Predictable Scale: Part I, Step Law -- Optimal Hyperparameter Scaling Law in Large Language Model Pretraining
作者: Houyi Li, Wenzhen Zheng, Qiufeng Wang, Hanshan Zhang, Zili Wang, Shijie Xuyang, Yuantao Fan, Zhenyu Ding, Haoying Wang, Ning Ding, Shuigeng Zhou, Xiangyu Zhang, Daxin Jiang
分类: cs.LG, cs.AI
发布日期: 2025-03-06 (更新: 2025-08-19)
备注: 22 pages
🔗 代码/项目: GITHUB
💡 一句话要点
提出Step Law:大规模语言模型预训练超参数优化通用Scaling Law
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大规模语言模型 超参数优化 Scaling Law 预训练 Step Law 模型训练 深度学习 模型优化
📋 核心要点
- 现有超参数优化方法缺乏跨模型架构和数据配方的通用性,难以有效指导大规模语言模型的训练。
- 论文提出Step Law,揭示了最佳学习率和批量大小与模型大小和数据集大小之间的幂律关系。
- 实验表明,Step Law能有效预测最优超参数,性能接近详尽搜索,且适用于多种模型结构和数据配方。
📝 摘要(中文)
大型语言模型(LLM)在各种任务中表现出卓越的能力,但其有效部署需要仔细的超参数优化。尽管现有方法已经探索了超参数对模型性能的影响,但仍然缺乏一个跨模型架构和数据配方的通用框架。本研究进行了前所未有的实证研究,从头开始训练了超过3700个LLM,跨越100万亿个token,消耗了近一百万个NVIDIA H800 GPU小时,从而建立了LLM预训练中超参数优化的通用Scaling Law,称为Step Law。我们通过实验观察到,在固定的模型大小(N)和数据集大小(D)下,超参数呈现凸形,具有广泛的最优值,大大降低了超参数搜索的复杂性。在此基础上,我们正式定义并通过实验验证了Step Law:最佳学习率遵循与N和D的幂律关系,而最佳批量大小主要受D影响,并且在很大程度上不受N的影响。值得注意的是,我们估计的最优值与通过详尽搜索发现的全局最佳性能仅相差0.094%。据我们所知,Step Law是第一个统一不同模型形状和结构(如混合专家模型和密集Transformer)的Scaling Law,并建立了跨不同数据配方的最佳超参数Scaling Law。我们为社区贡献了一个通用的、即插即用的最佳超参数工具,有望推动大规模高效LLM训练。所有实验代码、数据和检查点均可在https://github.com/step-law/steplaw公开获取。
🔬 方法详解
问题定义:大规模语言模型(LLM)的训练需要大量的计算资源,而超参数的选择对模型的最终性能至关重要。现有的超参数优化方法,如网格搜索、随机搜索和贝叶斯优化等,计算成本高昂,且缺乏跨不同模型结构和数据配方的通用性,难以指导LLM的高效训练。因此,如何找到一种通用的、高效的超参数优化方法,是当前LLM研究面临的重要挑战。
核心思路:论文的核心思路是通过大规模的实验,探索超参数与模型性能之间的关系,并从中发现潜在的Scaling Law。具体来说,作者假设最佳学习率和批量大小与模型大小(N)和数据集大小(D)之间存在某种函数关系,并通过实验数据拟合出这种关系。这种思路的优势在于,它能够将超参数优化问题转化为一个函数拟合问题,从而大大降低了搜索空间,提高了优化效率。
技术框架:论文的技术框架主要包括以下几个步骤:1)设计大规模的实验,训练大量的LLM,并记录它们的性能和超参数;2)分析实验数据,探索超参数与模型性能之间的关系;3)基于实验结果,提出Step Law,即最佳学习率和批量大小与模型大小和数据集大小之间的幂律关系;4)验证Step Law的有效性,即使用Step Law预测的超参数训练LLM,并与使用其他方法训练的LLM进行比较。
关键创新:论文最重要的技术创新点在于提出了Step Law,这是第一个统一不同模型形状和结构(如混合专家模型和密集Transformer)的Scaling Law,并建立了跨不同数据配方的最佳超参数Scaling Law。与现有方法相比,Step Law具有更高的通用性和效率,能够指导LLM的高效训练。
关键设计:Step Law的关键设计在于确定了最佳学习率和批量大小与模型大小和数据集大小之间的幂律关系。具体来说,最佳学习率与N和D的幂成正比,而最佳批量大小主要受D影响,并且在很大程度上不受N的影响。论文通过实验数据拟合出了这些幂律关系的具体参数,从而使得Step Law能够预测最优超参数。
🖼️ 关键图片
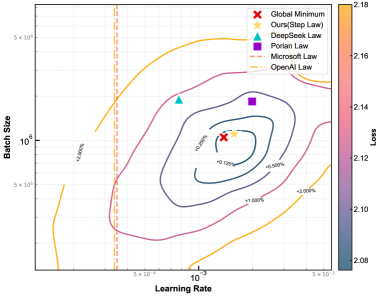
