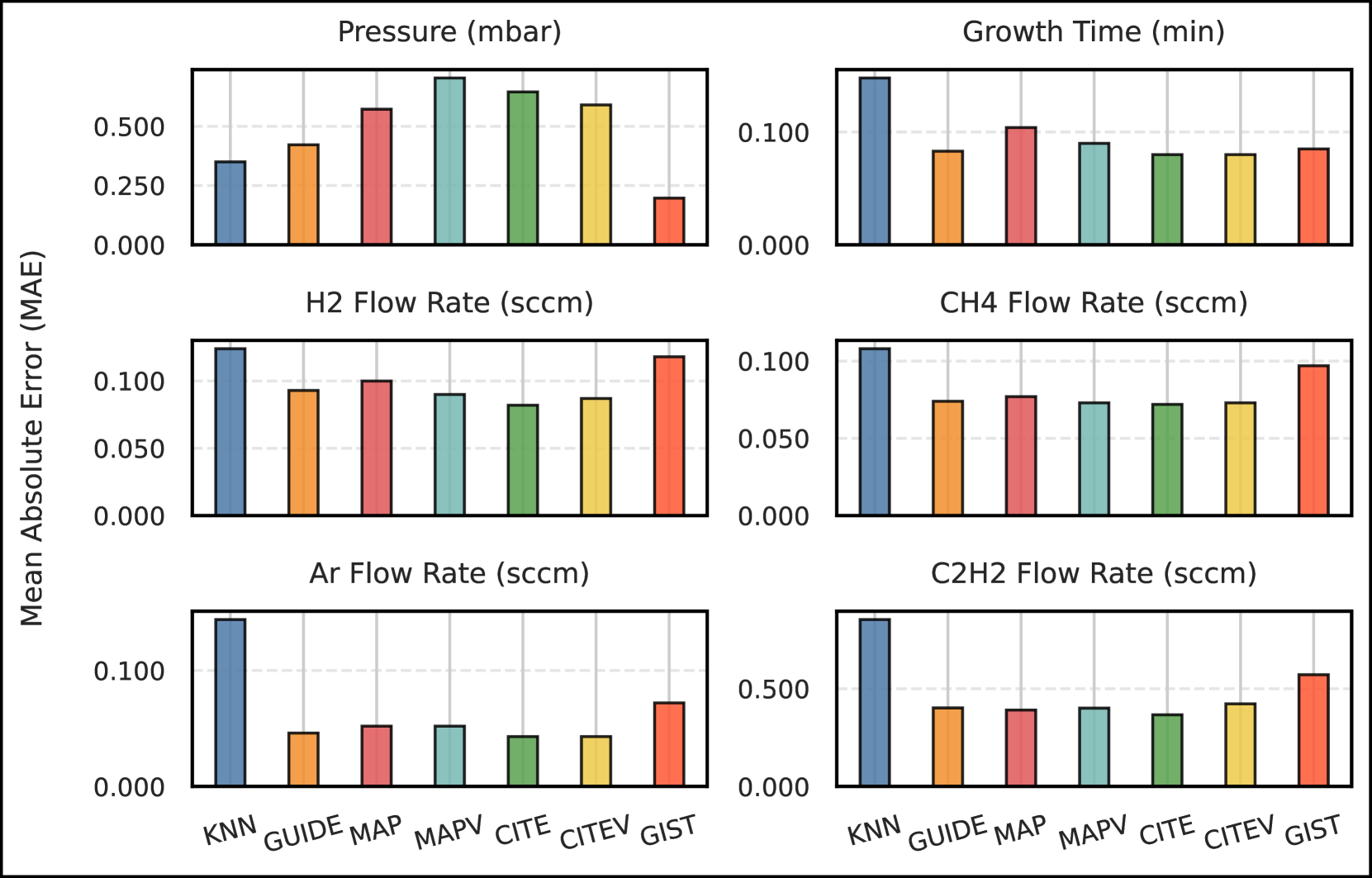
实验结果表明,通过LLM进行数据增强后,SVM模型在石墨烯层分类任务中的性能显著提升。二元分类准确率从39%提高到65%,提升了26个百分点;三元分类准确率从52%提高到72%,提升了20个百分点。同时,实验证明,结合LLM数据增强的SVM模型优于直接在原始数据上微调的GPT-4模型。
🎯 应用场景
该研究成果可应用于材料科学领域,特别是针对合成数据稀缺的材料,例如新型二维材料、纳米材料等。通过利用大语言模型进行数据增强,可以降低实验成本,加速材料发现和优化过程,并为其他数据稀缺领域的机器学习应用提供借鉴。
📄 摘要(原文)
Machine learning in materials science faces challenges due to limited experimental data, as generating synthesis data is costly and time-consuming, especially with in-house experiments. Mining data from existing literature introduces issues like mixed data quality, inconsistent formats, and variations in reporting experimental parameters, complicating the creation of consistent features for the learning algorithm. Additionally, combining continuous and discrete features can hinder the learning process with limited data. Here, we propose strategies that utilize large language models (LLMs) to enhance machine learning performance on a limited, heterogeneous dataset of graphene chemical vapor deposition synthesis compiled from existing literature. These strategies include prompting modalities for imputing missing data points and leveraging large language model embeddings to encode the complex nomenclature of substrates reported in chemical vapor deposition experiments. The proposed strategies enhance graphene layer classification using a support vector machine (SVM) model, increasing binary classification accuracy from 39% to 65% and ternary accuracy from 52% to 72%. We compare the performance of the SVM and a GPT-4 model, both trained and fine-tuned on the same data. Our results demonstrate that the numerical classifier, when combined with LLM-driven data enhancements, outperforms the standalone LLM predictor, highlighting that in data-scarce scenarios, improving predictive learning with LLM strategies requires more than simple fine-tuning on datasets. Instead, it necessitates sophisticated approaches for data imputation and feature space homogenization to achieve optimal performance. The proposed strategies emphasize data enhancement techniques, offering a broadly applicable framework for improving machine learning performance on scarce, inhomogeneous datasets.