Large Language Models for Zero-shot Inference of Causal Structures in Biology
作者: Izzy Newsham, Luka Kovačević, Richard Moulange, Nan Rosemary Ke, Sach Mukherjee
分类: cs.LG, q-bio.GN
发布日期: 2025-03-06
备注: ICLR 2025 Workshop on Machine Learning for Genomics Explorations
💡 一句话要点
利用大型语言模型零样本推断生物学因果结构
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 因果推断 生物学 零样本学习 知识蒸馏
📋 核心要点
- 生物分子网络因果关系复杂,现有方法难以有效表征,面临潜在变量和细胞环境特异性等挑战。
- 利用大型语言模型(LLM)的知识,通过定制提示和检索增强,实现生物学因果关系的零样本推断。
- 实验表明,即使是较小的LLM,通过适当的增强和提示,也能捕捉生物系统因果结构的关键信息。
📝 摘要(中文)
基因、蛋白质和其他生物实体通过因果分子网络相互影响。这些网络中的因果关系由复杂多样的机制介导,通过潜在变量,并且通常特定于细胞环境。在实践中表征这些网络仍然具有挑战性。本文提出了一个新颖的框架,用于评估大型语言模型(LLM)在生物学中零样本推断因果关系的能力。特别地,我们使用真实世界的干预数据系统地评估从LLM获得的因果声明。这是在一百多个变量和数千个因果假设上完成的。此外,我们考虑了几种提示和检索增强策略,包括大型的、可能相互冲突的科学文章集合。我们的结果表明,通过定制的增强和提示,即使是相对较小的LLM也可以捕获生物系统中因果结构的有意义的方面。这支持了LLM可以作为生物学发现中的协调工具的观点,通过帮助提炼当前知识,使其适用于下游分析。我们评估LLM与实验数据的方法与因果学习、LLM和科学发现交叉领域中的广泛问题相关。
