How to Mitigate Overfitting in Weak-to-strong Generalization?
作者: Junhao Shi, Qinyuan Cheng, Zhaoye Fei, Yining Zheng, Qipeng Guo, Xipeng Qiu
分类: cs.LG, cs.AI
发布日期: 2025-03-06
💡 一句话要点
提出双阶段框架,提升弱监督到强泛化中的过拟合问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 弱到强泛化 过拟合 监督信号质量 问题质量 双阶段框架 大型语言模型 超对齐
📋 核心要点
- 现有弱到强泛化方法易使强模型对弱监督中的错误标签过拟合,且简单过滤错误标签会降低问题质量。
- 提出双阶段框架,同时提升监督信号质量和输入问题质量,从而缓解弱到强泛化中的过拟合问题。
- 实验结果表明,该框架在多个大型语言模型和数学基准上显著提高了PGR,部分模型上甚至达到100%。
📝 摘要(中文)
在超越人类评估能力的任务上对齐强大的AI模型是超对齐的核心问题。为了解决这个问题,弱到强泛化旨在通过弱监督者来激发强模型的能力,并确保强模型的行为与弱监督者的意图对齐,避免欺骗等不安全行为。尽管弱到强泛化表现出一定的泛化能力,但强模型在其中表现出显著的过拟合:由于强模型的强大拟合能力,来自弱监督者的错误标签可能导致强模型过拟合。此外,简单地过滤掉不正确的标签可能会导致问题质量下降,从而导致强模型在难题上的泛化能力较弱。为了缓解弱到强泛化中的过拟合,我们提出了一个双阶段框架,该框架同时提高了监督信号的质量和输入问题的质量。在三个系列的大型语言模型和两个数学基准上的实验结果表明,与朴素的弱到强泛化相比,我们的框架显著提高了PGR,甚至在某些模型上达到了100%的PGR。
🔬 方法详解
问题定义:论文旨在解决弱到强泛化过程中强模型容易对弱监督信号中的噪声标签产生过拟合的问题。现有方法,例如直接使用弱监督信号训练强模型,会导致强模型学习到错误的模式。而简单地过滤掉噪声标签又会降低训练数据的质量,特别是难题的质量,从而限制了强模型在难题上的泛化能力。
核心思路:论文的核心思路是同时提升监督信号的质量和输入问题的质量。通过提升监督信号质量,减少强模型学习到错误模式的可能性。通过提升输入问题质量,保证强模型能够学习到更具泛化性的知识,从而缓解过拟合问题。
