Accurate predictive model of band gap with selected important features based on explainable machine learning
作者: Joohwi Lee, Kaito Miyamoto
分类: cond-mat.mtrl-sci, cs.LG
发布日期: 2025-03-06 (更新: 2025-10-30)
备注: 9 pages, 3 figures, SI is included
💡 一句话要点
提出基于可解释机器学习的带隙预测模型,提升泛化能力并降低计算成本。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 材料信息学 可解释机器学习 带隙预测 特征选择 支持向量回归
📋 核心要点
- 非线性机器学习模型在材料属性预测中表现出色,但其黑盒特性限制了解释性,并可能引入冗余特征。
- 该研究利用可解释机器学习(XML)技术,通过特征重要性分析,构建精简且高性能的带隙预测模型。
- 实验表明,XML引导的紧凑模型在保持域内精度的同时,显著提升了域外数据的泛化能力,降低了预测误差。
📝 摘要(中文)
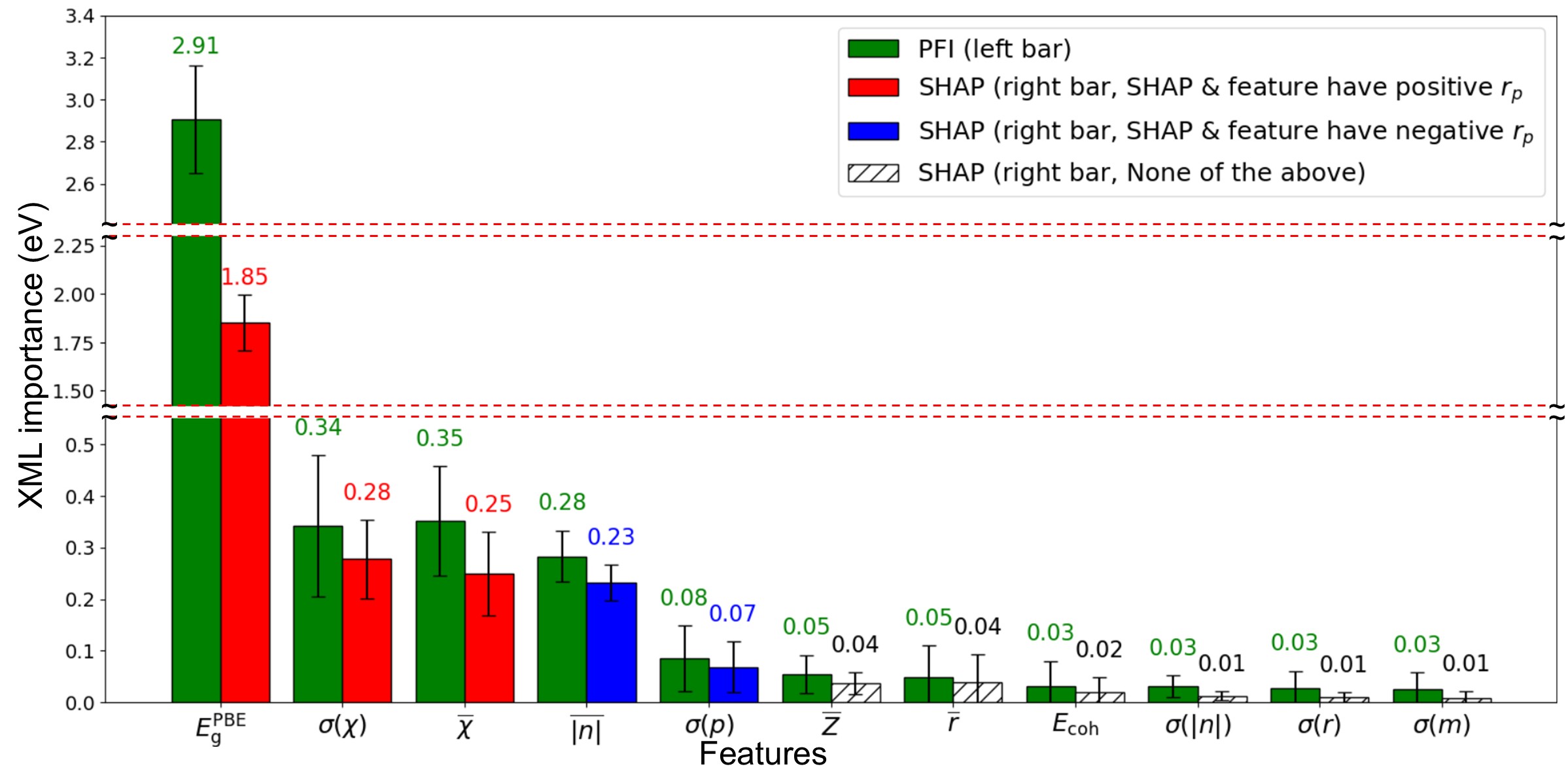
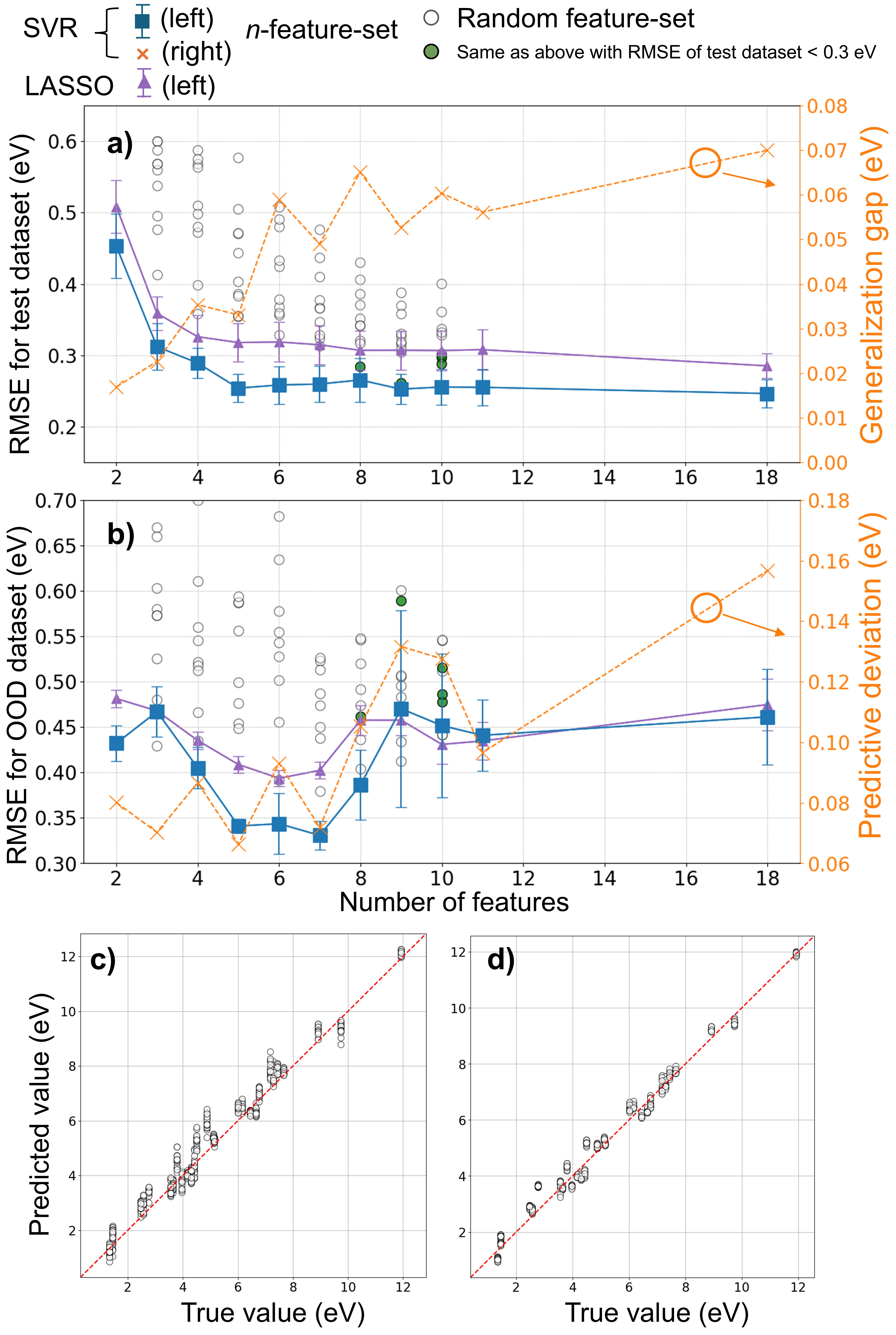
在快速发展的材料信息学领域,非线性机器学习模型在材料属性预测方面表现出卓越的能力。然而,它们的黑盒特性限制了解释性,并且可能包含对模型性能没有贡献甚至降低性能的特征。本研究采用可解释机器学习(XML)技术,包括排列特征重要性和SHapley Additive exPlanation,应用于原始支持向量回归模型,该模型旨在利用18个输入特征预测GW水平的带隙。在XML导出的个体特征重要性的指导下,提出了一个简单的框架来构建减少特征的预测模型。