🔬 方法详解
问题定义:论文旨在解决生物学领域中因果关系推断的难题。现有的方法通常依赖于大量的实验数据和复杂的统计模型,计算成本高昂,并且难以处理潜在变量和细胞环境特异性等问题。因此,如何利用已有的生物学知识,高效准确地推断生物分子之间的因果关系,是一个重要的挑战。
核心思路:论文的核心思路是利用大型语言模型(LLM)中蕴含的丰富生物学知识,通过零样本学习的方式,直接从LLM中提取因果关系信息。这种方法无需大量的训练数据,可以快速地应用于不同的生物学问题。通过巧妙地设计提示(prompt),引导LLM生成包含因果关系的文本,然后对这些文本进行解析,从而得到因果关系推断的结果。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 构建生物学变量集合和因果假设;2) 设计合适的提示(prompt),输入到LLM中,引导LLM生成包含因果关系的文本;3) 对LLM生成的文本进行解析,提取因果关系信息;4) 使用真实世界的干预数据,对LLM推断的因果关系进行评估。其中,提示设计和检索增强是关键环节。
关键创新:该研究的关键创新在于将大型语言模型应用于生物学因果关系推断,并提出了一种零样本学习的框架。与传统的基于实验数据和统计模型的方法相比,该方法无需大量的训练数据,可以快速地应用于不同的生物学问题。此外,该研究还探索了不同的提示策略和检索增强方法,提高了LLM推断因果关系的准确性。
关键设计:在提示设计方面,论文探索了不同的提示模板,例如“X causes Y”等。在检索增强方面,论文使用了大量的科学文章,作为LLM的外部知识来源。此外,论文还考虑了不同大小的LLM,例如较小的LLM也可以通过适当的提示和检索增强,获得较好的性能。论文使用真实世界的干预数据来评估LLM推断的因果关系,例如基因敲除实验数据。
🖼️ 关键图片
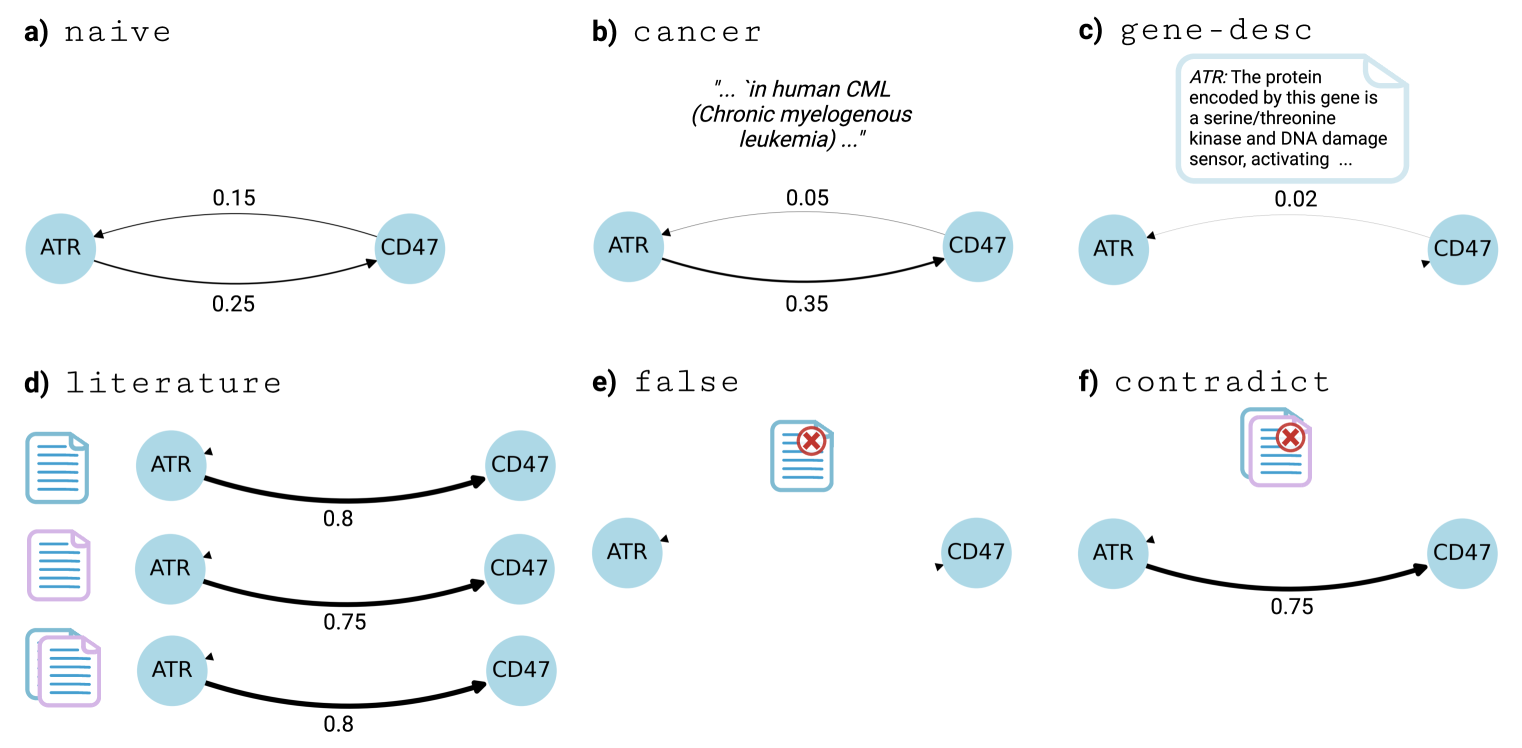