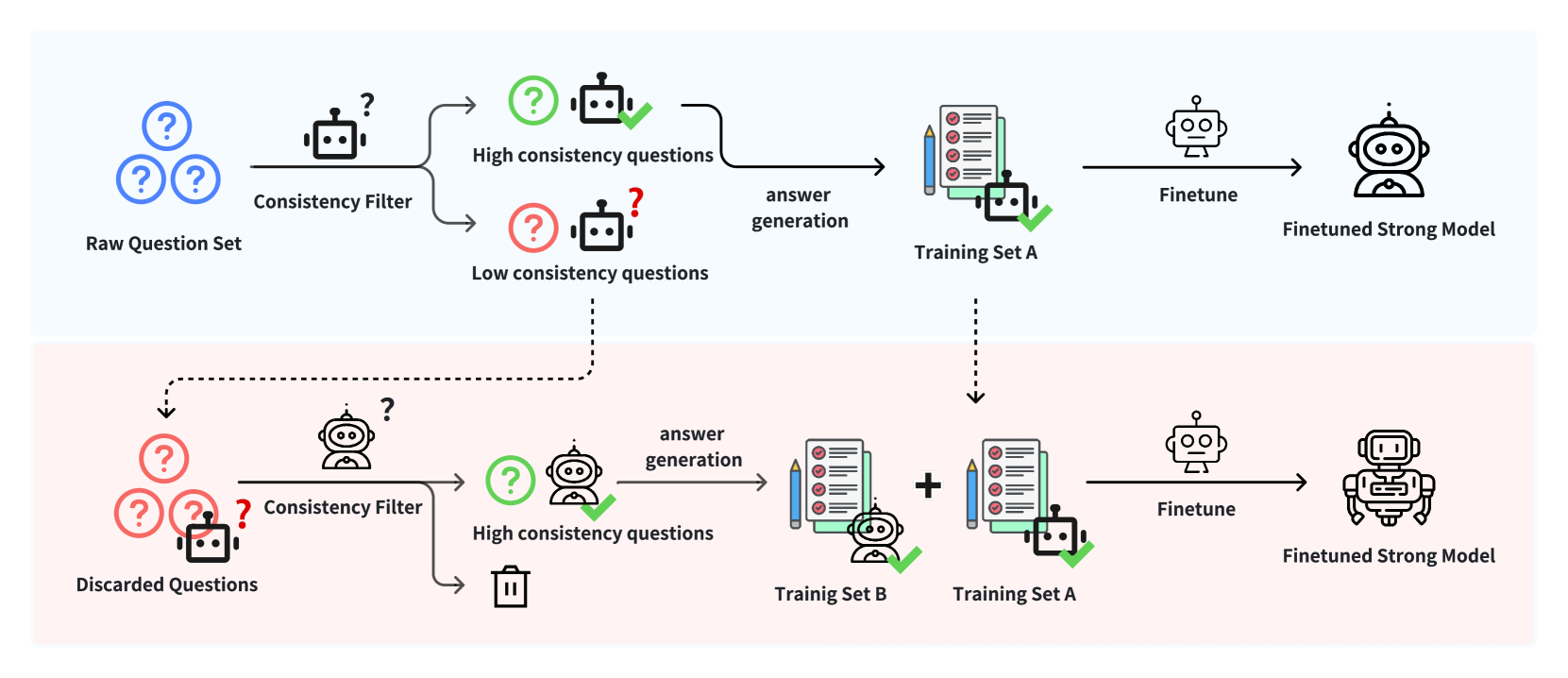
技术框架:论文提出了一个双阶段框架。第一阶段,提升监督信号质量,例如通过某种方式对弱监督信号进行清洗或修正。第二阶段,提升输入问题质量,例如通过某种方式生成更具挑战性或更具代表性的问题。这两个阶段可以迭代进行,从而逐步提升模型的性能。
关键创新:该论文的关键创新在于提出了一个同时关注监督信号质量和输入问题质量的双阶段框架,从而更全面地解决了弱到强泛化中的过拟合问题。与以往只关注数据清洗或只关注模型设计的思路不同,该框架将数据和模型优化结合起来,从而取得了更好的效果。
关键设计:具体的技术细节(例如,如何清洗弱监督信号,如何生成高质量的问题)取决于具体的应用场景和数据集。论文中可能使用了特定的参数设置、损失函数或网络结构来优化模型的性能。这些细节需要根据具体的实验设置进行调整。
🖼️ 关键图片

📊 实验亮点
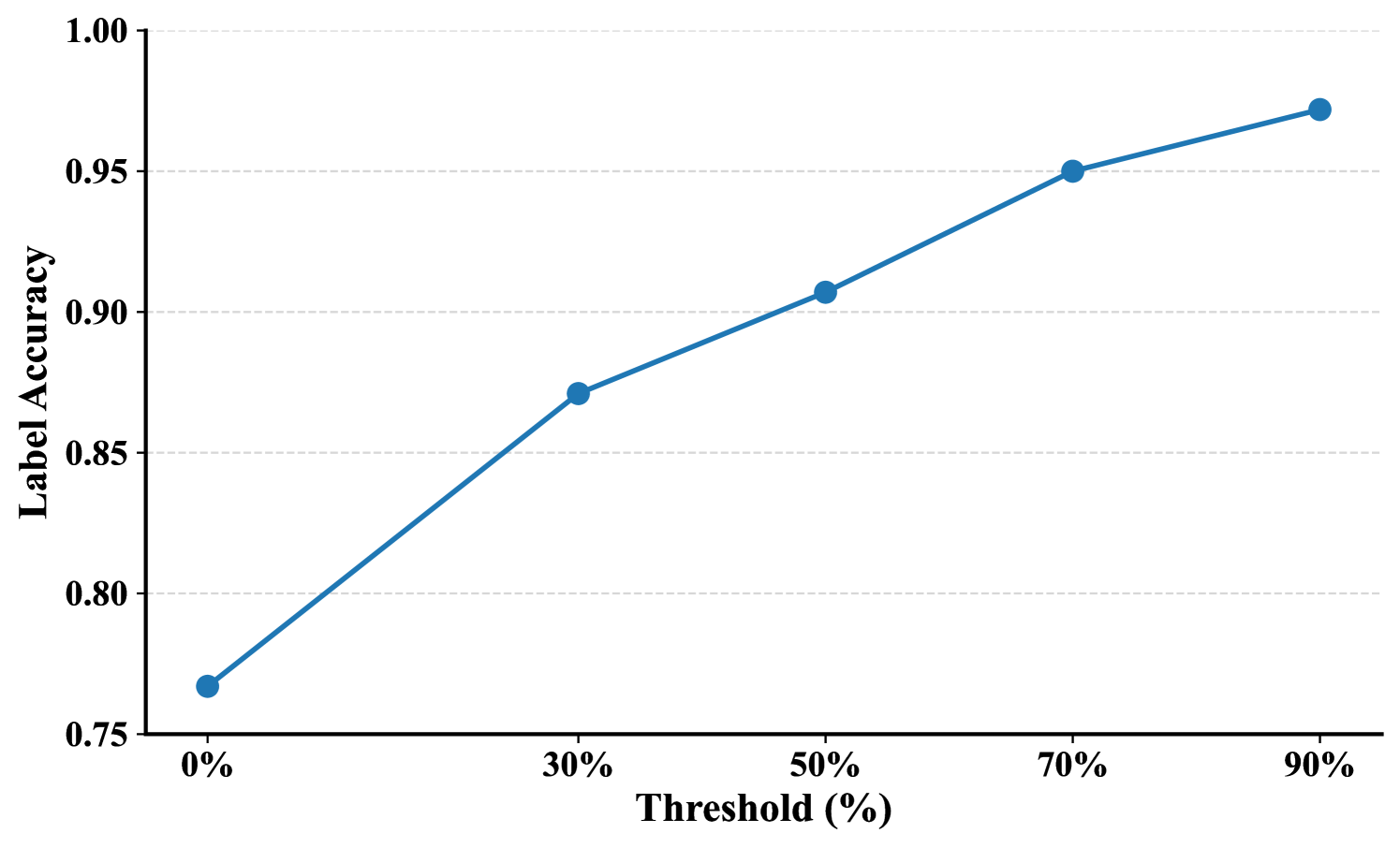
实验结果表明,该框架在三个系列的大型语言模型和两个数学基准上显著提高了PGR(Pass@k Rate),与朴素的弱到强泛化相比,性能提升显著,甚至在某些模型上达到了100%的PGR。这表明该框架能够有效地缓解弱到强泛化中的过拟合问题,并提升模型的泛化能力。
🎯 应用场景
该研究成果可应用于各种需要利用弱监督信号训练强大AI模型的场景,例如自动驾驶、医疗诊断、金融风控等。通过缓解弱到强泛化中的过拟合问题,可以提高AI模型的可靠性和安全性,从而使其能够更好地服务于人类社会。未来的研究可以探索更有效的监督信号清洗和问题生成方法,进一步提升模型的性能。
📄 摘要(原文)
Aligning powerful AI models on tasks that surpass human evaluation capabilities is the central problem of \textbf{superalignment}. To address this problem, weak-to-strong generalization aims to elicit the capabilities of strong models through weak supervisors and ensure that the behavior of strong models aligns with the intentions of weak supervisors without unsafe behaviors such as deception. Although weak-to-strong generalization exhibiting certain generalization capabilities, strong models exhibit significant overfitting in weak-to-strong generalization: Due to the strong fit ability of strong models, erroneous labels from weak supervisors may lead to overfitting in strong models. In addition, simply filtering out incorrect labels may lead to a degeneration in question quality, resulting in a weak generalization ability of strong models on hard questions. To mitigate overfitting in weak-to-strong generalization, we propose a two-stage framework that simultaneously improves the quality of supervision signals and the quality of input questions. Experimental results in three series of large language models and two mathematical benchmarks demonstrate that our framework significantly improves PGR compared to naive weak-to-strong generalization, even achieving up to 100\% PGR on some models.