模型评估表明,由XML引导的紧凑模型(包含前五个特征)在域内数据集上实现了与原始模型相当的精度(0.254 vs. 0.247 eV),同时在域外数据上表现出更好的泛化能力和更低的预测误差(0.461 vs. 0.341 eV)。此外,该研究强调了在应用XML之前,必须消除强相关特征(相关系数大于0.8),以防止对特征重要性的误解和高估。这项研究强调了XML在开发简化但高度准确的机器学习模型方面的有效性,通过阐明特征作用,从而降低了特征获取的计算成本,并提高了材料发现的模型可信度。
🔬 方法详解
问题定义:论文旨在解决材料信息学中,非线性机器学习模型预测材料带隙时存在的黑盒问题。现有模型虽然精度高,但缺乏可解释性,且可能包含冗余特征,导致计算成本增加和泛化能力下降。
核心思路:论文的核心思路是利用可解释机器学习(XML)技术,分析原始模型中各个特征的重要性,然后筛选出最重要的特征,构建一个精简的模型。通过去除冗余特征,提高模型的泛化能力,并降低计算成本。
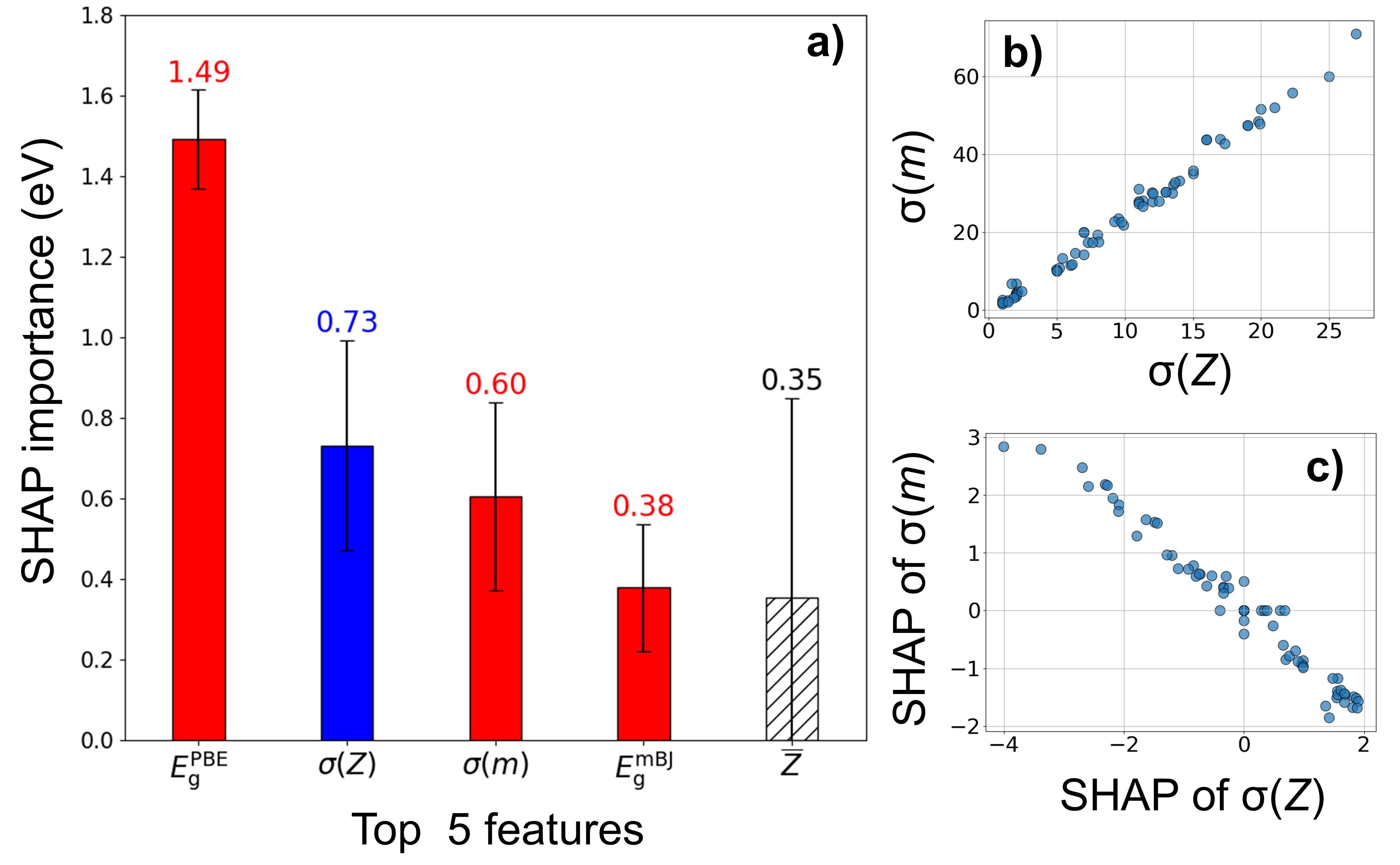
技术框架:该研究的技术框架主要包含以下几个阶段:1) 使用18个输入特征训练一个原始的支持向量回归(SVR)模型,用于预测GW水平的带隙。2) 应用XML技术,包括排列特征重要性和SHAP值,分析各个特征对模型预测结果的影响。3) 根据XML分析结果,筛选出最重要的前五个特征。4) 使用筛选出的特征重新训练一个精简的模型。5) 在域内和域外数据集上评估原始模型和精简模型的性能。
关键创新:该研究的关键创新在于将可解释机器学习技术应用于材料属性预测,并提出了一种基于特征重要性分析的特征选择方法。通过这种方法,可以构建一个精简且高性能的预测模型,同时提高模型的可解释性和泛化能力。此外,该研究还强调了在应用XML之前,需要消除强相关特征,以避免对特征重要性的误解。
关键设计:该研究的关键设计包括:1) 使用支持向量回归(SVR)作为基础预测模型。2) 使用排列特征重要性和SHAP值两种XML技术,综合评估特征的重要性。3) 设定相关系数阈值(0.8),用于消除强相关特征。4) 使用均方根误差(RMSE)作为模型性能的评估指标。
🖼️ 关键图片