📊 实验亮点
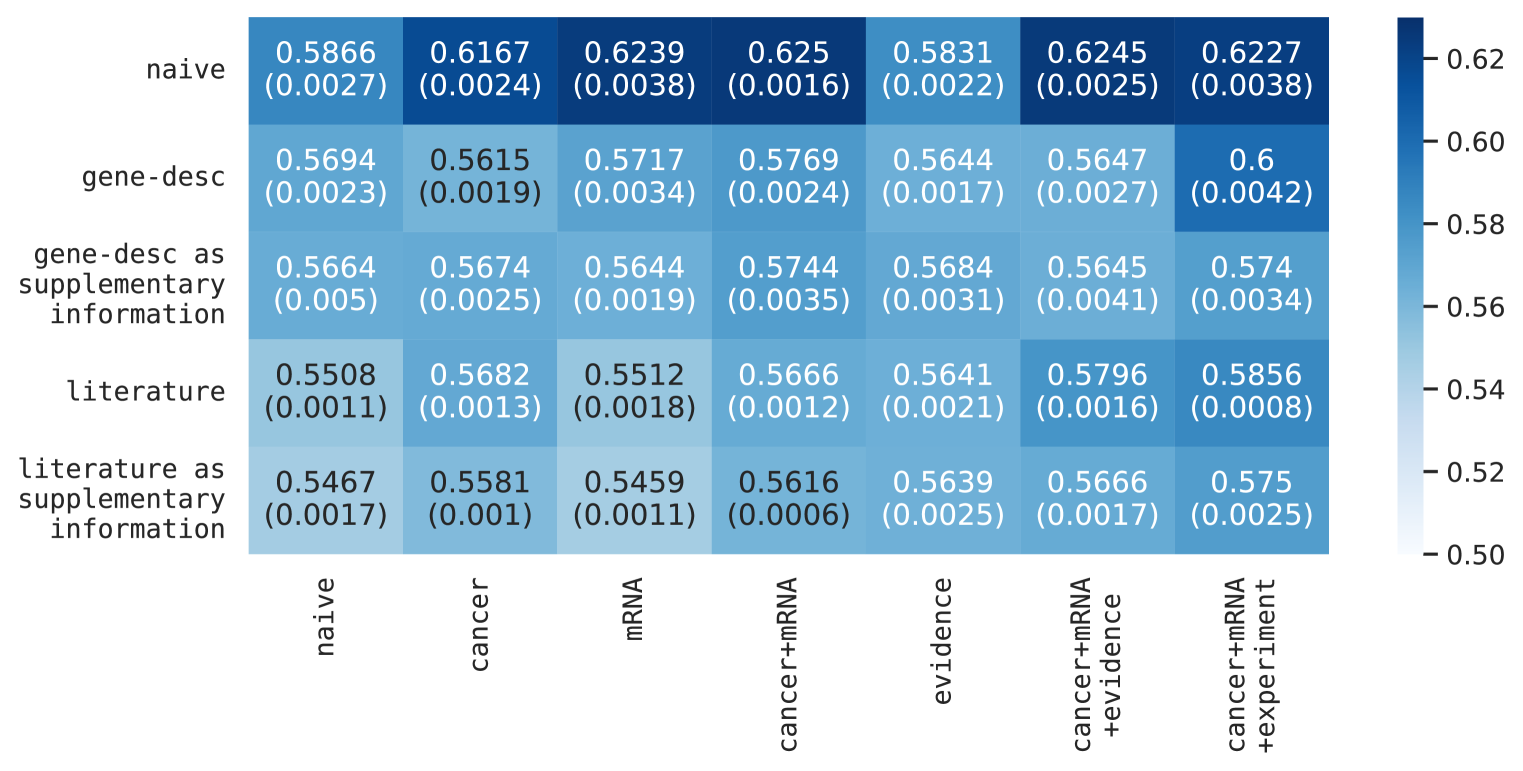
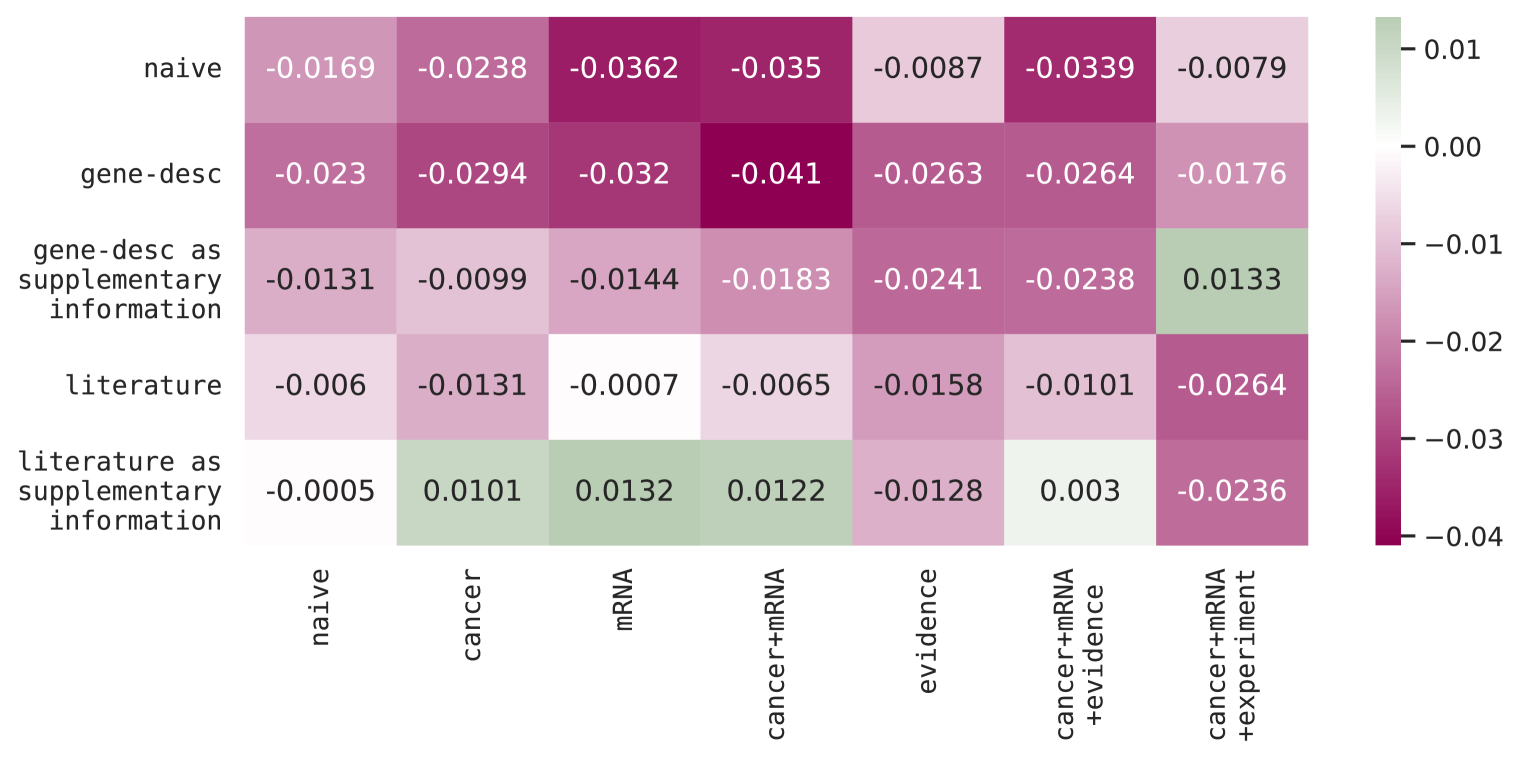
实验结果表明,通过定制的增强和提示,即使是相对较小的LLM也可以捕获生物系统中因果结构的有意义的方面。在超过一百个变量和数千个因果假设的评估中,该方法能够有效地从LLM中提取因果关系信息,并与真实世界的干预数据相吻合。这表明LLM在生物学因果关系推断方面具有巨大的潜力。
🎯 应用场景
该研究成果可应用于药物发现、疾病诊断和个性化医疗等领域。通过利用LLM快速推断生物分子之间的因果关系,可以加速药物靶点的识别和验证,提高疾病诊断的准确性,并为个性化医疗提供更精准的治疗方案。未来,该方法有望成为生物学研究的重要工具,促进生物学领域的快速发展。
📄 摘要(原文)
Genes, proteins and other biological entities influence one another via causal molecular networks. Causal relationships in such networks are mediated by complex and diverse mechanisms, through latent variables, and are often specific to cellular context. It remains challenging to characterise such networks in practice. Here, we present a novel framework to evaluate large language models (LLMs) for zero-shot inference of causal relationships in biology. In particular, we systematically evaluate causal claims obtained from an LLM using real-world interventional data. This is done over one hundred variables and thousands of causal hypotheses. Furthermore, we consider several prompting and retrieval-augmentation strategies, including large, and potentially conflicting, collections of scientific articles. Our results show that with tailored augmentation and prompting, even relatively small LLMs can capture meaningful aspects of causal structure in biological systems. This supports the notion that LLMs could act as orchestration tools in biological discovery, by helping to distil current knowledge in ways amenable to downstream analysis. Our approach to assessing LLMs with respect to experimental data is relevant for a broad range of problems at the intersection of causal learning, LLMs and scientific discovery.