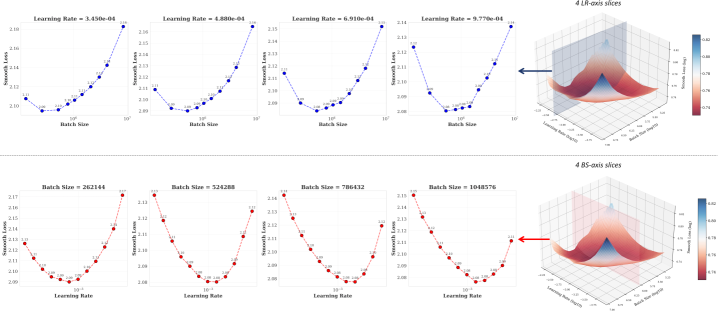
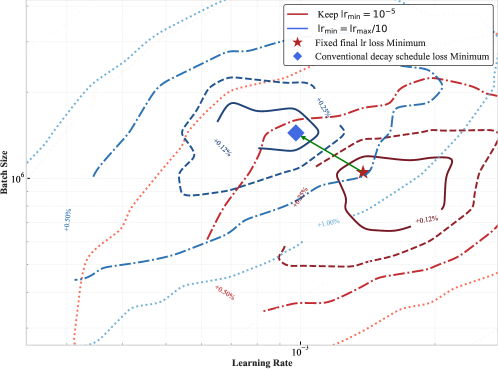
📊 实验亮点
实验结果表明,Step Law能够有效预测最优超参数,使用Step Law预测的超参数训练的LLM,其性能与通过详尽搜索发现的全局最佳性能仅相差0.094%。此外,Step Law适用于多种模型结构(包括混合专家模型和密集Transformer)和数据配方,验证了其通用性和有效性。
🎯 应用场景
该研究成果可广泛应用于大规模语言模型的预训练,帮助研究人员和工程师更高效地选择超参数,降低训练成本,提升模型性能。此外,Step Law的通用性使其能够应用于不同模型结构和数据配方,具有很高的实际应用价值和推广潜力,有望加速LLM的研发和应用。
📄 摘要(原文)
The impressive capabilities of Large Language Models (LLMs) across diverse tasks are now well established, yet their effective deployment necessitates careful hyperparameter optimization. Although existing methods have explored the influence of hyperparameters on model performance, a principled and generalizable framework across model architectures and data recipes remains absent. In this study, we conduct an unprecedented empirical investigation training over 3,700 LLMs from scratch across 100 trillion tokens, consuming nearly one million NVIDIA H800 GPU hours to establish a universal Scaling Law for hyperparameter optimization in LLM Pre-training, called Step Law. We empirically observe that, under fixed model size ($N$) and dataset size ($D$), the hyperparameter landscape exhibits convexity with a broad optimum, substantially reducing the complexity of hyperparameter search. Building on this insight, we formally define and empirically validate the Step Law: The optimal learning rate follows a power-law relationship with $N$ and $D$, while the optimal batch size is primarily influenced by $D$ and remains largely invariant to $N$.Notably, our estimated optima deviate from the global best performance found via exhaustive search by merely 0.094\% on the test set. To our best known, Step Law is the first that unifies different model shapes and structures, such as Mixture-of-Experts models and dense transformers, as well as establishes optimal hyperparameter scaling laws across diverse data recipes. We contribute a universal, plug-and-play optimal hyperparameter tool for the community, which is expected to advance efficient LLM training at scale. All experimental code, data and checkpoints are publicly available at https://github.com/step-law/steplaw