📊 实验亮点
实验结果表明,由XML引导的紧凑模型(包含前五个特征)在域内数据集上实现了与原始模型相当的精度(0.254 vs. 0.247 eV)。更重要的是,在域外数据上,紧凑模型表现出更好的泛化能力,预测误差显著降低(0.461 vs. 0.341 eV)。这表明通过特征选择,可以有效提高模型的泛化性能。
🎯 应用场景
该研究成果可应用于材料科学领域,加速新材料的发现和设计。通过构建精简且可解释的带隙预测模型,可以降低材料筛选的计算成本,并提高模型的可信度,从而促进高性能材料的开发,例如用于太阳能电池、半导体器件等。
📄 摘要(原文)
In the rapidly advancing field of materials informatics, nonlinear machine learning models have demonstrated exceptional predictive capabilities for material properties. However, their black-box nature limits interpretability, and they may incorporate features that do not contribute to, or even deteriorate, model performance. This study employs explainable ML (XML) techniques, including permutation feature importance and the SHapley Additive exPlanation, applied to a pristine support vector regression model designed to predict band gaps at the GW level using 18 input features. Guided by XML-derived individual feature importance, a simple framework is proposed to construct reduced-feature predictive models. Model evaluations indicate that an XML-guided compact model, consisting of the top five features, achieves comparable accuracy to the pristine model on in-domain datasets (0.254 vs. 0.247 eV) while demonstrating superior generalization with lower prediction errors on out-of-domain data (0.461 vs. 0.341 eV). Additionally, the study underscores the necessity for eliminating strongly correlated features (correlation coefficient greater than 0.8) to prevent misinterpretation and overestimation of feature importance before applying XML. This study highlights XML's effectiveness in developing simplified yet highly accurate machine learning models by clarifying feature roles, thereby reducing computational costs for feature acquisition and enhancing model trustworthiness for materials discovery.